

Articles
All articles
announcement
· 1 min read
Introducing Epoch AI’s Machine Learning Hardware Database
Our new database covers hardware used to train AI models, featuring over 100 accelerators (GPUs and TPUs) across the deep learning era.
report
· 10 min read
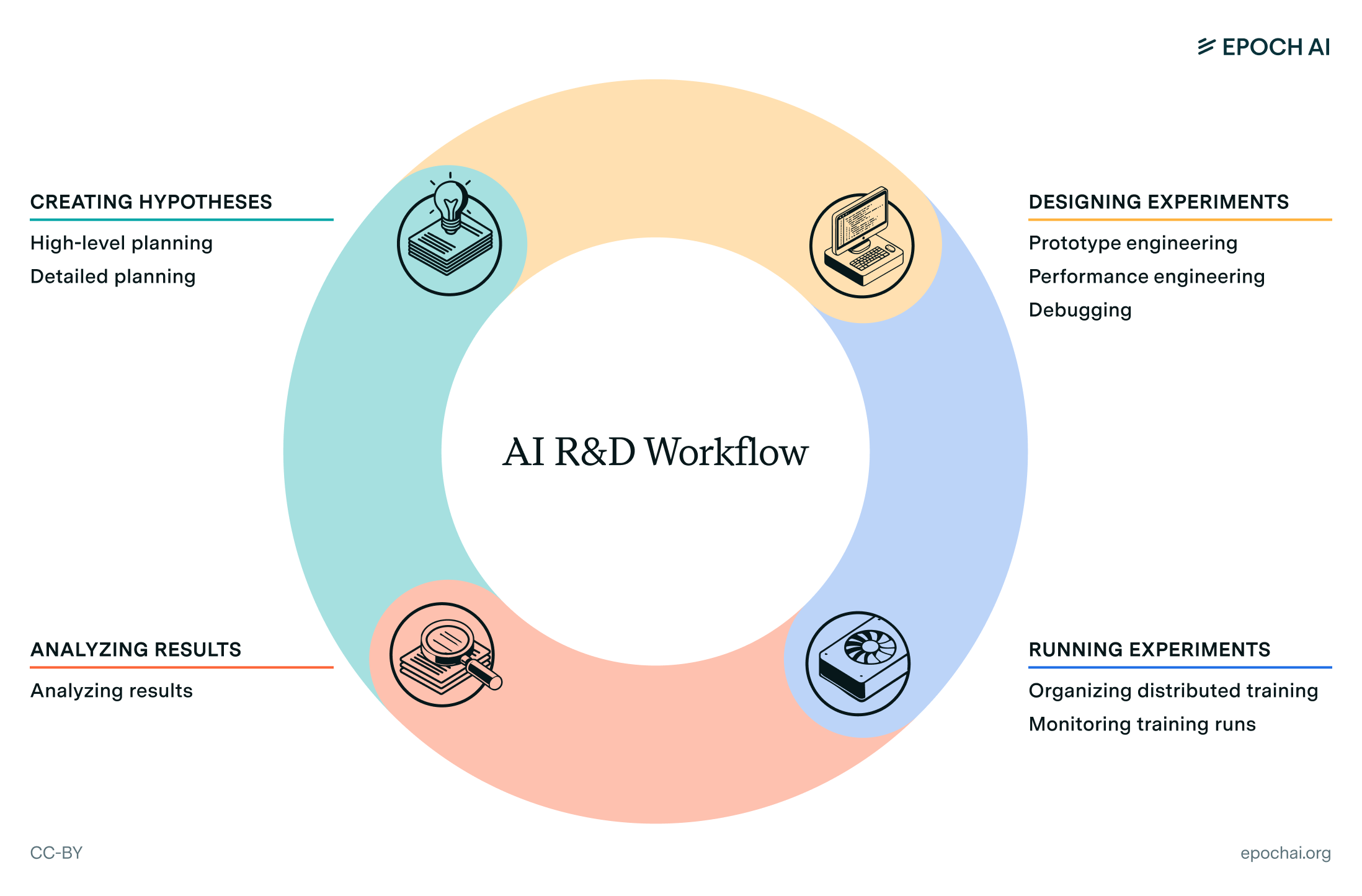
Interviewing AI researchers on automation of AI R&D
AI could accelerate AI R&D, especially in coding and debugging tasks. We explore AI researchers’ differing predictions on automation, and their suggestions for designing AI R&D evaluations.
report
· 83 min read
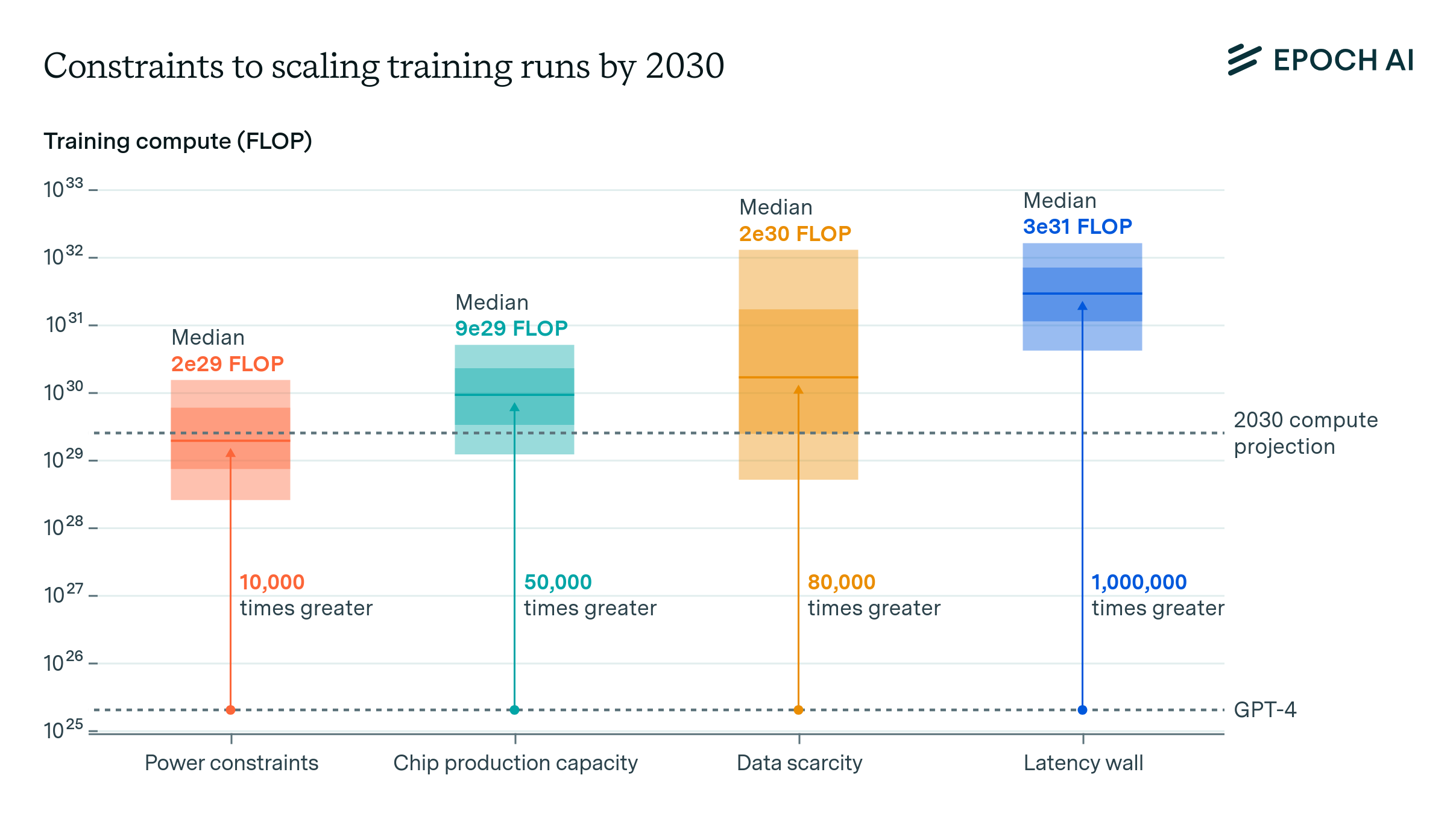
Can AI Scaling Continue Through 2030?
We investigate the scalability of AI training runs. We identify electric power, chip manufacturing, data and latency as constraints. We conclude that 2e29 FLOP training runs will likely be feasible by 2030.
announcement
· 1 min read
Announcing Epoch AI’s Data Hub
We are launching a hub for data and visualizations, to make our databases more accessible for users and researchers. It currently features our data on notable and large-scale AI models.
paper
· 6 min read
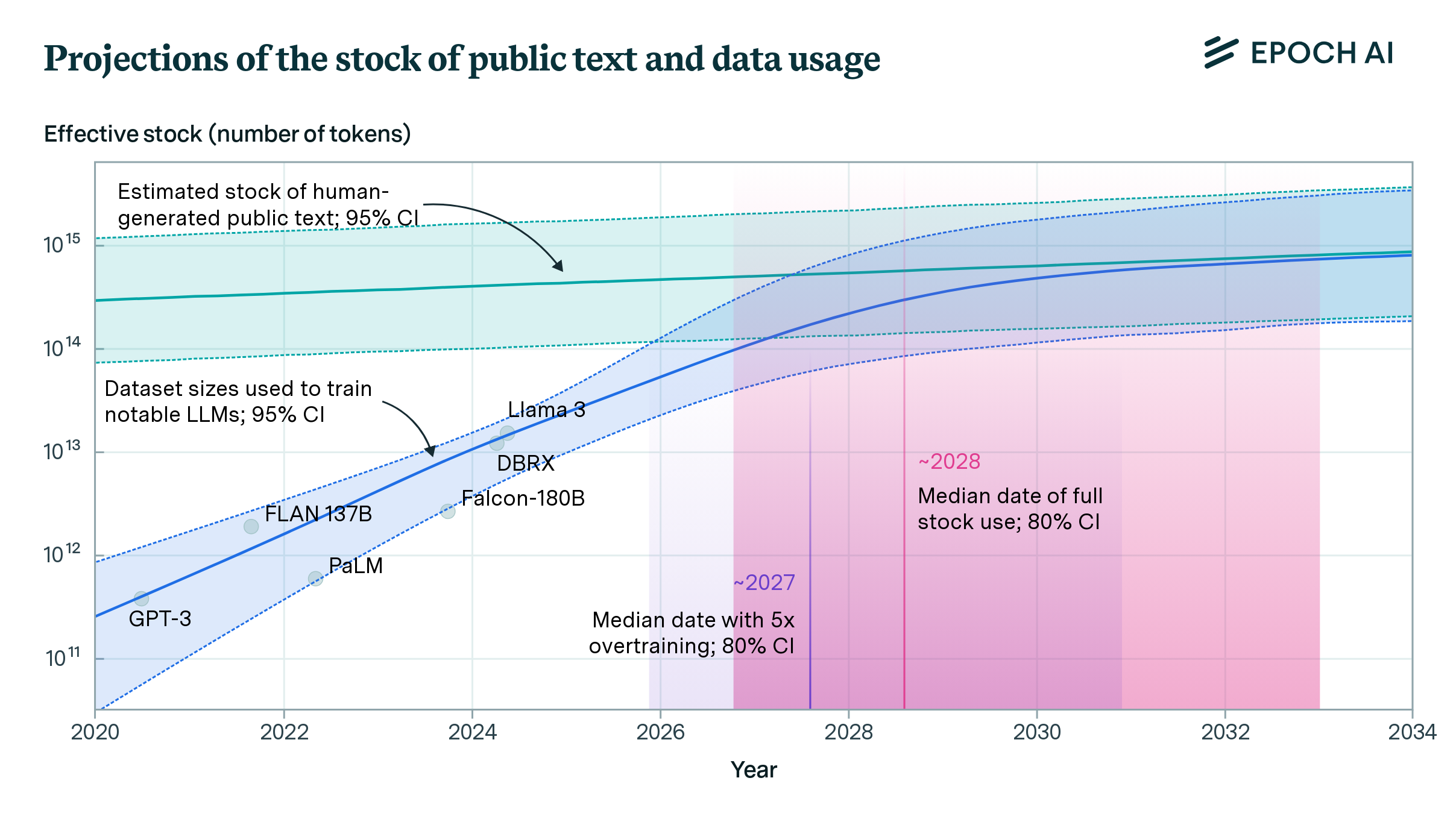
Will We Run Out of Data? Limits of LLM Scaling Based on Human-Generated Data
We estimate the stock of human-generated public text at around 300 trillion tokens. If trends continue, language models will fully utilize this stock between 2026 and 2032, or even earlier if intensely overtrained.
paper
· 4 min read
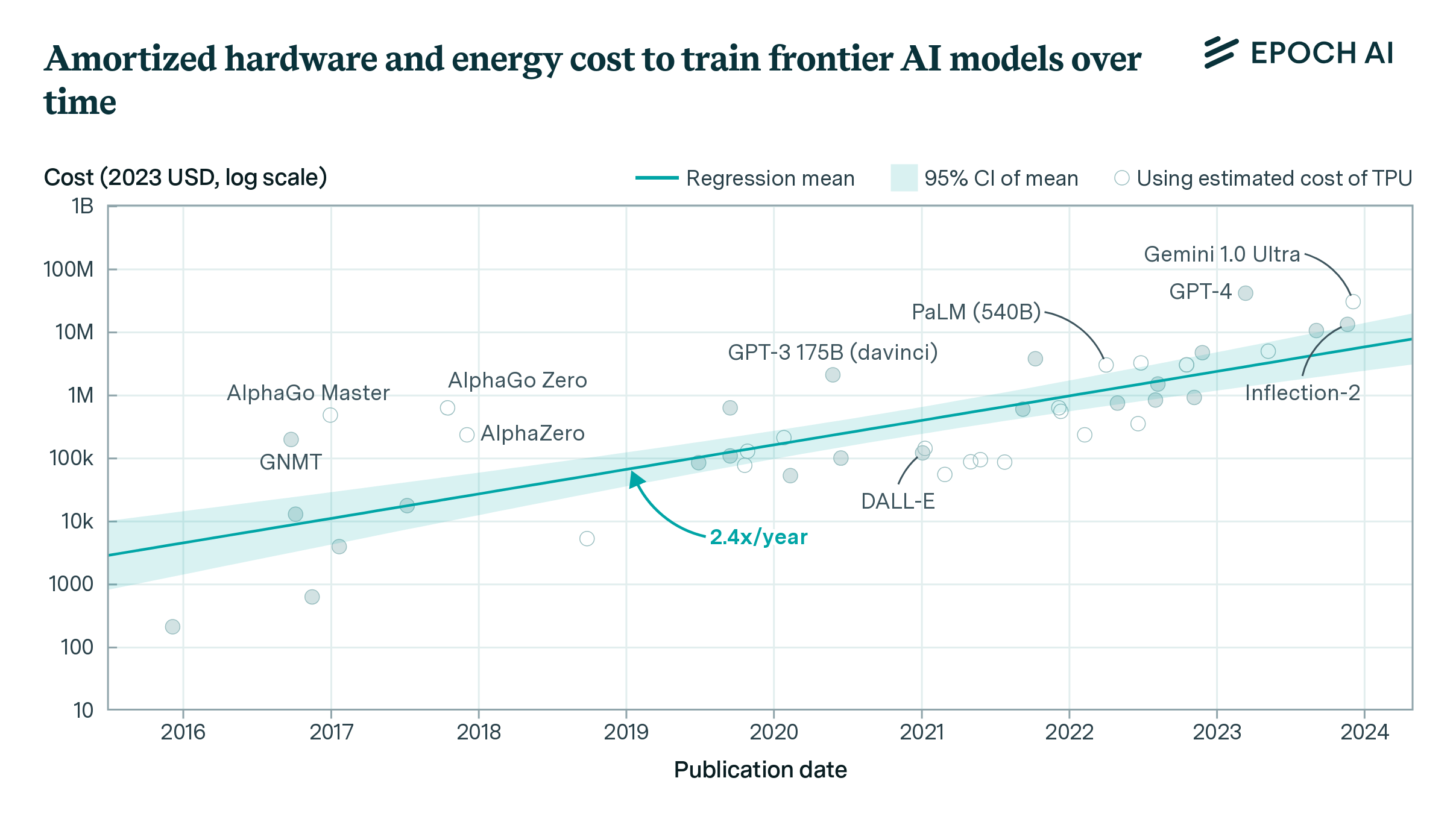
How Much Does It Cost to Train Frontier AI Models?
