How Predictable Is Language Model Benchmark Performance?
We investigate large language model performance across five orders of magnitude of compute scaling, finding that compute-focused extrapolations are a promising way to forecast AI capabilities.
Resources
Executive summary
- We investigate large language model performance across five orders of magnitude of compute scaling in 11 recent model architectures at 36 different model sizes.
- We present data on performance in BIG-Bench and MMLU, covering a range of model sizes and architectures.
- We examine trends in performance, showing a fairly smooth relationship between overall performance and scale, consistent with an S-curve.
- We outline an approach for predicting benchmark performance based on compute scaling.
- We back-test predictability of aggregate benchmark performance using this approach, showing that performance is moderately predictable from compute scaling.
- We show that individual benchmark tasks are less predictable, but remain more predictable than chance or a simple per-task average baseline.
- We conclude that compute-based extrapolations are a promising way to forecast AI capabilities.
Background
Scaling laws allow prediction of a model’s loss from model and dataset sizes. However, scaling does not directly predict a model’s performance on downstream tasks - as assessed through benchmarks. To bridge this gap, we build on pre-existing methods and fit model performance against scaling laws. We then use back-testing to evaluate how well these fits can predict benchmark performance.
First, we use scaling laws to map models to loss according to model size, N, and dataset size, D. Loss can equivalently be expressed in terms of scaled compute - the compute required to achieve this loss under optimal scaling of N and D. This allows every model in our dataset to be associated with its scaled compute, as shown in Figure 1.
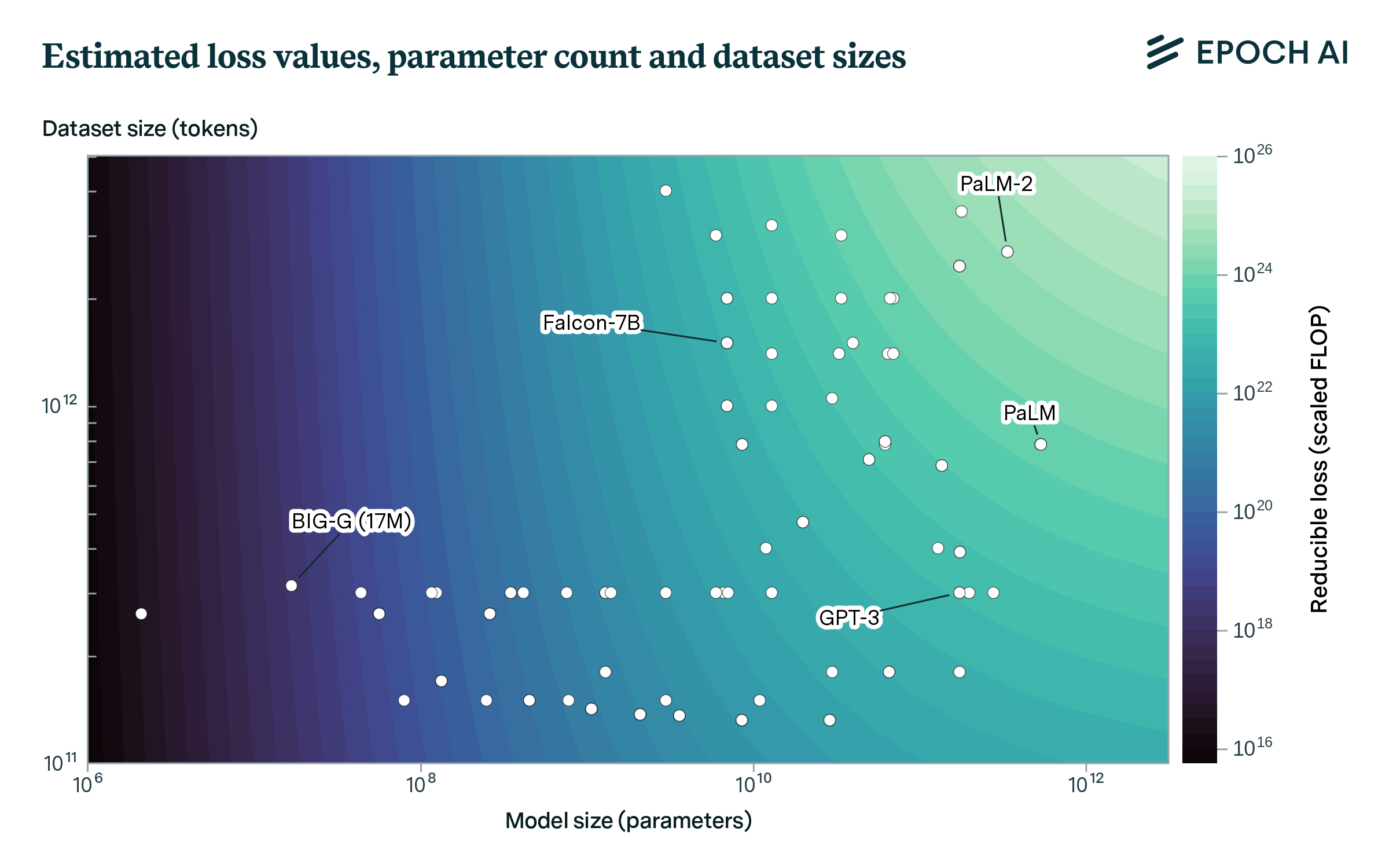
Figure 1: Different estimated loss values against model and training set sizes, for all models considered in this report. Loss is also expressed in terms of optimally scaled compute.