The cost of training frontier AI models has grown by a factor of 2 to 3x per year for the past eight years, suggesting that the largest models will cost over a billion dollars by 2027.

report
· 20 min read
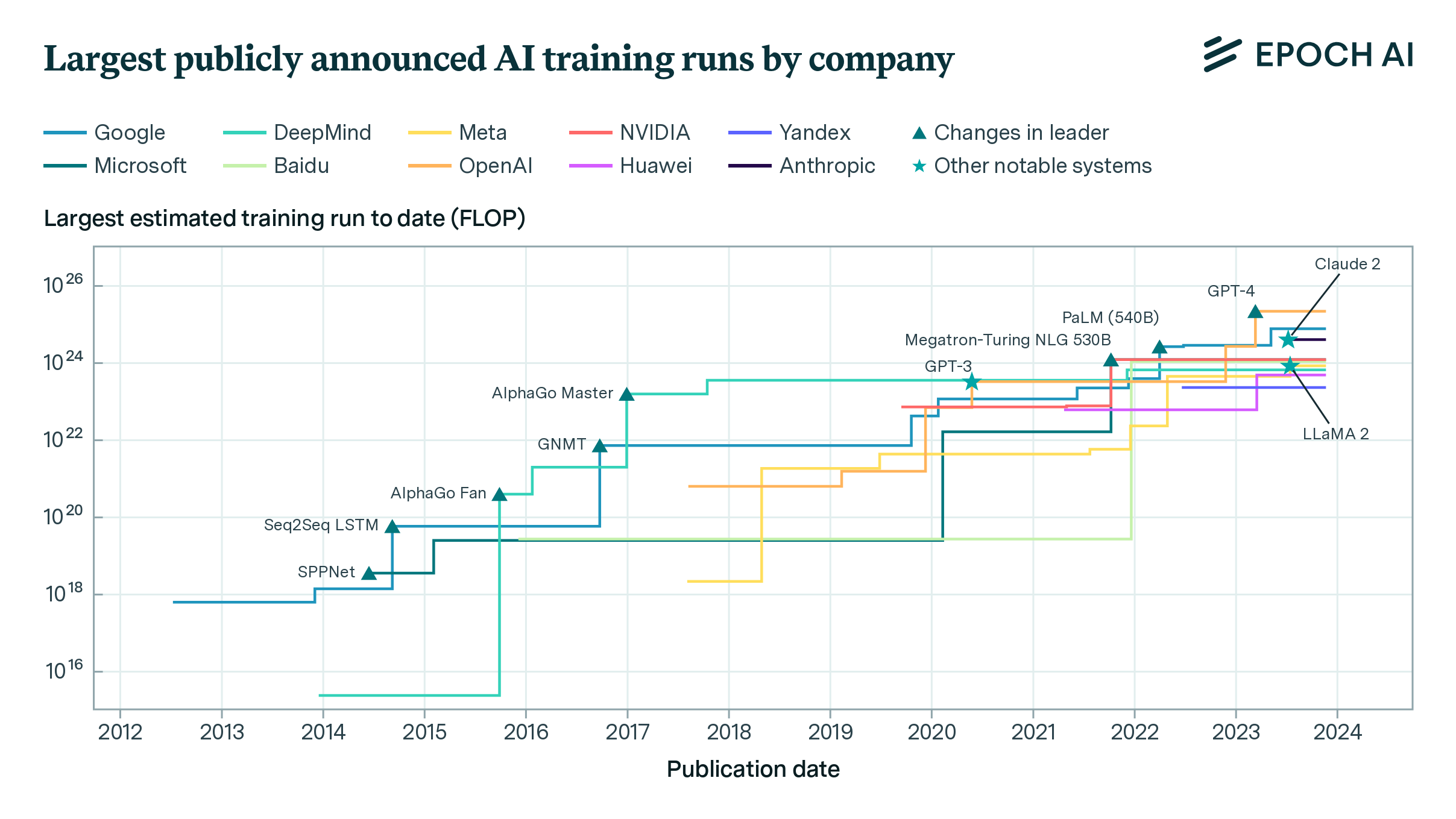
Training Compute of Frontier AI Models Grows by 4-5x per Year
Our expanded AI model database shows that the compute used to train recent models grew 4-5x yearly from 2010 to May 2024. We find similar growth in frontier models, recent large language models, and models from leading companies.
paper
· 10 min read
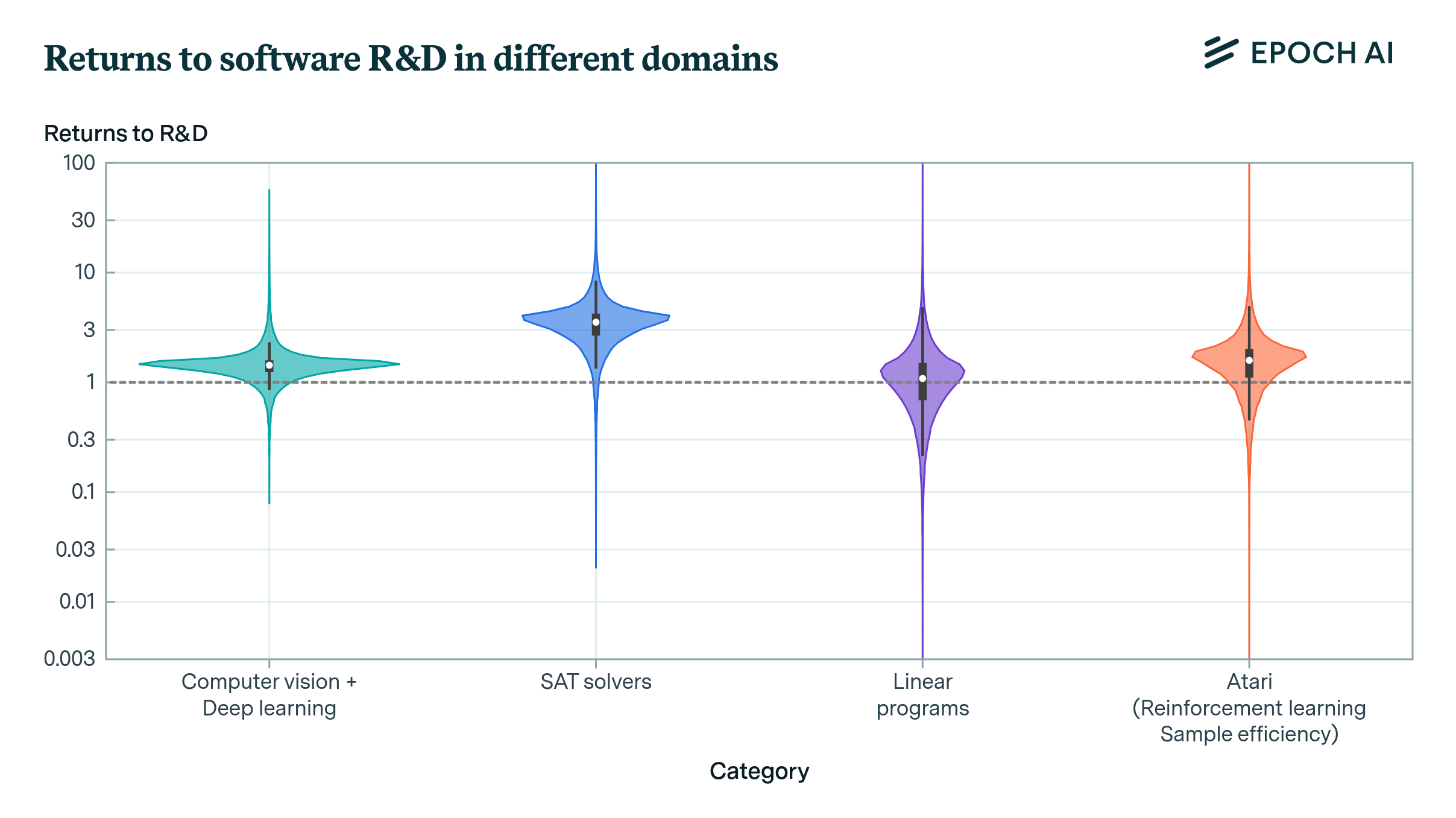
Do the Returns to Software R&D Point Towards a Singularity?
The returns to R&D are crucial in determining the dynamics of growth and potentially the pace of AI development. Our new paper offers new empirical techniques and estimates for this crucial parameter.
paper
· 4 min read
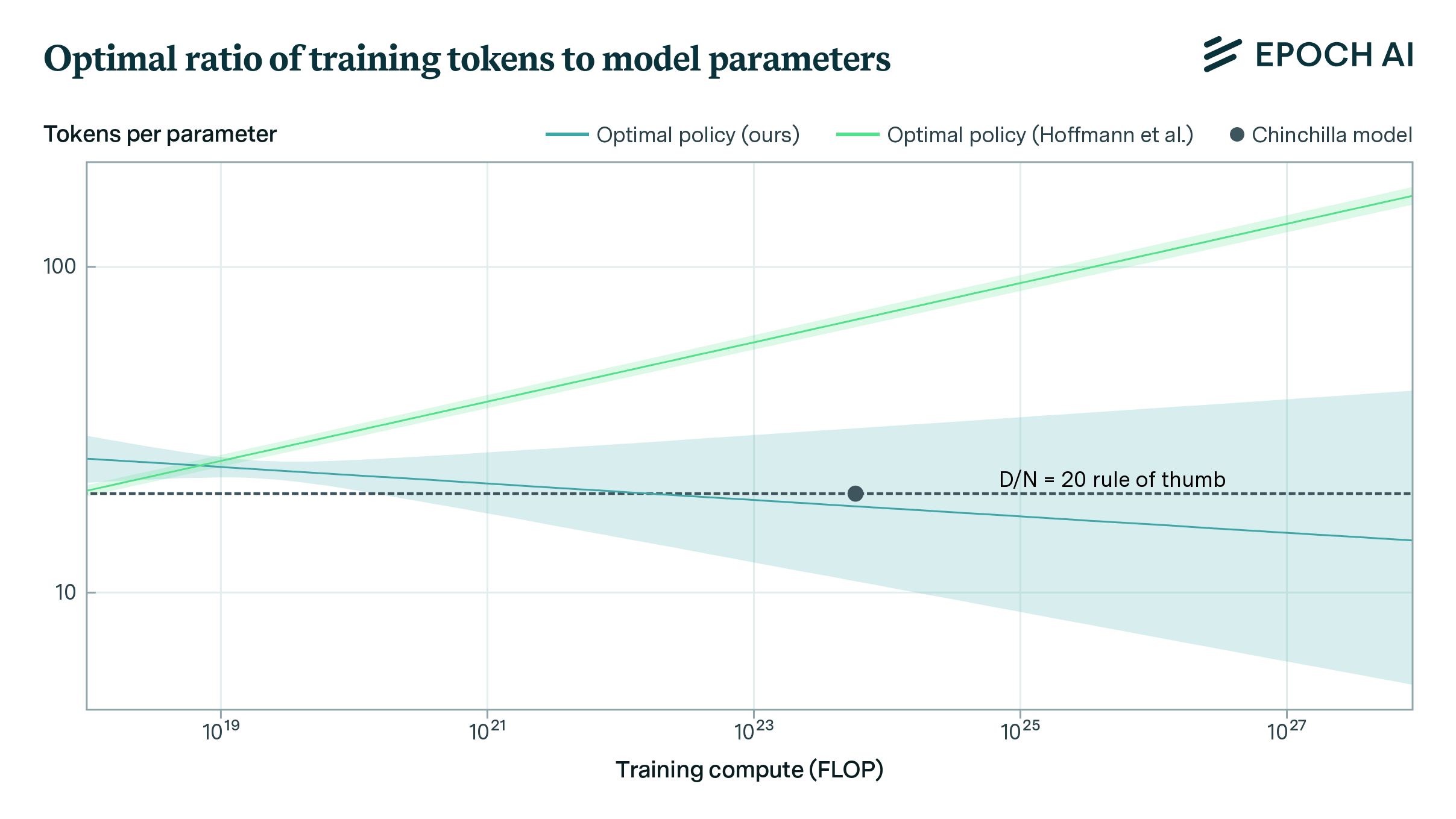
Chinchilla Scaling: A Replication Attempt
We replicate Hoffmann et al.’s estimation of a parametric scaling law and find issues with their estimates. Our estimates fit the data better and align with Hoffmann's other approaches.
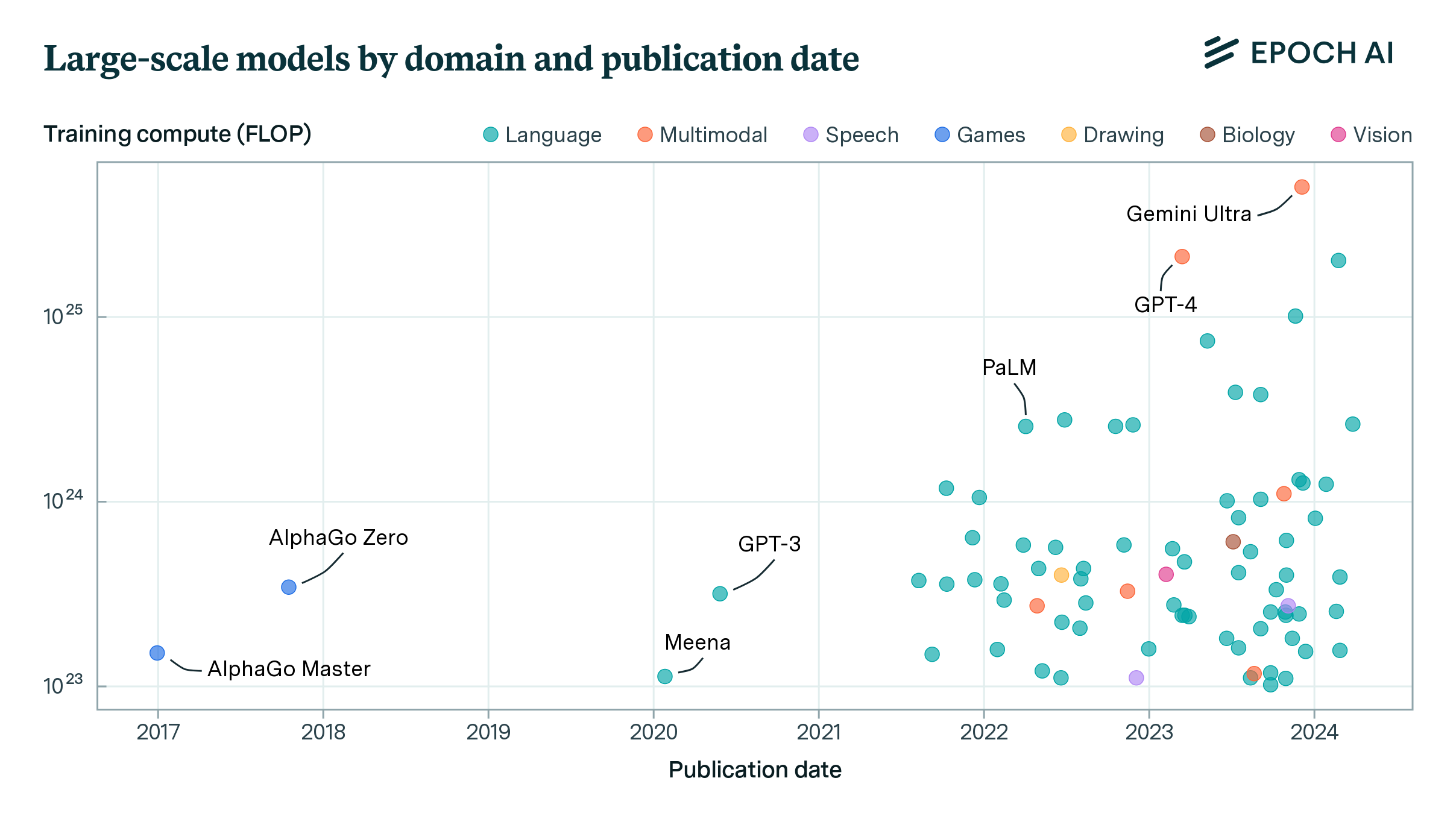
report
· 16 min read
Tracking Large-Scale AI Models
We present a dataset of 81 large-scale models, from AlphaGo to Gemini, developed across 18 countries, at the leading edge of scale and capabilities.