Subsequently, we fit curves relating benchmark performance to loss. This leads to fits like those in Figure 2, predicting performance from loss (expressed as scaled compute). We favor simple forms with few parameters throughout this work, as we typically have small datasets on the order of tens of datapoints per task. To evaluate predictability, we perform back-tests: we hold out points to the right of the loss-performance curves when fitting, and then assess error in the predictions. We investigate fits for aggregate benchmark performance and individual benchmark tasks.
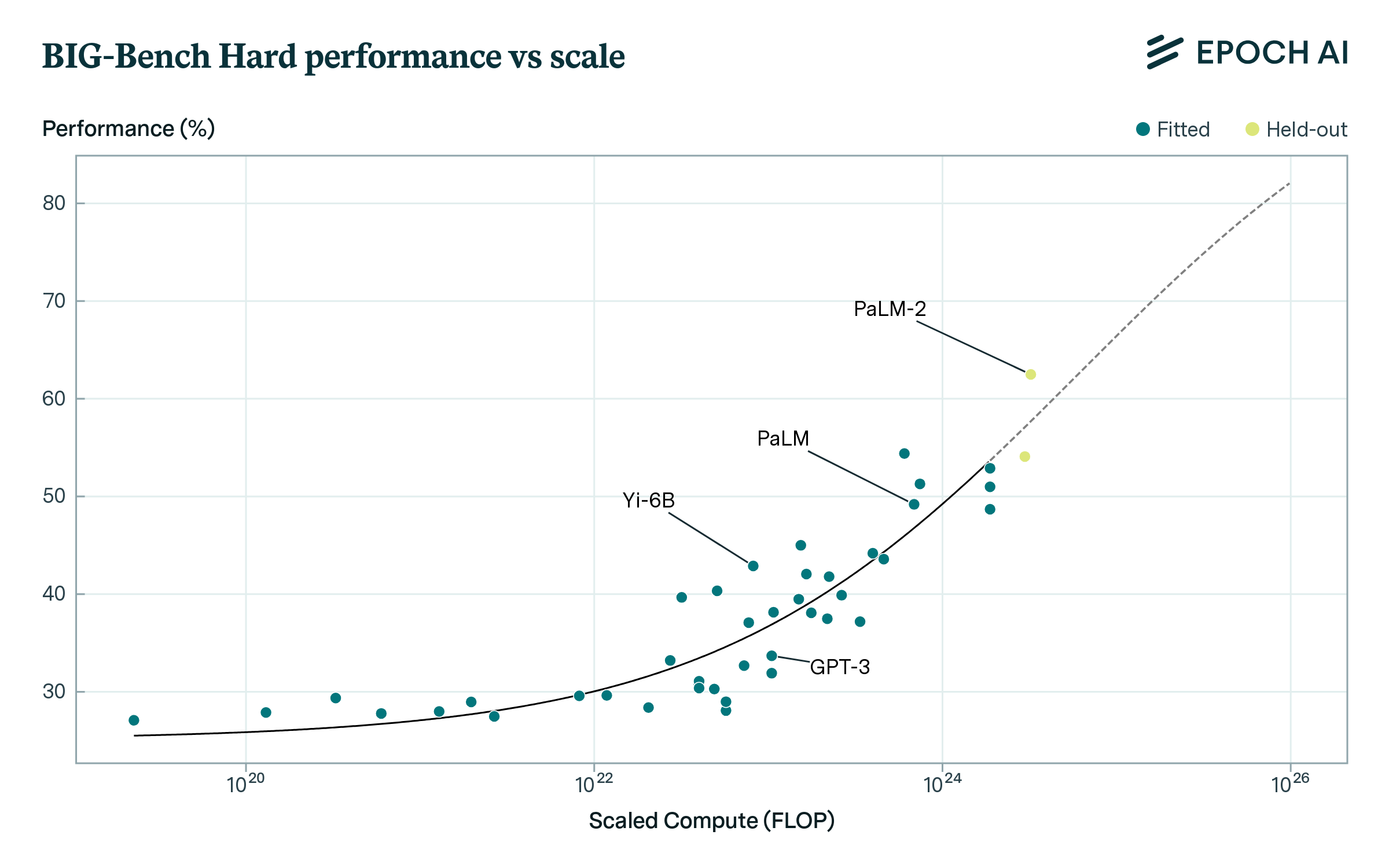
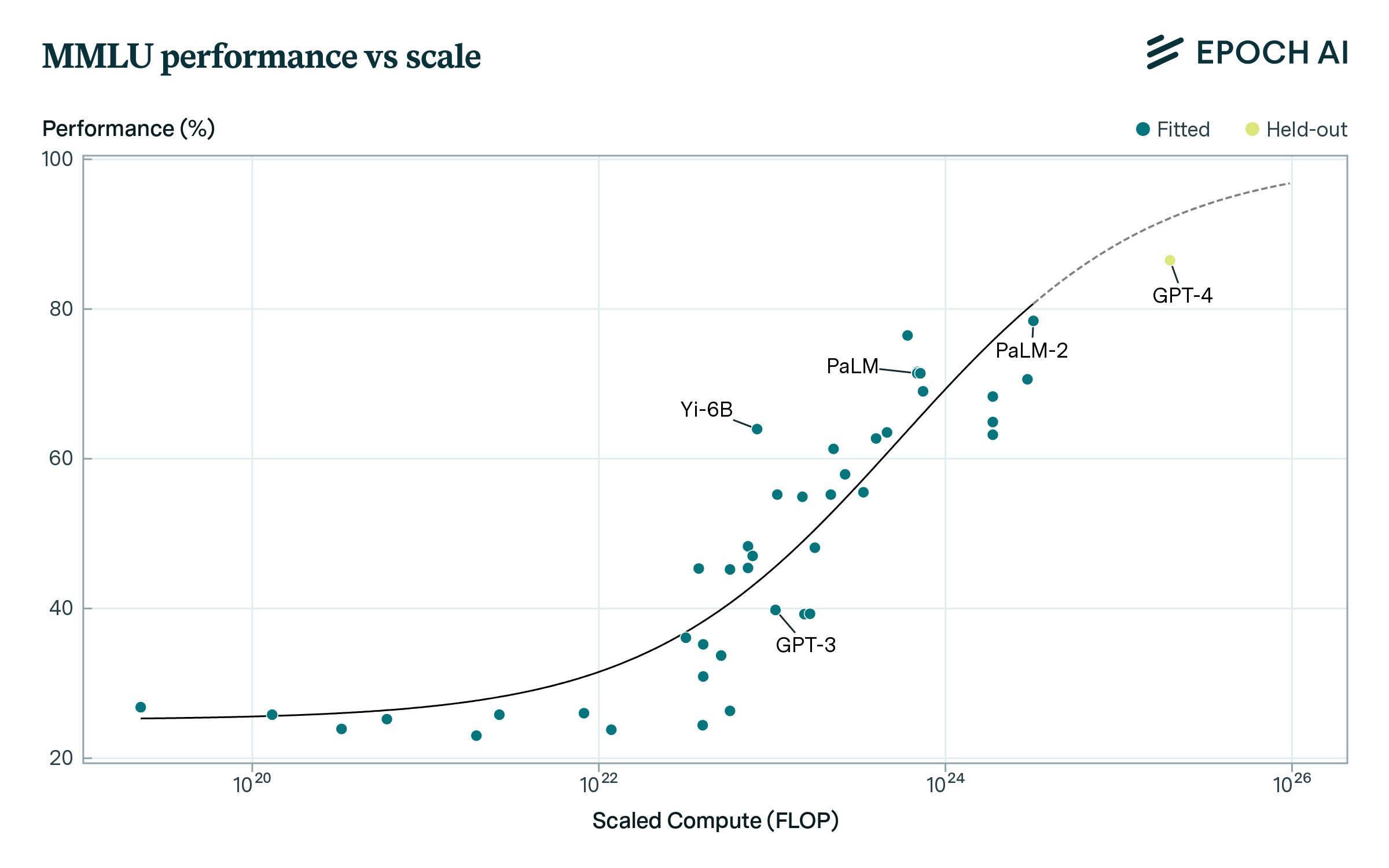
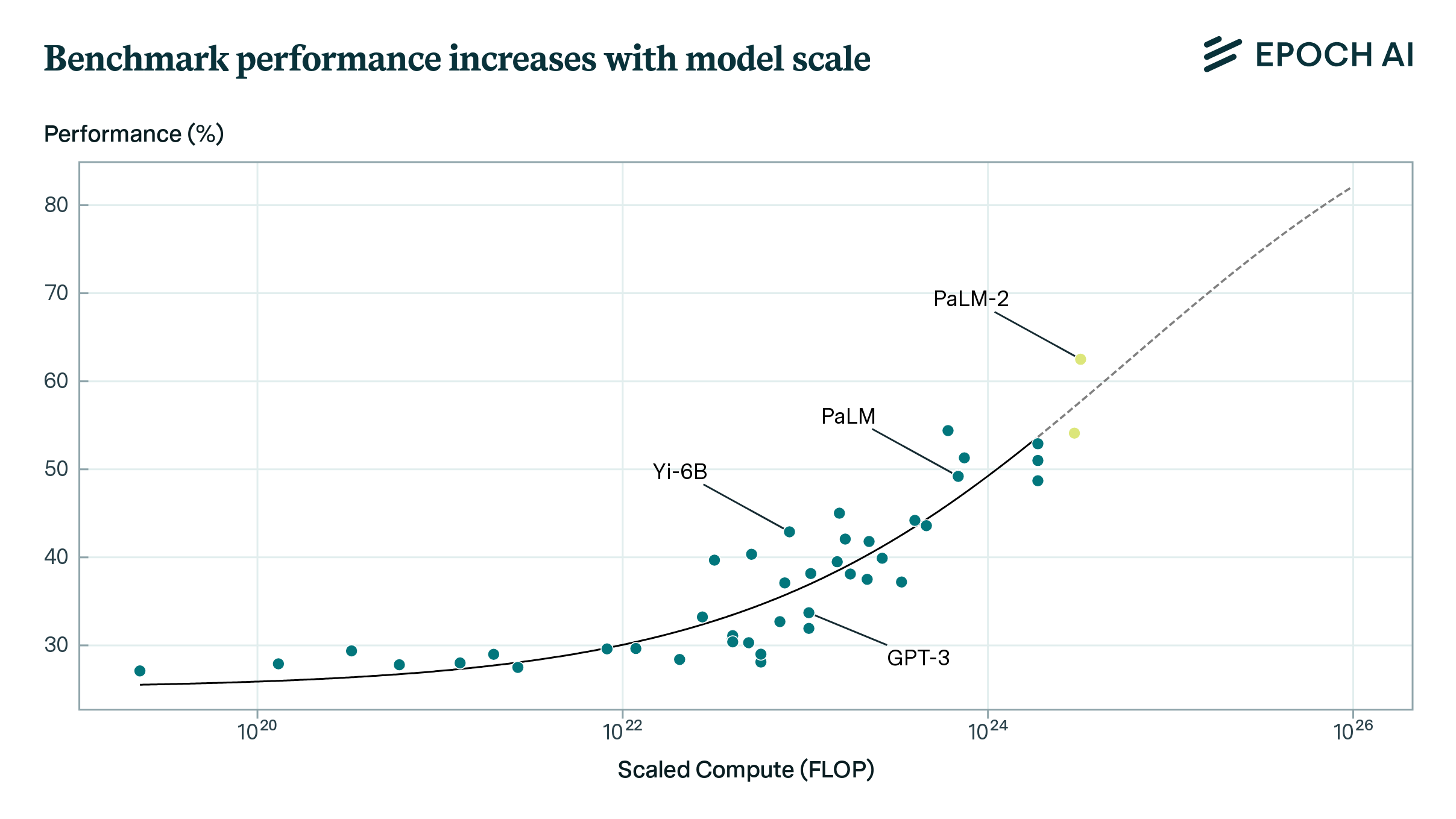
Figure 2: Aggregate benchmark performance for BIG-Bench Hard and MMLU is fairly predictable from compute scaling. Sigmoid fits are shown in black for both plots, with bold lines showing data used for fitting and dashed lines showing extrapolation.
Results
Aggregate benchmark performance is fairly predictable from scaling, as shown in Figure 2. Using a sigmoid fit to predict across an OOM of scaling, mean absolute error is 6 percentage points (pp). Prediction requires some pre-existing progress: steep increases in performance make it difficult to predict far ahead using only data from low-performing models. Error gradually increases as one extrapolates further ahead, as shown in Figure 3. If current trends persist, our extrapolation suggests BIG-Bench could exceed human-level performance (80%) around 6e25 FLOP scaled compute, with ~90% chance of reaching this level by 5e26 FLOP.