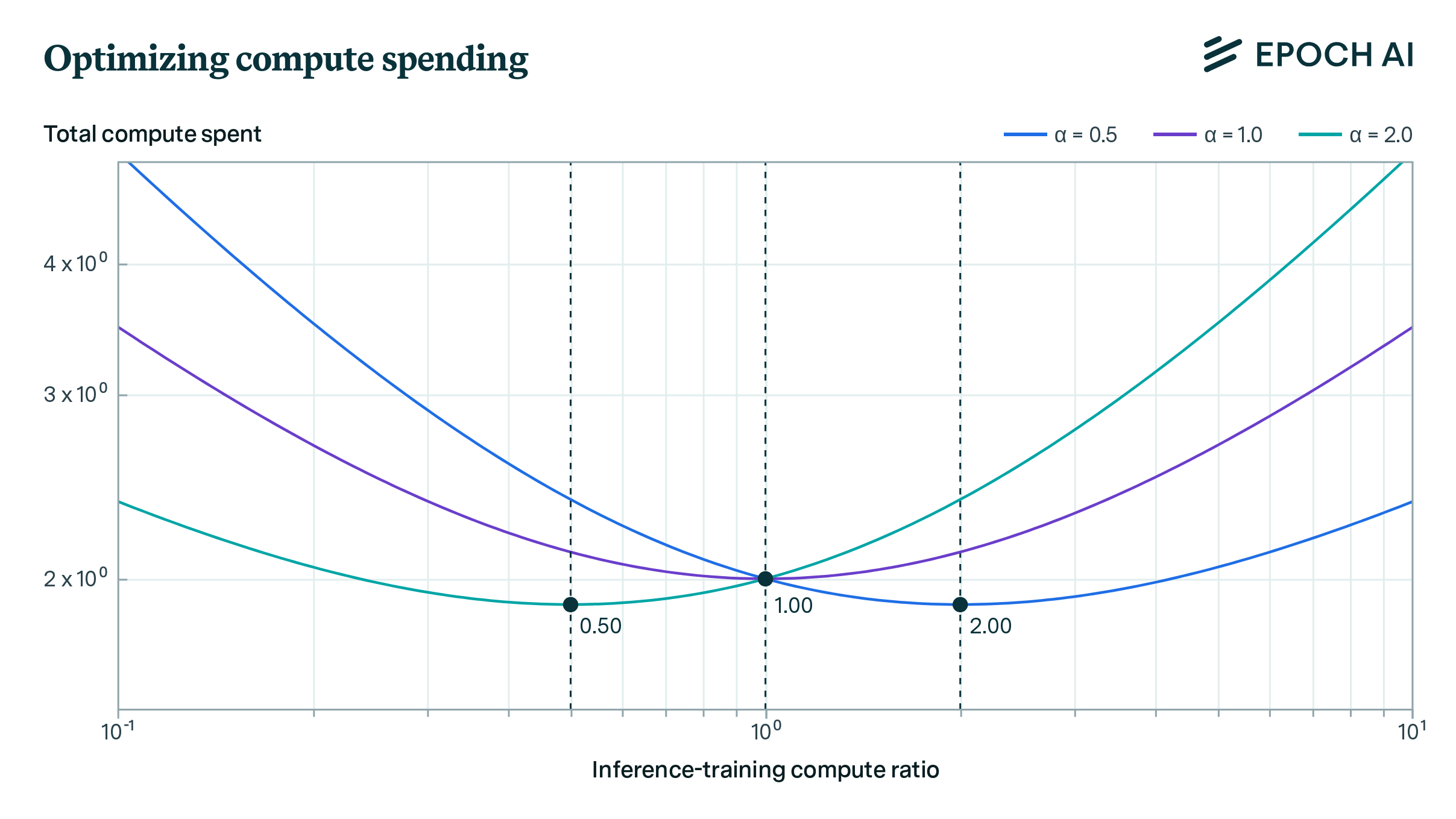
report
· 9 min read
Optimally Allocating Compute Between Inference and Training
Our analysis indicates that AI labs should spend comparable resources on training and running inference, assuming they can flexibly balance compute between these tasks to maintain model performance.
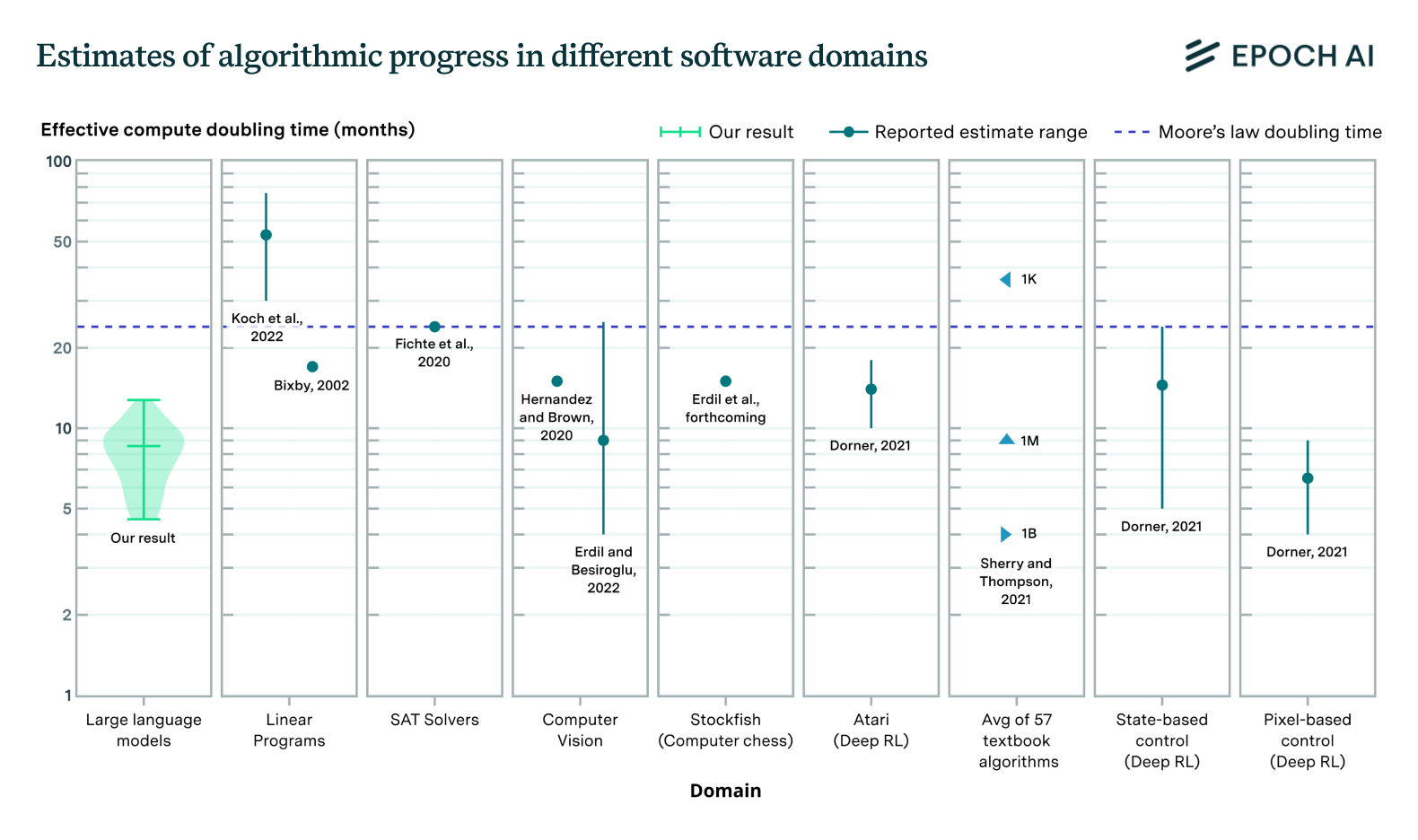
paper
· 3 min read
Algorithmic Progress in Language Models
Progress in language model performance surpasses what we'd expect from merely increasing computing resources, occurring at a pace equivalent to doubling computational power every 5 to 14 months.

announcement
· 10 min read
Epoch AI Impact Assessment 2023
In 2023, Epoch published almost 20 reports on developments in AI, added hundreds of new models to our database, had a direct impact on government policies, raised over $7 million in funds, and more.
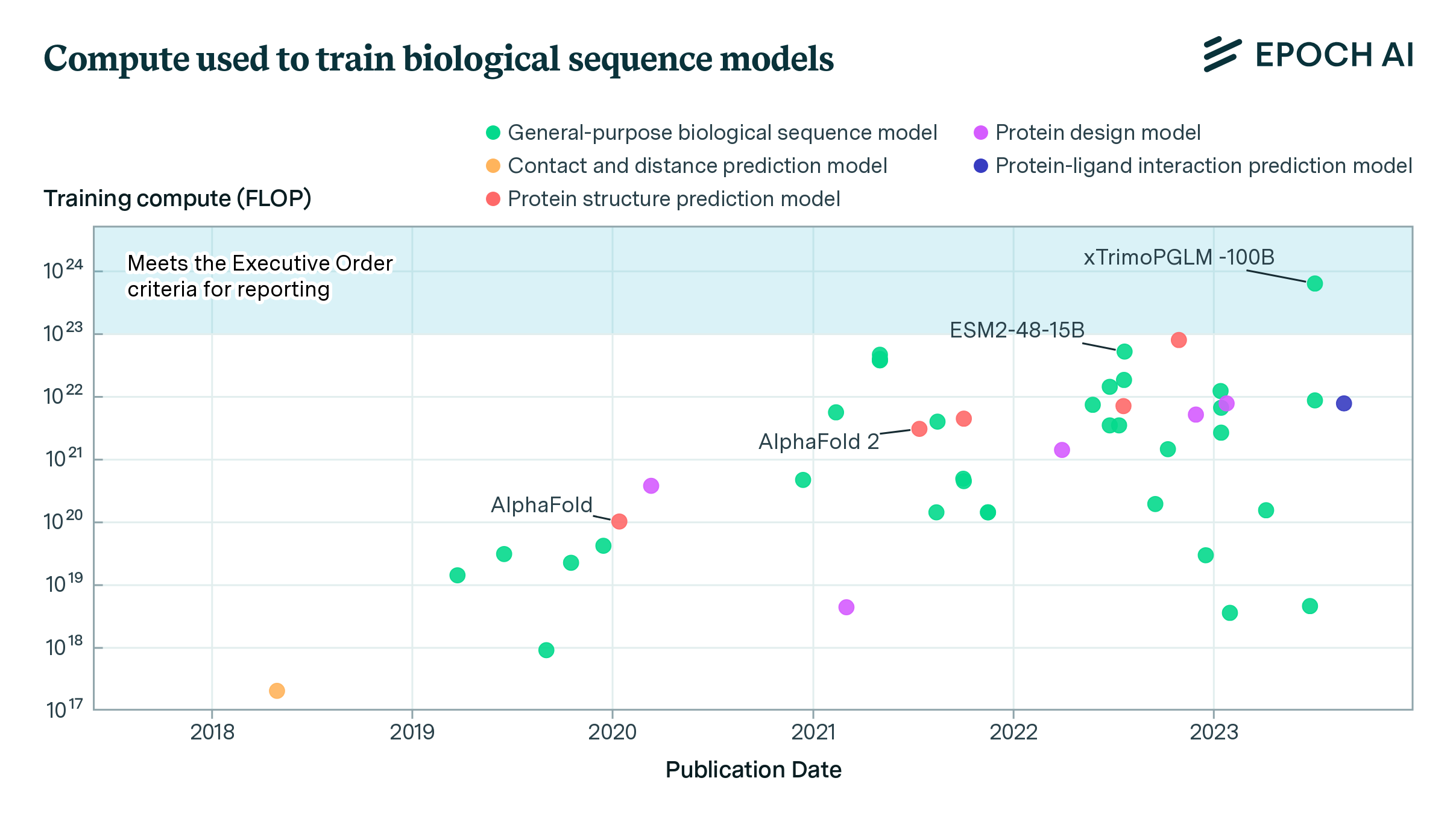
report
· 23 min read
Biological Sequence Models in the Context of the AI Directives
The expanded Epoch database now includes biological sequence models, revealing potential regulatory gaps in the White House’s Executive Order on AI and the growth of the compute used in their training.
paper
· 3 min read
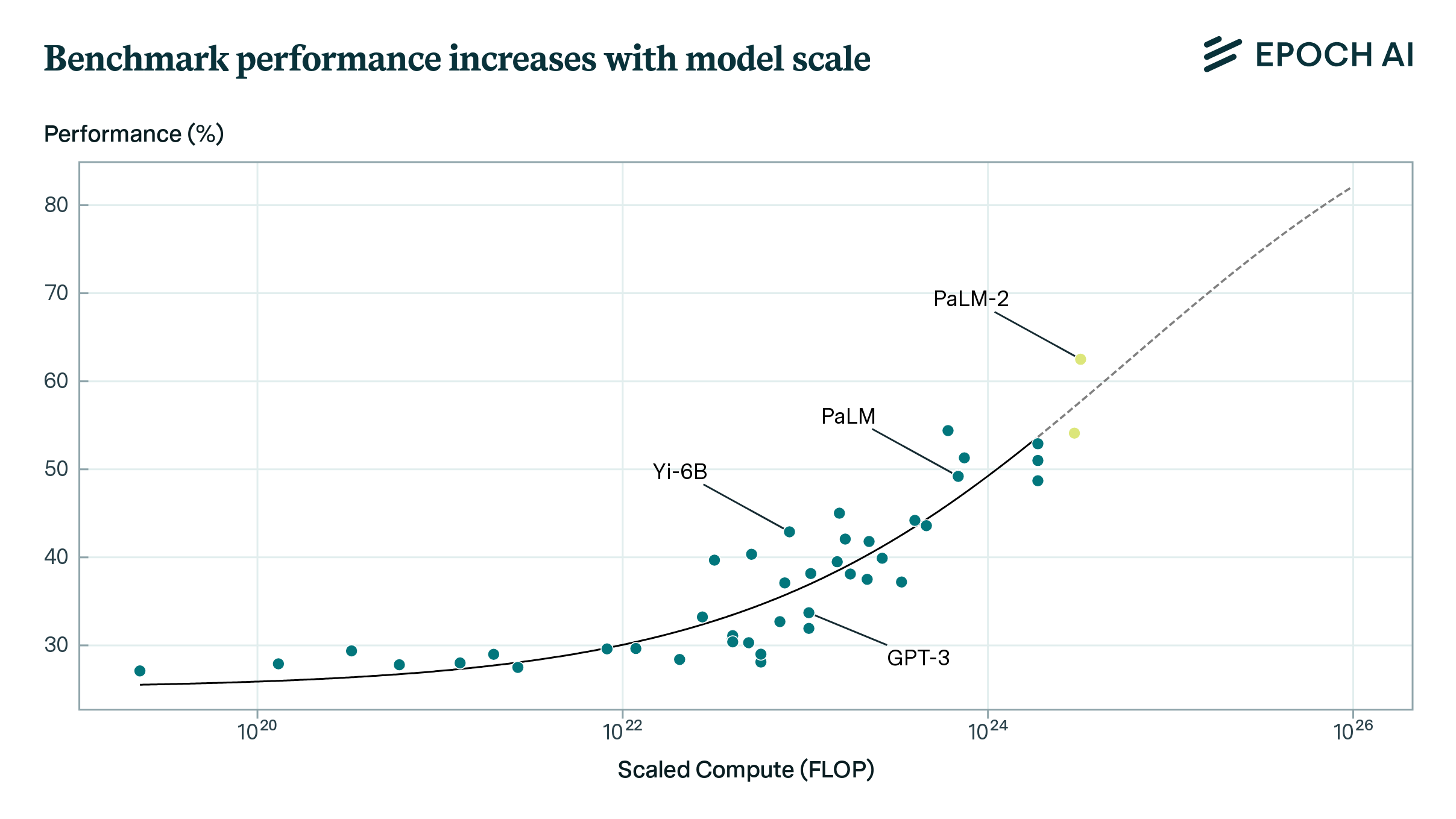
How Predictable Is Language Model Benchmark Performance?
We investigate large language model performance across five orders of magnitude of compute scaling, finding that compute-focused extrapolations are a promising way to forecast AI capabilities.
paper
· 4 min read
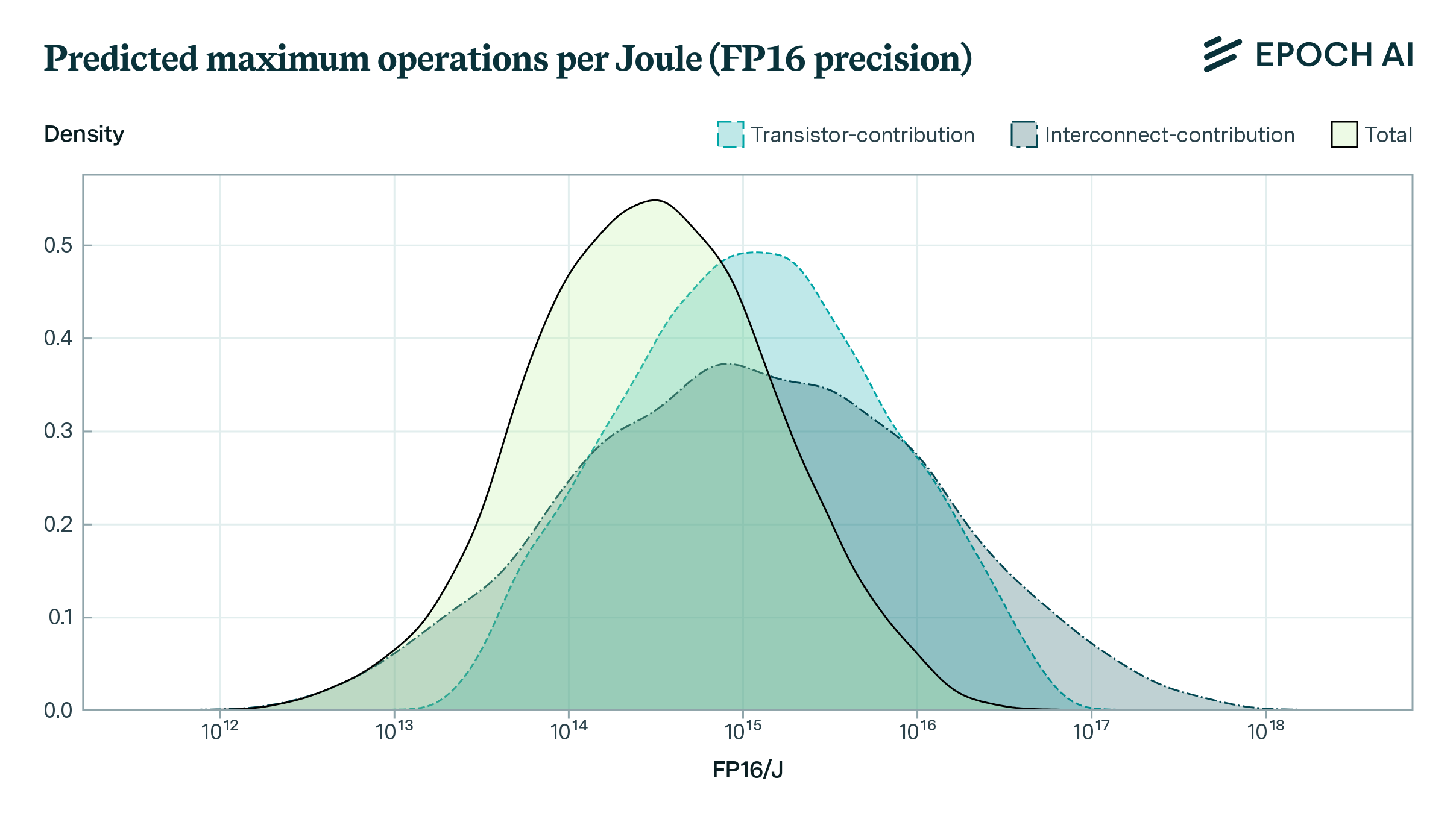
Limits to the Energy Efficiency of CMOS Microprocessors
How far can the energy efficiency of CMOS microprocessors be pushed before we hit physical limits? Using a simple model, we find that there is room for a further 50 to 1000x improvement in energy efficiency.
paper
· 2 min read
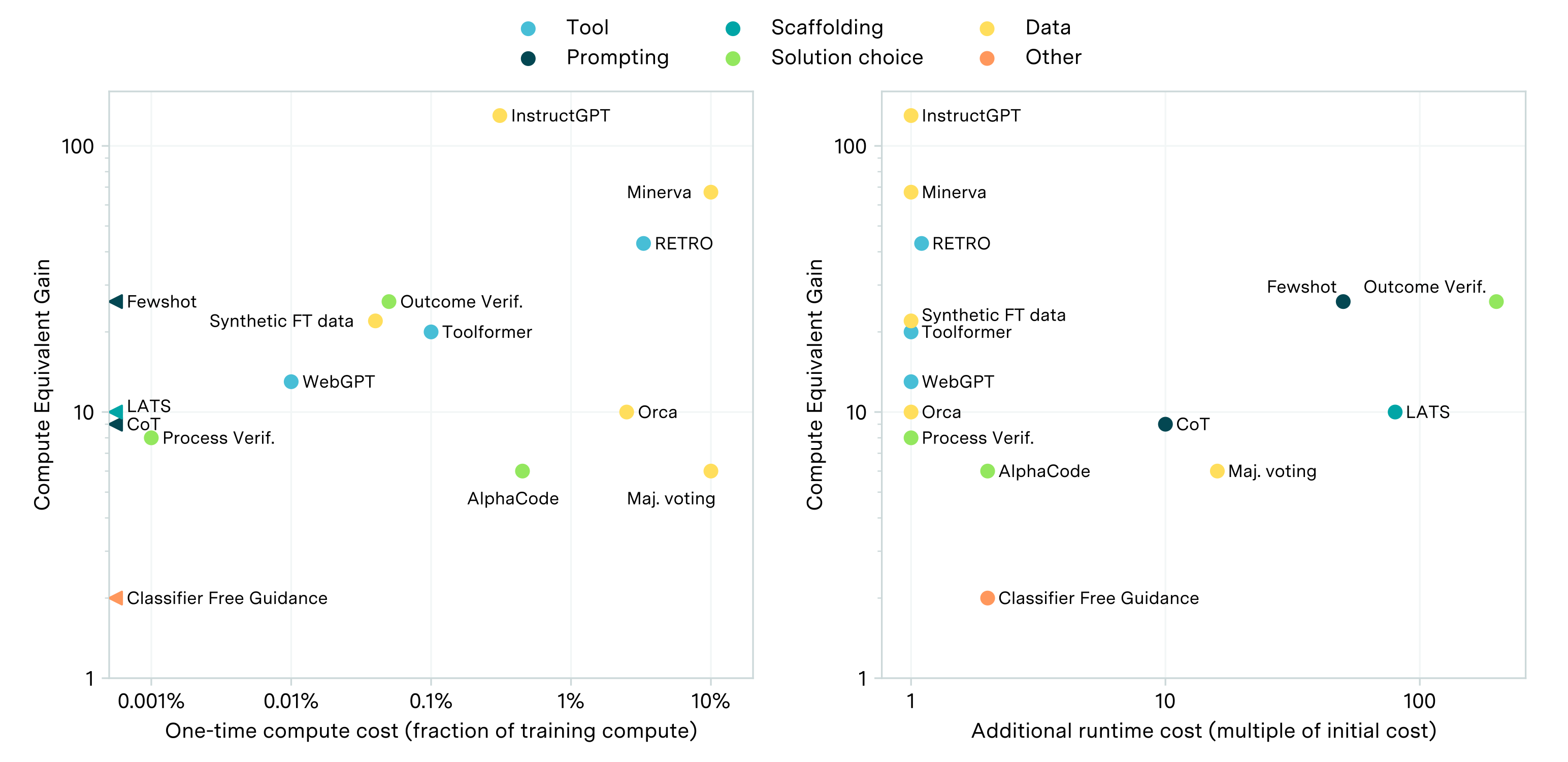
AI Capabilities Can Be Significantly Improved Without Expensive Retraining
While scaling compute for training is key to improving LLM performance, some post-training enhancements can offer gains equivalent to training with 5 to 20x more compute at less than 1% the cost.
paper
· 3 min read
Who Is Leading in AI? An Analysis of Industry AI Research
Industry emerged as a driving force in AI, but which companies are steering the field? We compare leading AI companies on research impact, training runs, and contributions to algorithmic innovations.
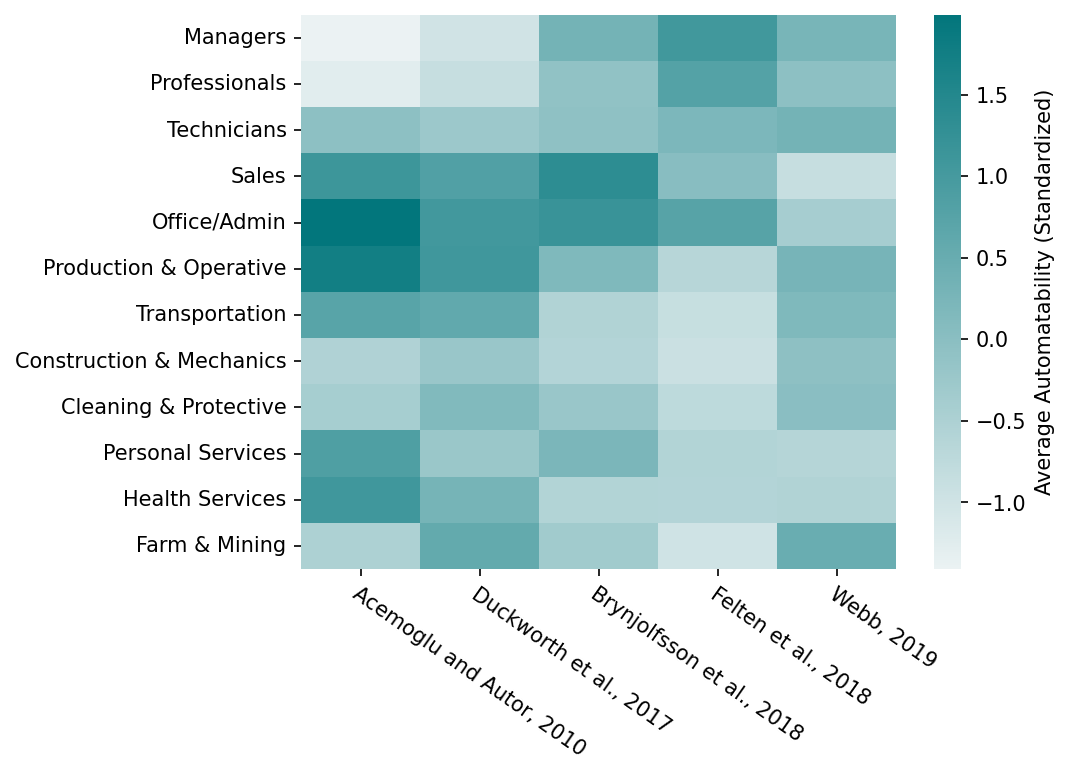
report
· 31 min read
Challenges in Predicting AI Automation
Economists have proposed several different approaches to predicting AI automation of economically valuable tasks. There is vast disagreement between different approaches and no clear winner.
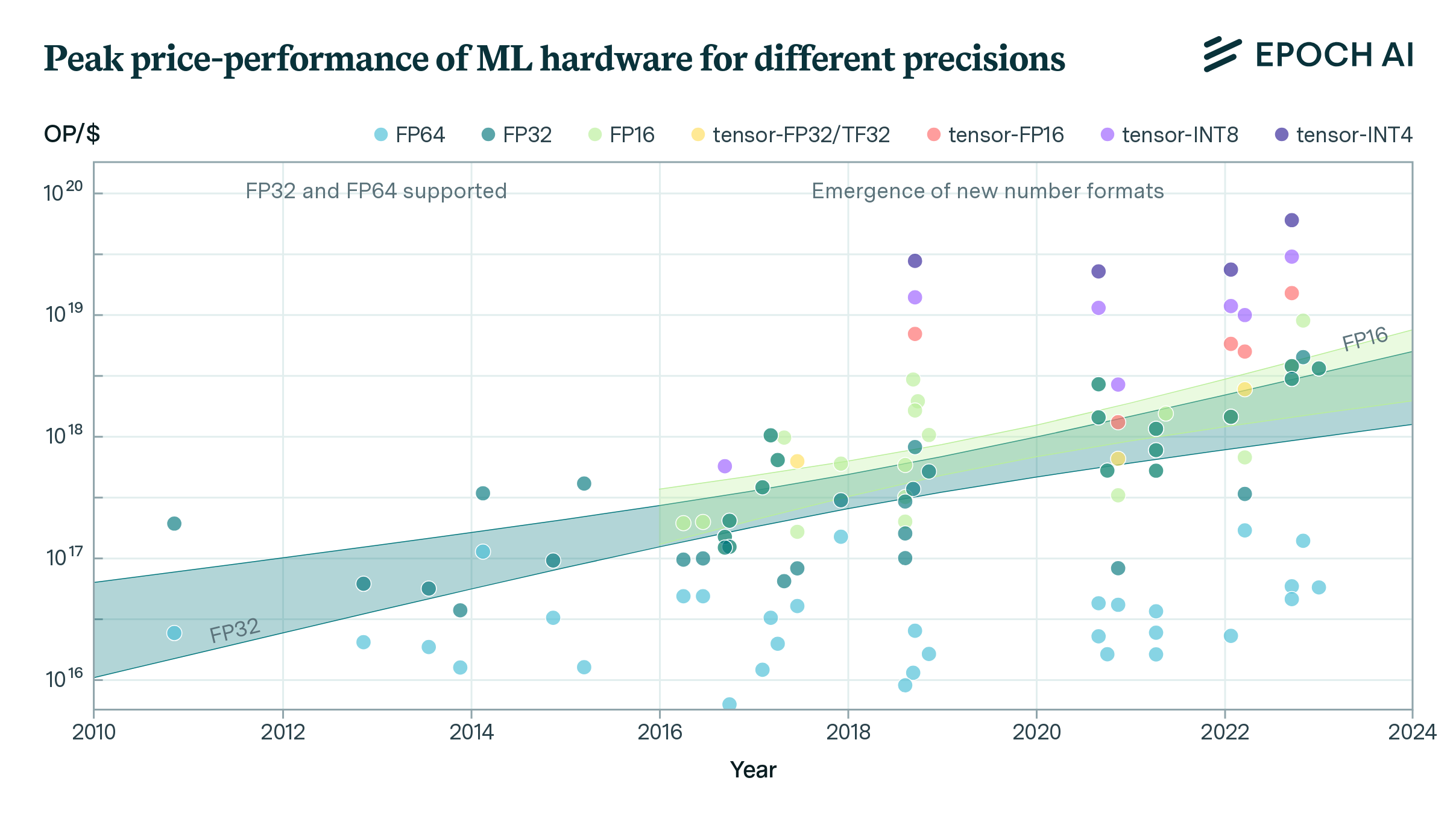
report
· 27 min read
Trends in Machine Learning Hardware
FLOP/s performance in 47 ML hardware accelerators doubled every 2.3 years. Switching from FP32 to tensor-FP16 led to a further 10x performance increase. Memory capacity and bandwidth doubled every 4 years.