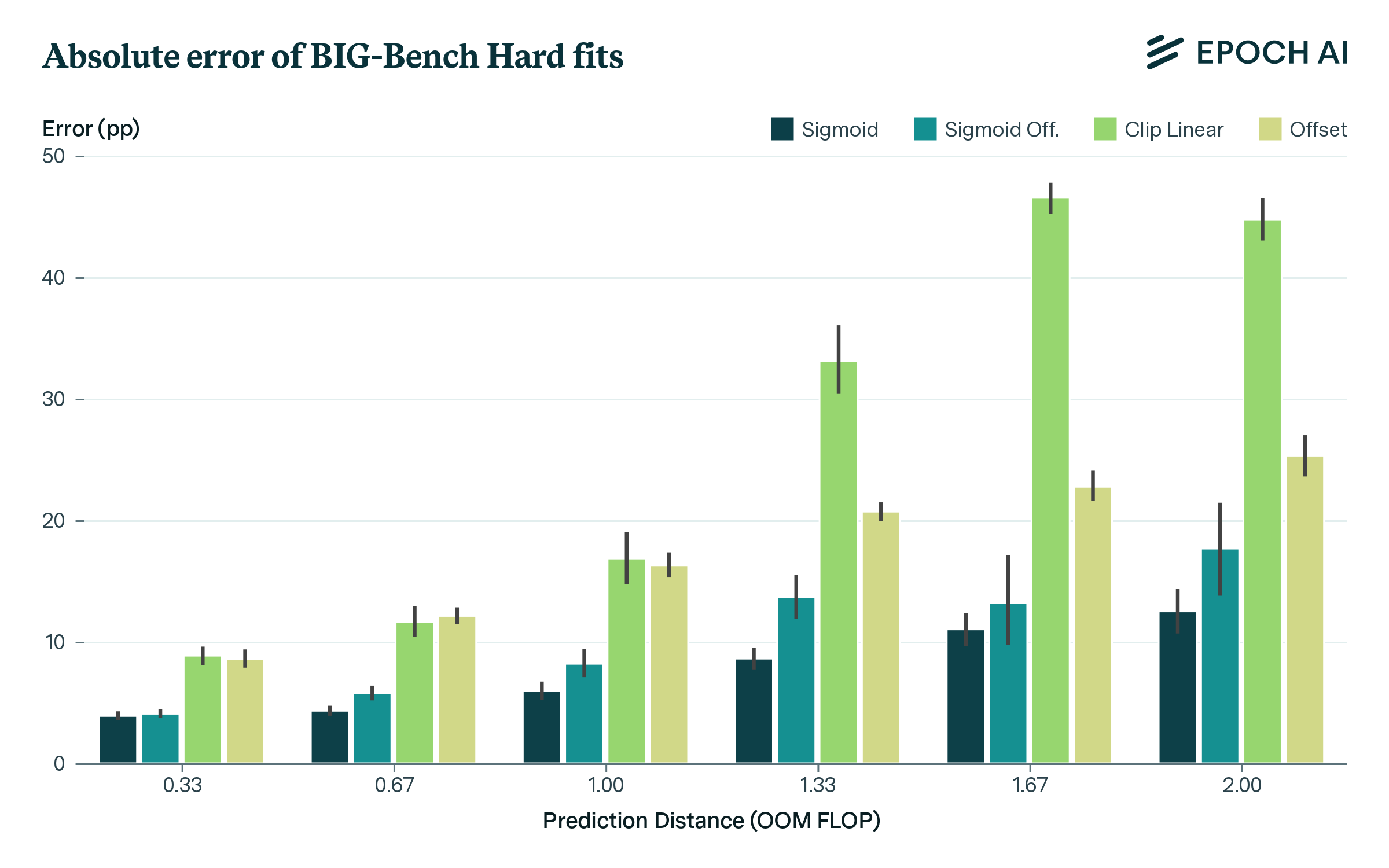
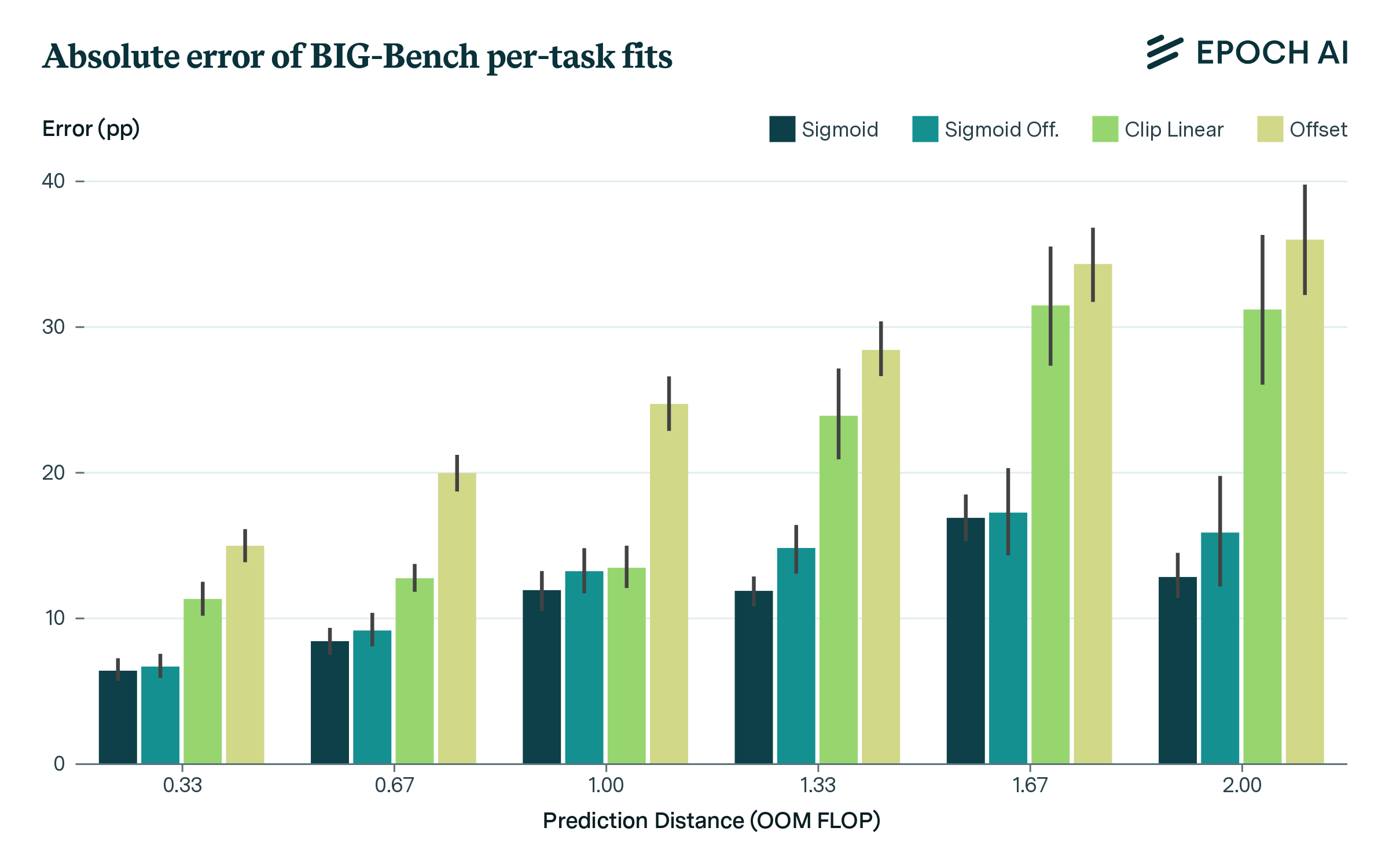
Figure 3: Absolute error versus how far ahead performance is extrapolated, for different fits. Errors are evaluated over the entire series of held out points, bars show 90% confidence intervals.
Individual tasks are highly variable in their scaling, and the sharp emergence of capabilities can make it difficult to predict performance. Figure 4 shows qualitative examples - ranging from well-predicted tasks to those where scaling clearly deviates from a sigmoid. Nevertheless, performance on individual benchmark tasks is