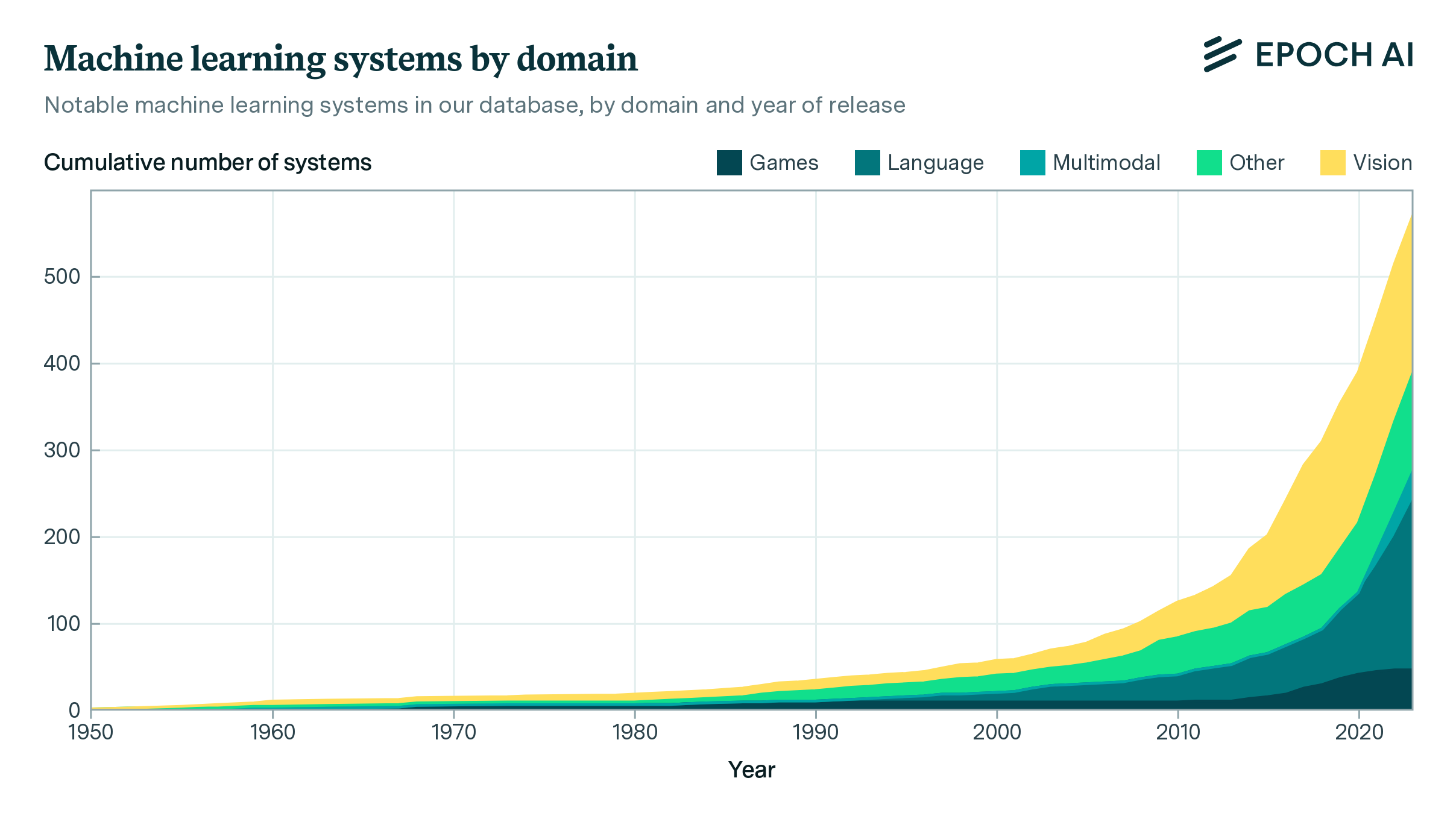
announcement
· 1 min read
Announcing Epoch AI’s Updated Parameter, Compute and Data Trends Database
Our expanded database, which tracks the parameters, datasets, training compute, and other details of notable machine learning systems, now spans over 700 notable machine learning models.
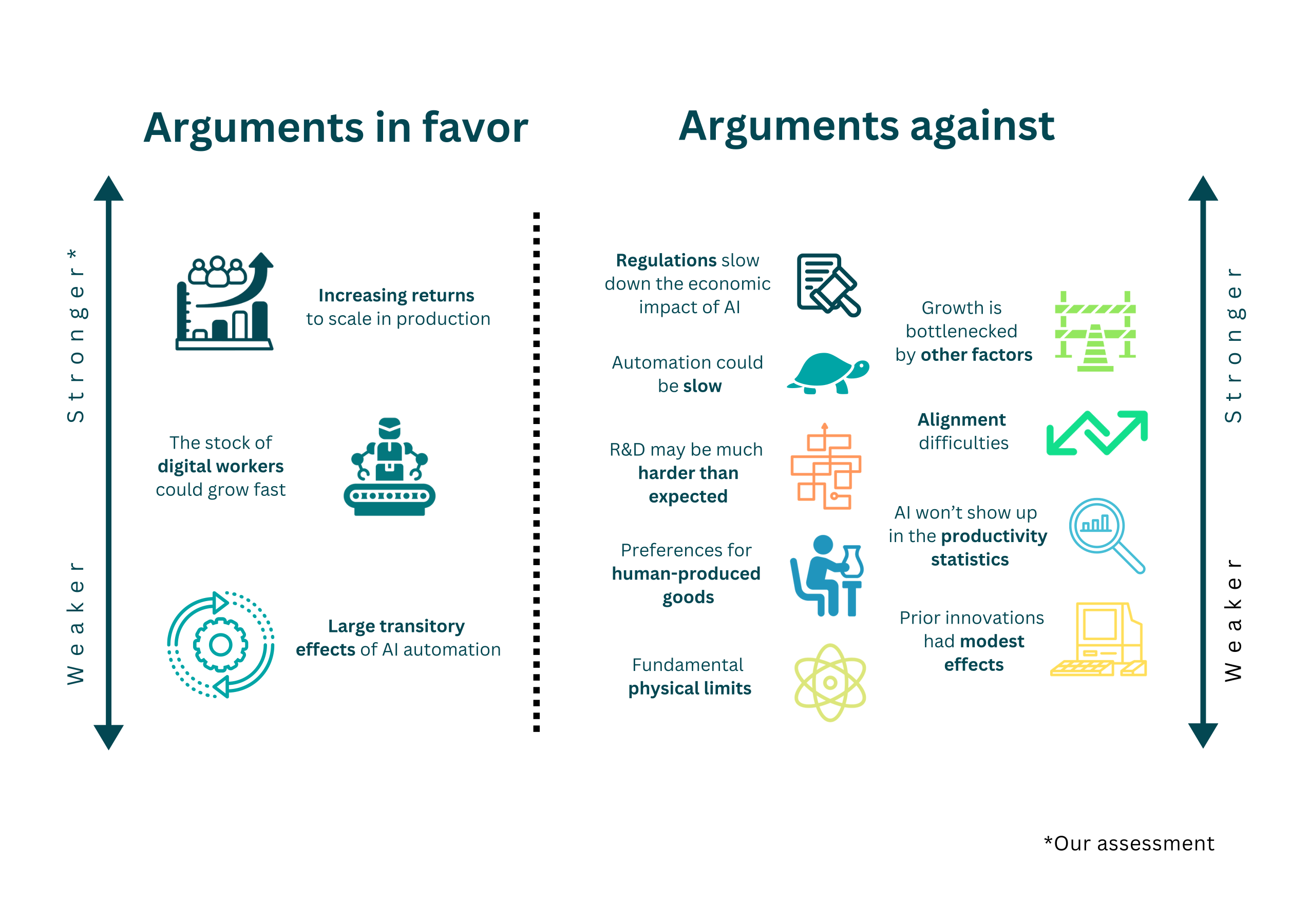
paper
· 11 min read
Explosive Growth from AI: A Review of the Arguments
Our new article examines why we might (or might not) expect growth on the order of ten-fold the growth rates common in today’s frontier economies once advanced AI systems are widely deployed.
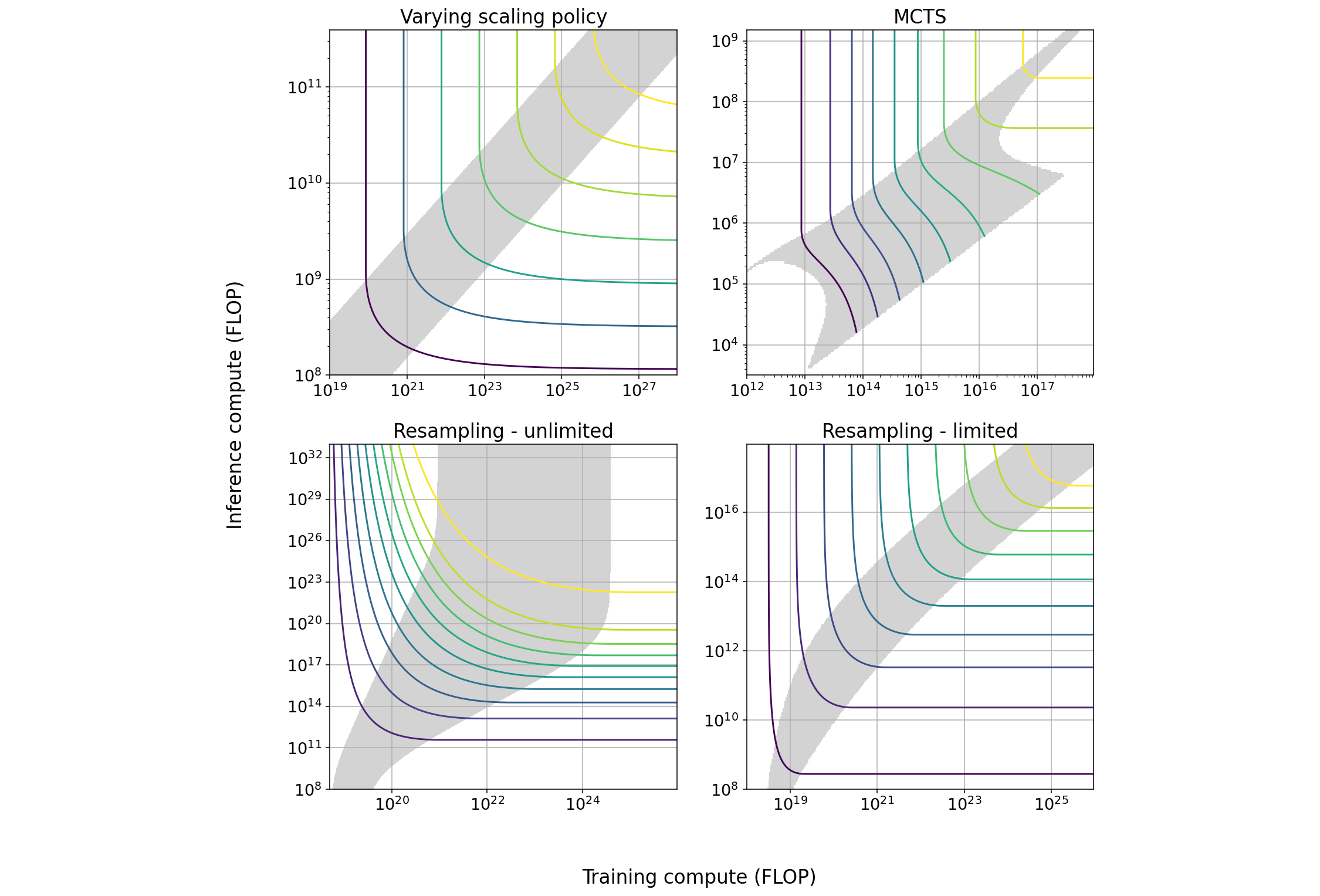
report
· 27 min read
Trading Off Compute in Training and Inference
We explore several techniques that induce a tradeoff between spending more resources on training or on inference and characterize the properties of this tradeoff. We outline some implications for AI governance.
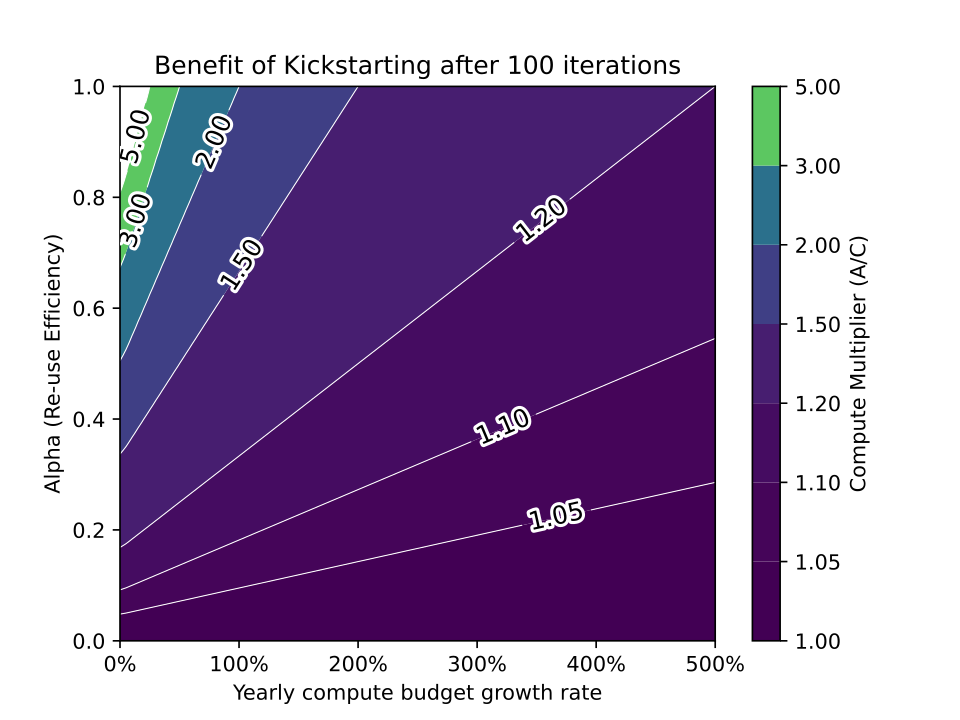
report
· 10 min read
The Limited Benefit of Recycling Foundation Models
While reusing pretrained models often saves training costs on large training runs, it is unlikely that model recycling will result in more than a modest increase in AI capabilities.

announcement
· 3 min read
Epoch AI and FRI Mentorship Program Summer 2023
We are launching the Epoch and FRI mentorship program for women, non-binary people, and transgender people of all genders to provide guidance to individuals who want to contribute to AI forecasting.
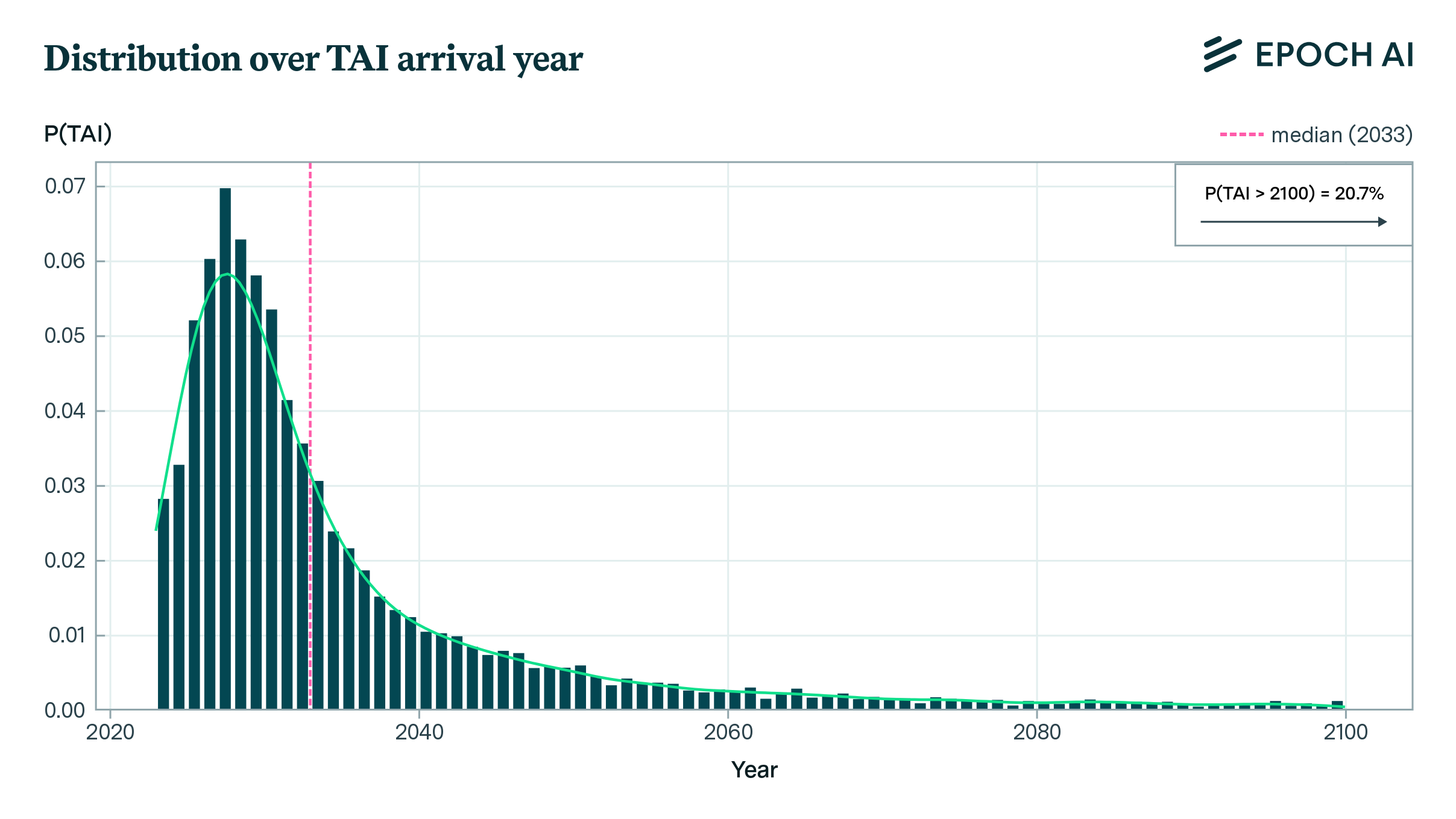
report
· 14 min read
Direct Approach Interactive Model
We combine the Direct Approach framework with simple models of progress in algorithms, investment, and compute costs to produce a user-adjustable forecast of when TAI will be achieved.
viewpoint
· 26 min read
A Compute-Based Framework for Thinking About the Future of AI
AI's potential to automate labor is likely to alter the course of human history within decades, with the availability of compute being the most important factor driving rapid progress in AI capabilities.

viewpoint
· 1 min read
Please Report Your Compute
Compute is essential for AI performance, but researchers often fail to report it. Adopting reporting norms would support research, enhance forecasts of AI’s impacts and developments, and assist policymakers.
report
· 10 min read
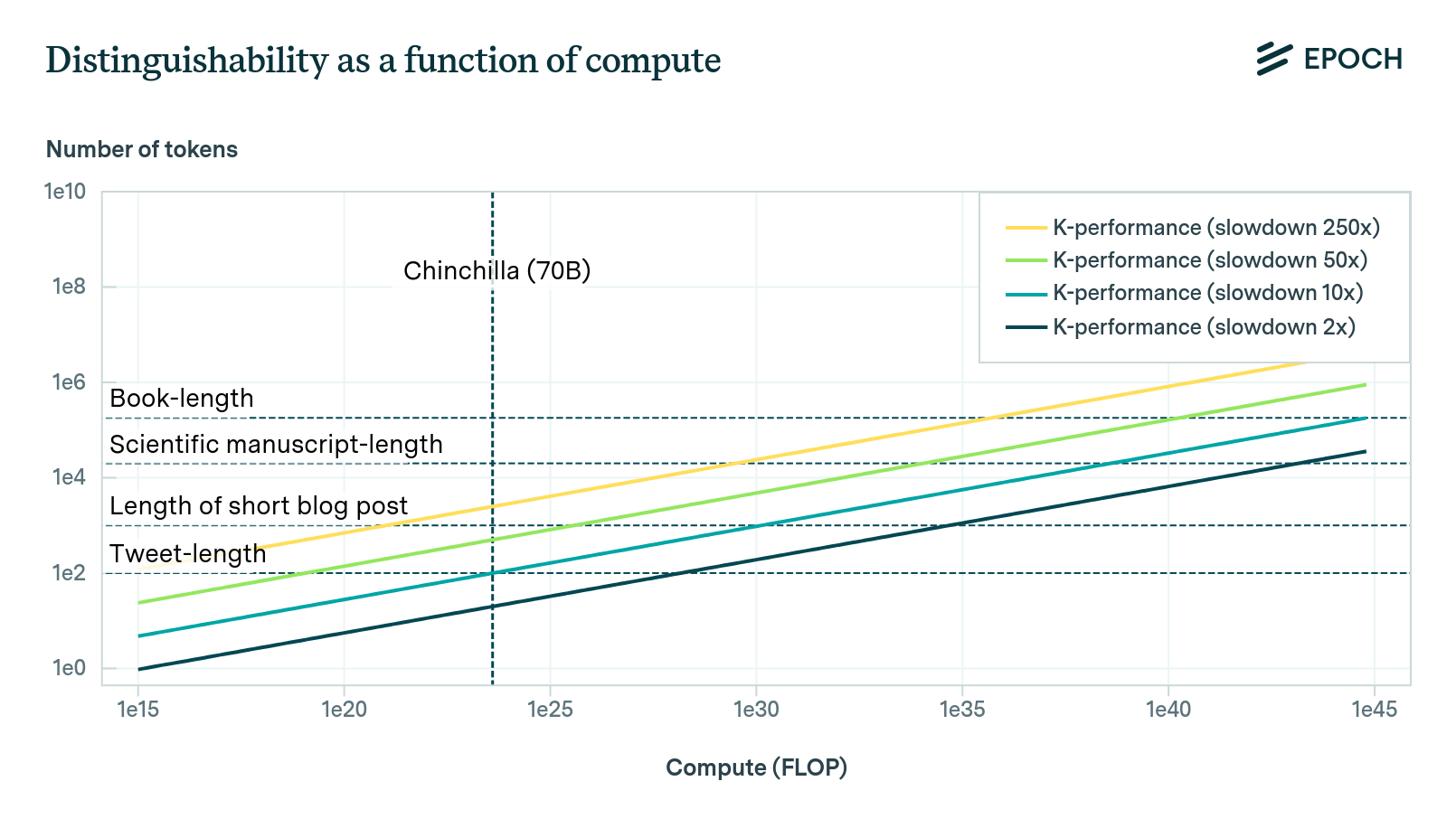
The Direct Approach
Empirical scaling laws can help predict the cross-entropy loss associated with training inputs, such as compute and data. However, in order to predict when AI will achieve some subjective level of performance, it is necessary to devise a way of interpreting the cross-entropy loss of a model. This blog post provides a discussion of one such theoretical method, which we call the Direct Approach.
paper
· 2 min read
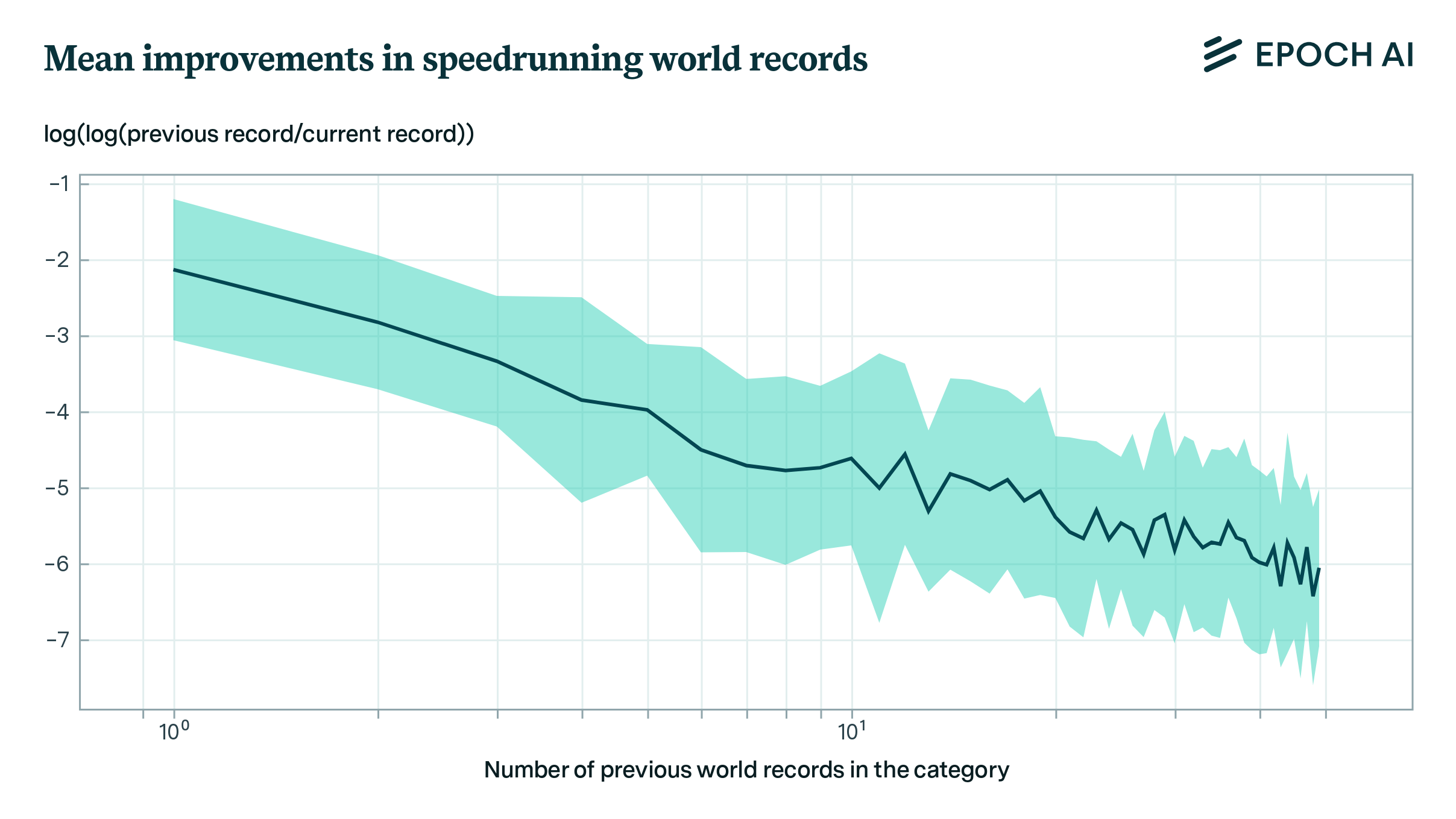
Power Laws in Speedrunning and Machine Learning
We develop a model for predicting record improvements in video game speedrunning and apply it to predicting machine learning benchmarks. This model suggests that machine learning benchmarks are not close to saturation, and that large sudden improvements are infrequent, but not ruled out.
announcement
· 1 min read
Announcing Epoch AI’s Dashboard of Key Trends and Figures in Machine Learning
We are launching a dashboard that provides key data from our research on machine learning, aiming to serve as a valuable resource for understanding the present and future of the field.
announcement
· 1 min read
Epoch AI Impact Assessment 2022
Our impact report for 2022.