significantly more predictable than chance or a simple baseline, as shown in Figure 3. The distribution of errors across tasks is fat-tailed: over half of tasks can be predicted with less than 10% error, but some tasks have substantially higher error, particularly tasks using multiple choice as their preferred metric (discussed in more detail within the full report). Figure 4 also illustrates why previous analyses that examined a small number of models found performance was unpredictable from scaling, whereas a larger data series shows significant (but imperfect) predictability.
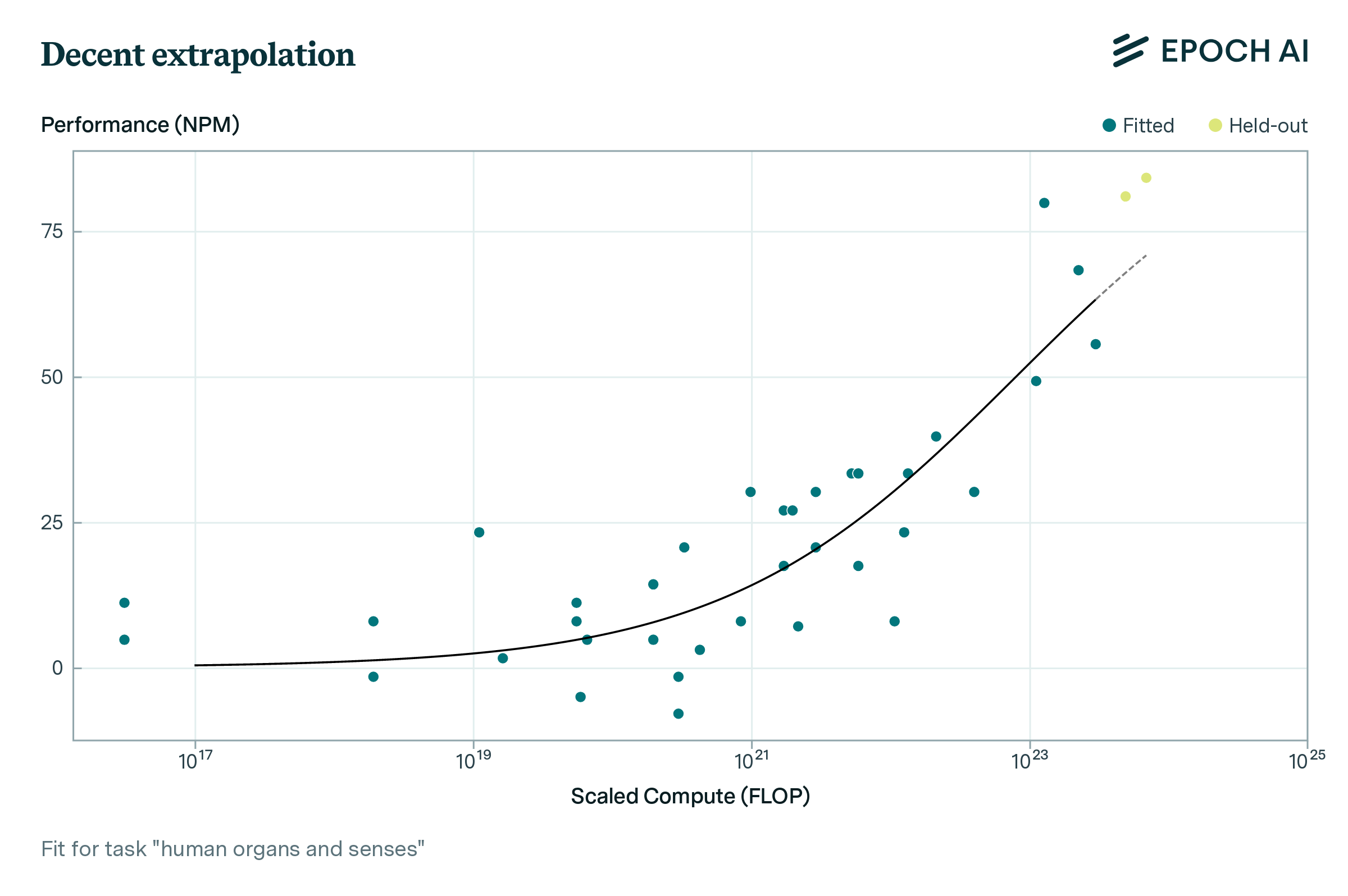