report
· 66 min read
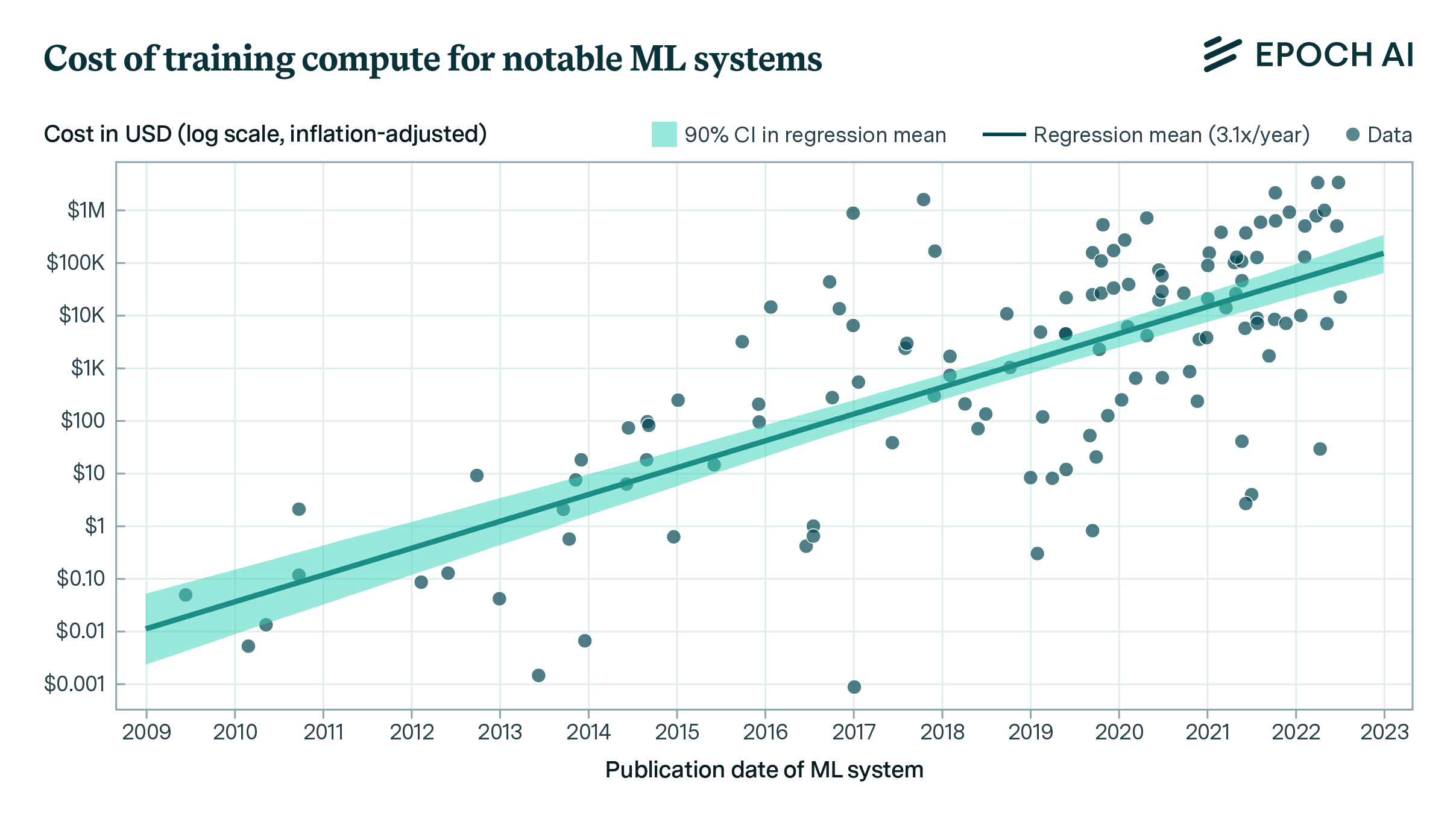
Trends in the Dollar Training Cost of Machine Learning Systems
I combine training compute and GPU price-performance data to estimate the cost of compute in US dollars for the final training run of 124 machine learning systems published between 2009 and 2022, and find that the cost has grown by approximately 0.5 orders of magnitude per year.
report
· 6 min read
Scaling Laws Literature Review
I have collected a database of scaling laws for different tasks and architectures, and reviewed dozens of papers in the scaling law literature.
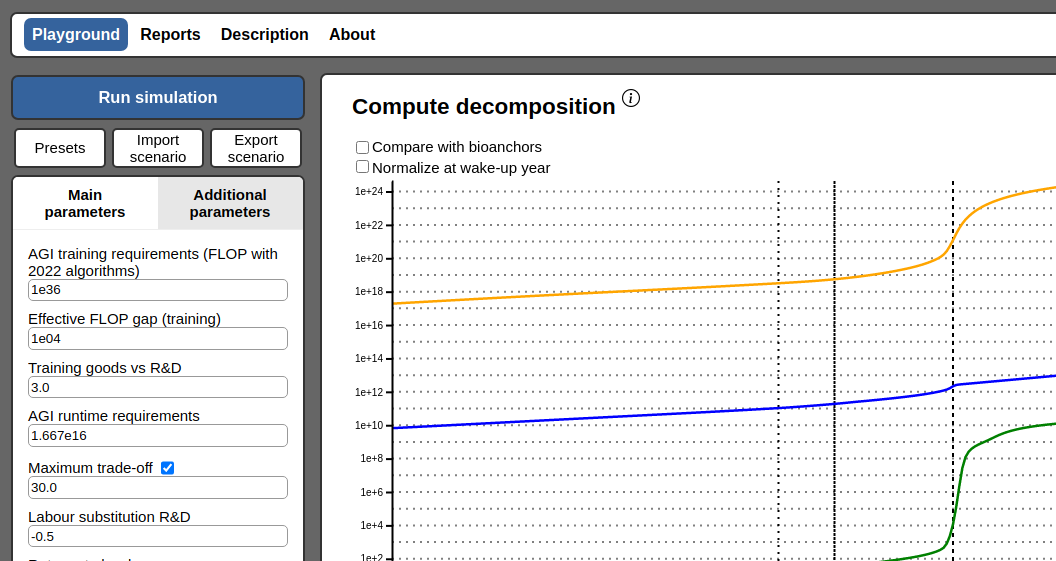
announcement
· 1 min read
An Interactive Model of AI Takeoff Speeds
We have developed an interactive website showcasing a new model of AI takeoff speeds.
report
· 16 min read
Literature Review of Transformative Artificial Intelligence Timelines
We summarize and compare several models and forecasts predicting when transformative AI will be developed.
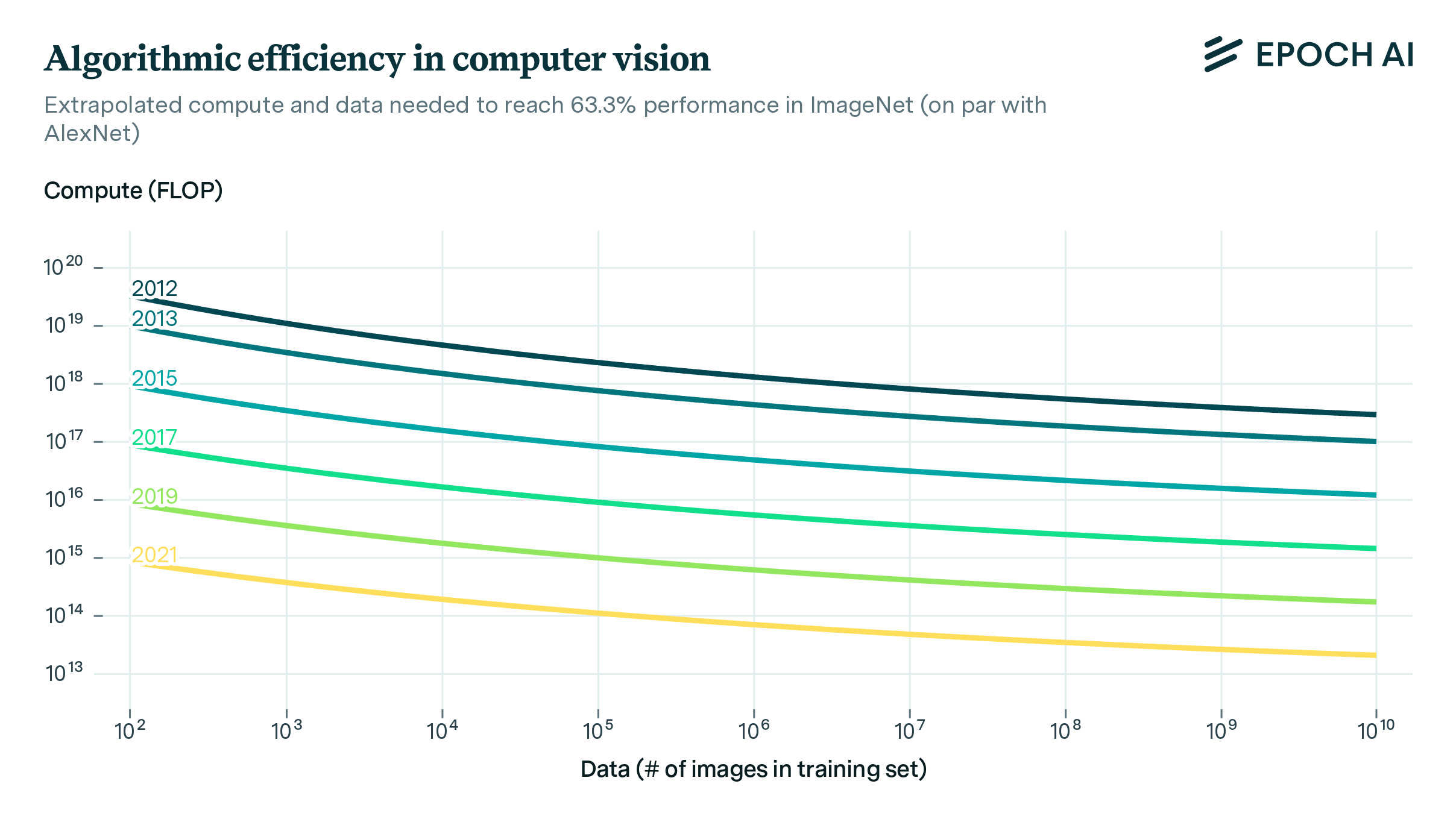
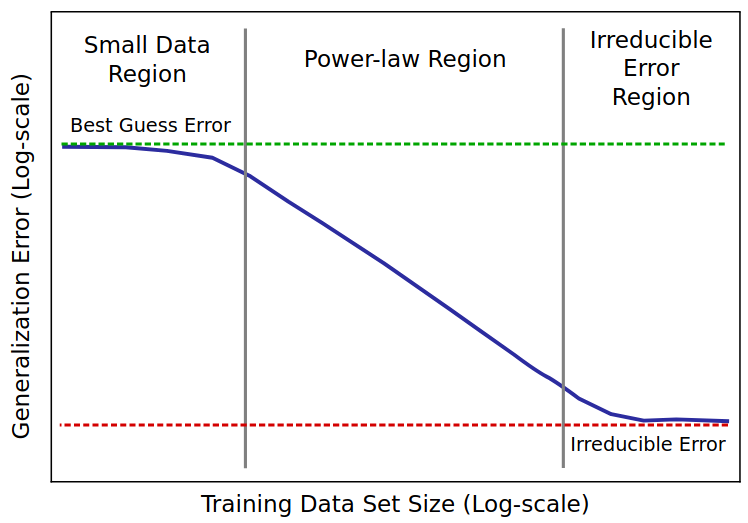
paper
· 2 min read
Revisiting Algorithmic Progress
We use a dataset of over a hundred computer vision models from the last decade to investigate how better algorithms and architectures have enabled researchers to use compute and data more efficiently. We find that every 9 months, the introduction of better algorithms contribute the equivalent of a doubling of compute budgets.
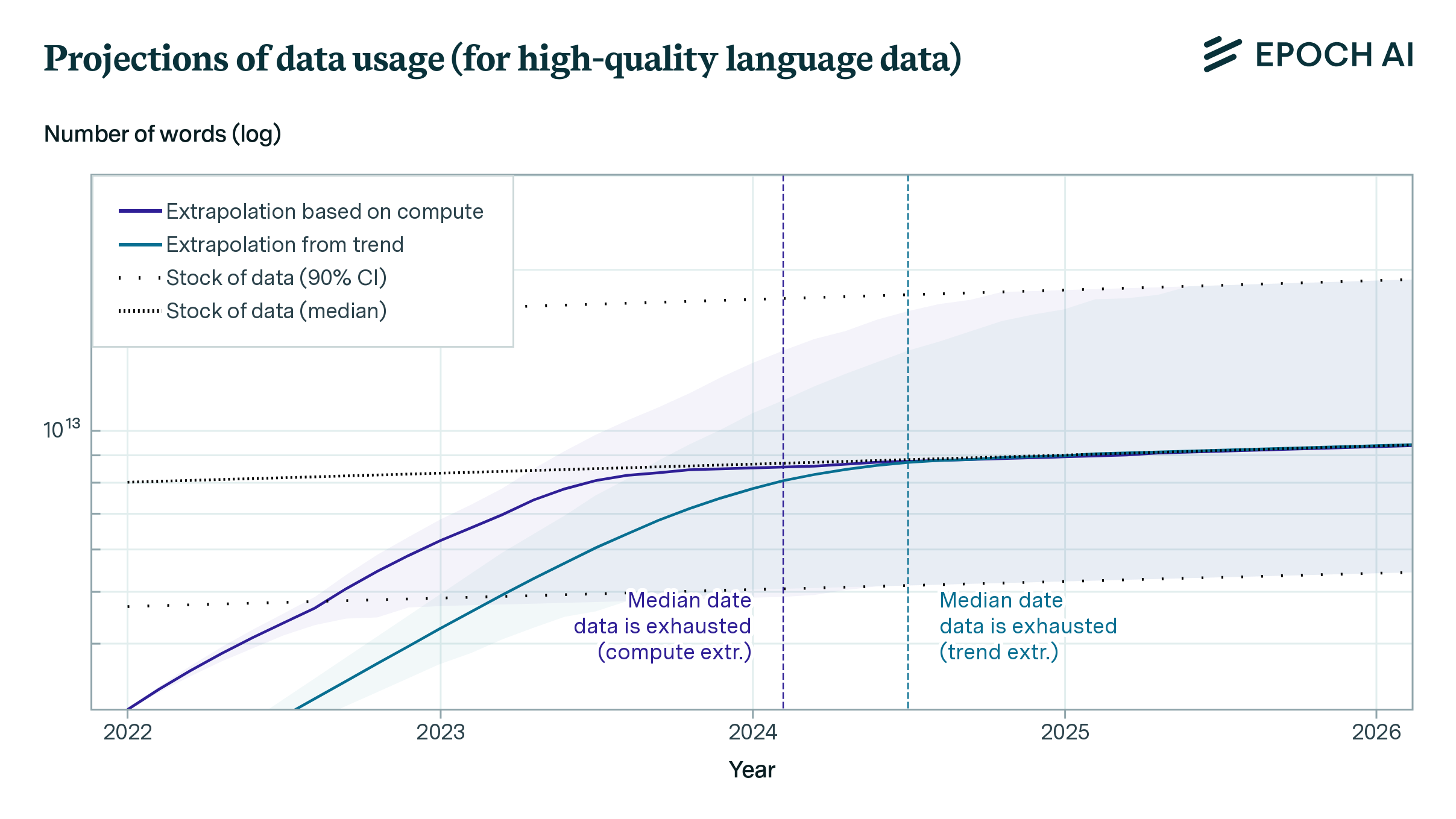
paper
· 3 min read
Will We Run Out of ML Data? Evidence From Projecting Dataset Size Trends
Based on our previous analysis of trends in dataset size, we project the growth of dataset size in the language and vision domains. We explore the limits of this trend by estimating the total stock of available unlabeled data over the next decades.
report
· 12 min read
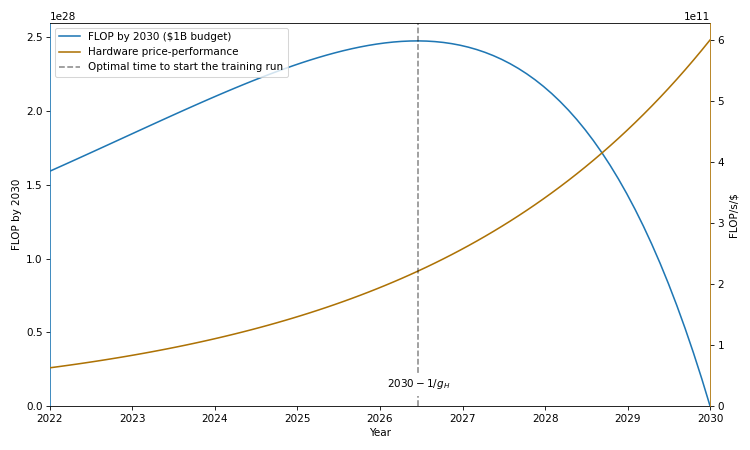
The Longest Training Run
Training runs of large machine learning systems are likely to last less than 14-15 months. This is because longer runs will be outcompeted by runs that start later and therefore use better hardware and better algorithms.
report
· 22 min read
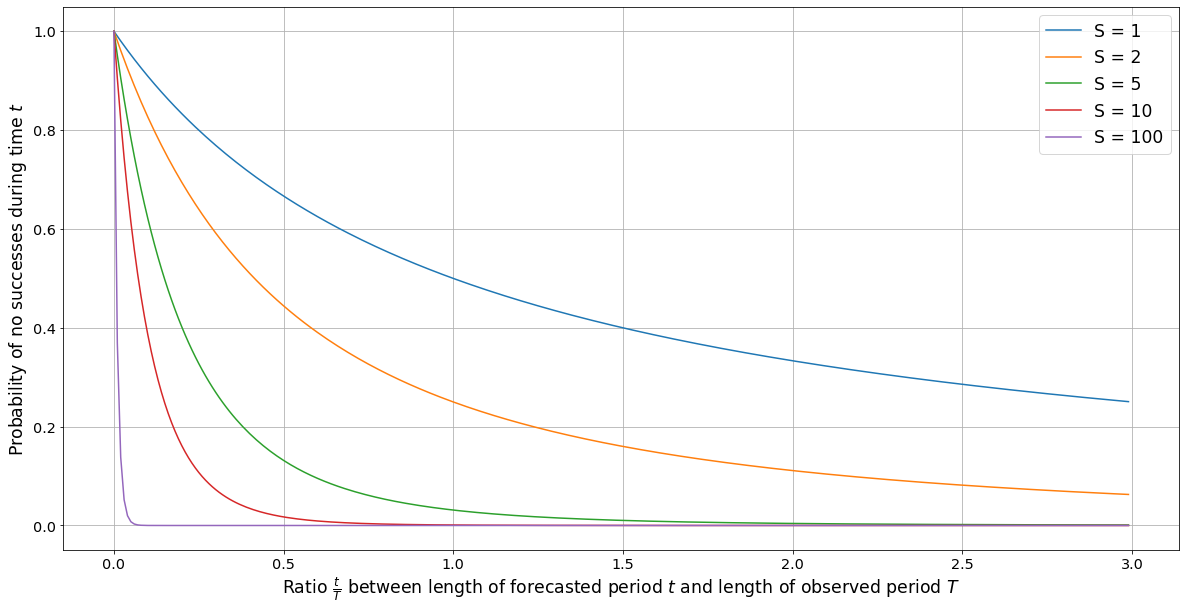
A Time-Invariant Version of Laplace’s Rule
We explore how to estimate the probability of an event given information of past occurrences. We explain a problem with the naive application of Laplace's rule in this context, and suggest a modification to correct it.

paper
· 2 min read
Machine Learning Model Sizes and the Parameter Gap
The model size of notable machine learning systems has grown ten times faster than before since 2018. After 2020 growth has not been entirely continuous: there was a jump of one order of magnitude which persists until today. This is relevant for forecasting model size and thus AI capabilities.
report
· 14 min read
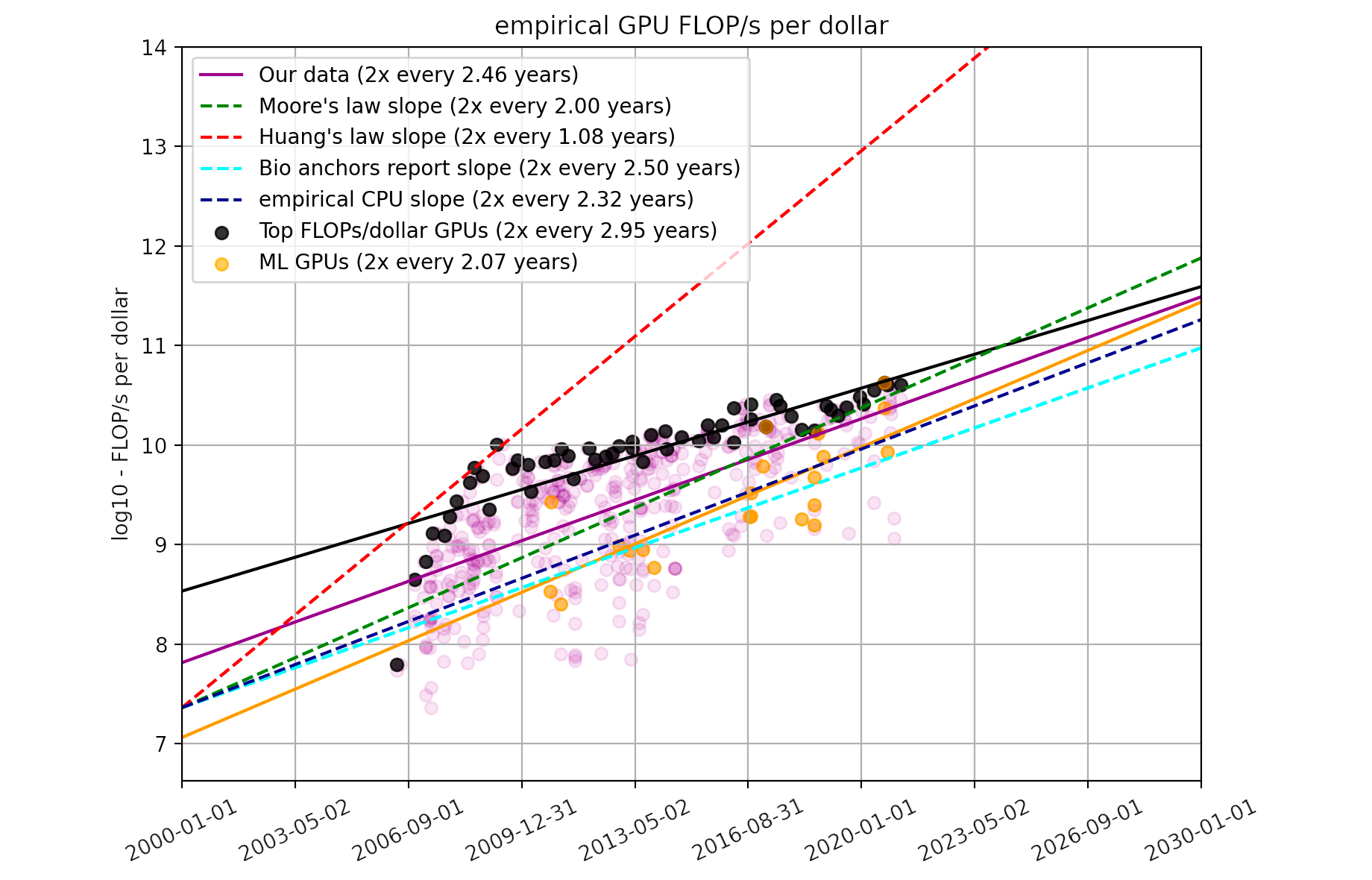
Trends in GPU Price-Performance
Using a dataset of 470 models of graphics processing units released between 2006 and 2021, we find that the amount of floating-point operations/second per $ doubles every ~2.5 years.
announcement
· 4 min read
Announcing Epoch AI: A Research Initiative Investigating the Road to Transformative AI
We are a new research initiative forecasting developments in AI. Come join us!

paper
· 7 min read
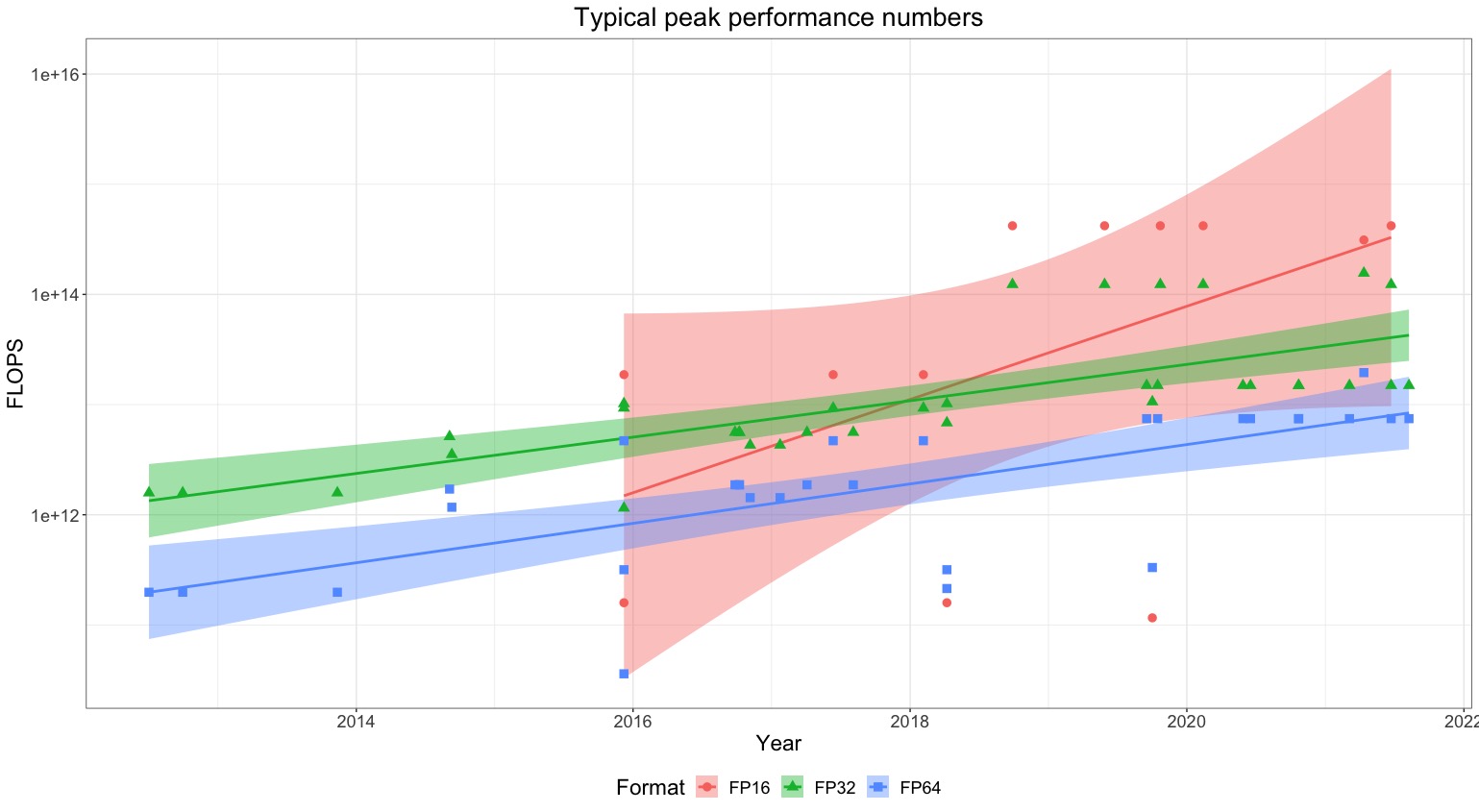
Compute Trends Across Three Eras of Machine Learning
We’ve compiled a dataset of the training compute for over 120 machine learning models, highlighting novel trends and insights into the development of AI since 1952, and what to expect going forward.
report
· 24 min read
Estimating Training Compute of Deep Learning Models
We describe two approaches for estimating the training compute of Deep Learning systems, by counting operations and looking at GPU time.
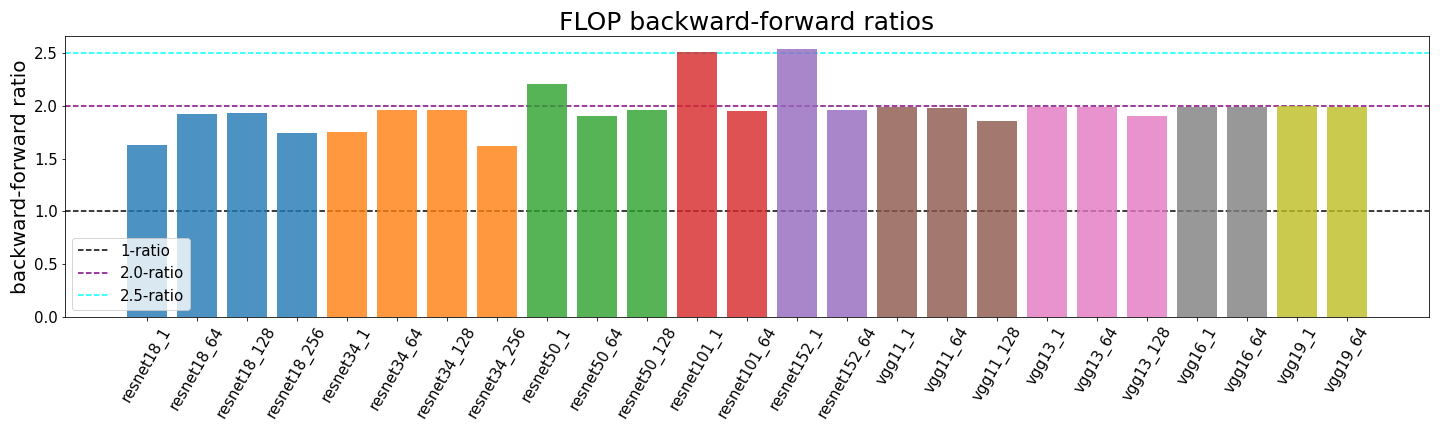
report
· 8 min read
What’s the Backward-Forward FLOP Ratio for Neural Networks?
Determining the backward-forward FLOP ratio for neural networks, to help calculate their total training compute.
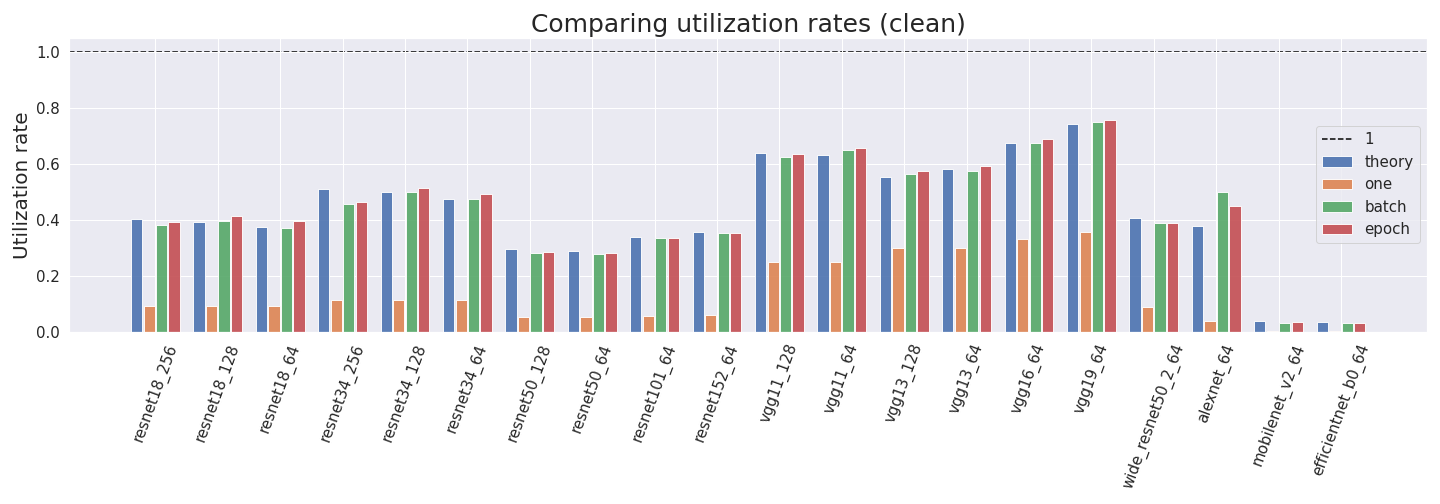
report
· 9 min read
How to Measure FLOP for Neural Networks Empirically?
Computing the utilization rate for multiple Neural Network architectures.