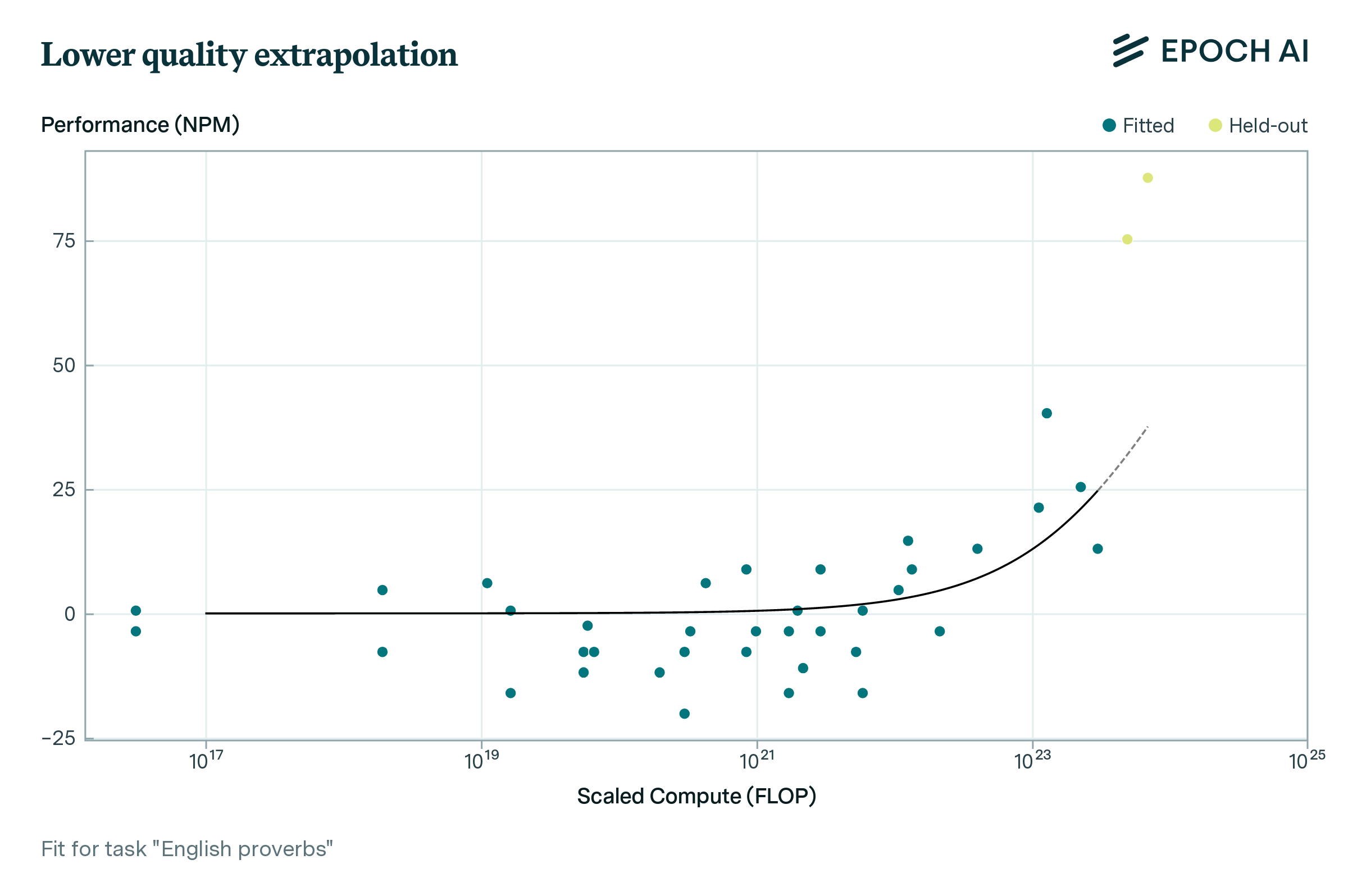
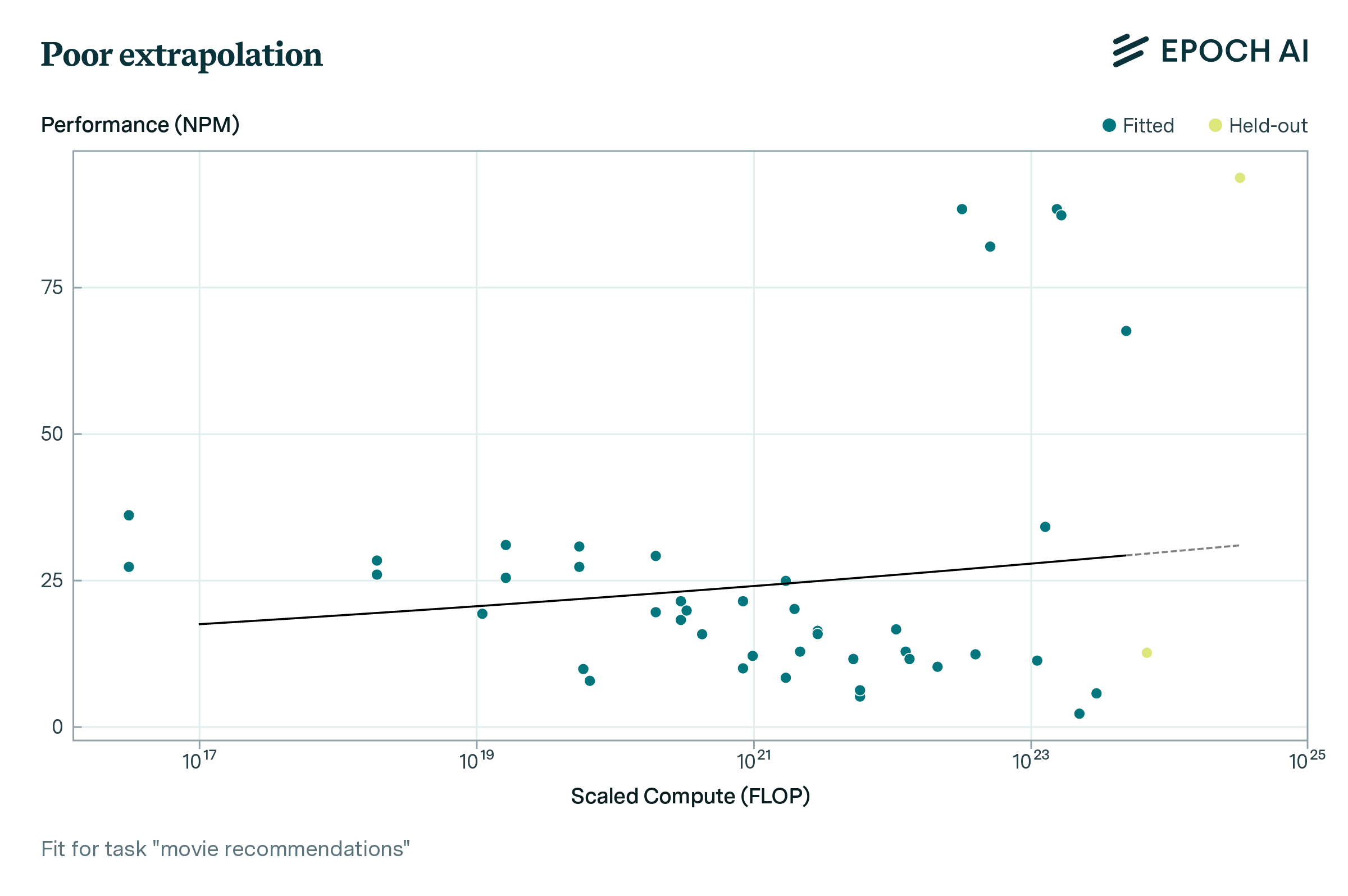
Figure 4: There is a lot of variation in per-task fit quality. Example data and back-tested model fits for three BIG-Bench tasks showing performance versus loss (scaled compute).
In conclusion, our results show that language benchmarks are fairly predictable from scaling, although prediction requires some pre-existing progress: steep increases in performance make it difficult to predict far ahead using only data from poorly-performing models. Furthermore, aggregate benchmarks are more predictable than individual tasks - for example comparing BIG-Bench Hard and individual BIG-Bench tasks. This supports the idea that higher-level model capabilities are predictable with scale, and gives support to a scaling-focused view of AI development. We hope that methods of this sort may eventually provide useful forecasts for guiding research and policy.
Updates
We extended the dataset with several additional models and re-ran the analysis, updating results and figures. We also modified the analysis to consider prediction distances in FLOP rather than number of held-out points.
About the authors

Related posts