







Machine Learning Trends
Our ML Trends dashboard offers curated key numbers, visualizations, and insights that showcase the significant growth and impact of artificial intelligence.
Last updated on Jun 07, 2024
Display growth values in:
 Training compute
Training compute
 Training data
Training data
 Computational performance
Computational performance
 Algorithmic improvements
Algorithmic improvements
 Training costs
Training costs
Compute Trends
Deep Learning compute
Pre-Deep Learning compute

Training compute of frontier AI models grows by 4-5x per year
Our expanded AI model database shows that the compute used to train recent models grew 4-5x yearly from 2010 to May 2024. We find similar growth in frontier models, recent large language models, and models from leading companies.
Most compute used in a training run
Data Trends
Language training dataset size
When will the largest training runs use all public human-generated text?
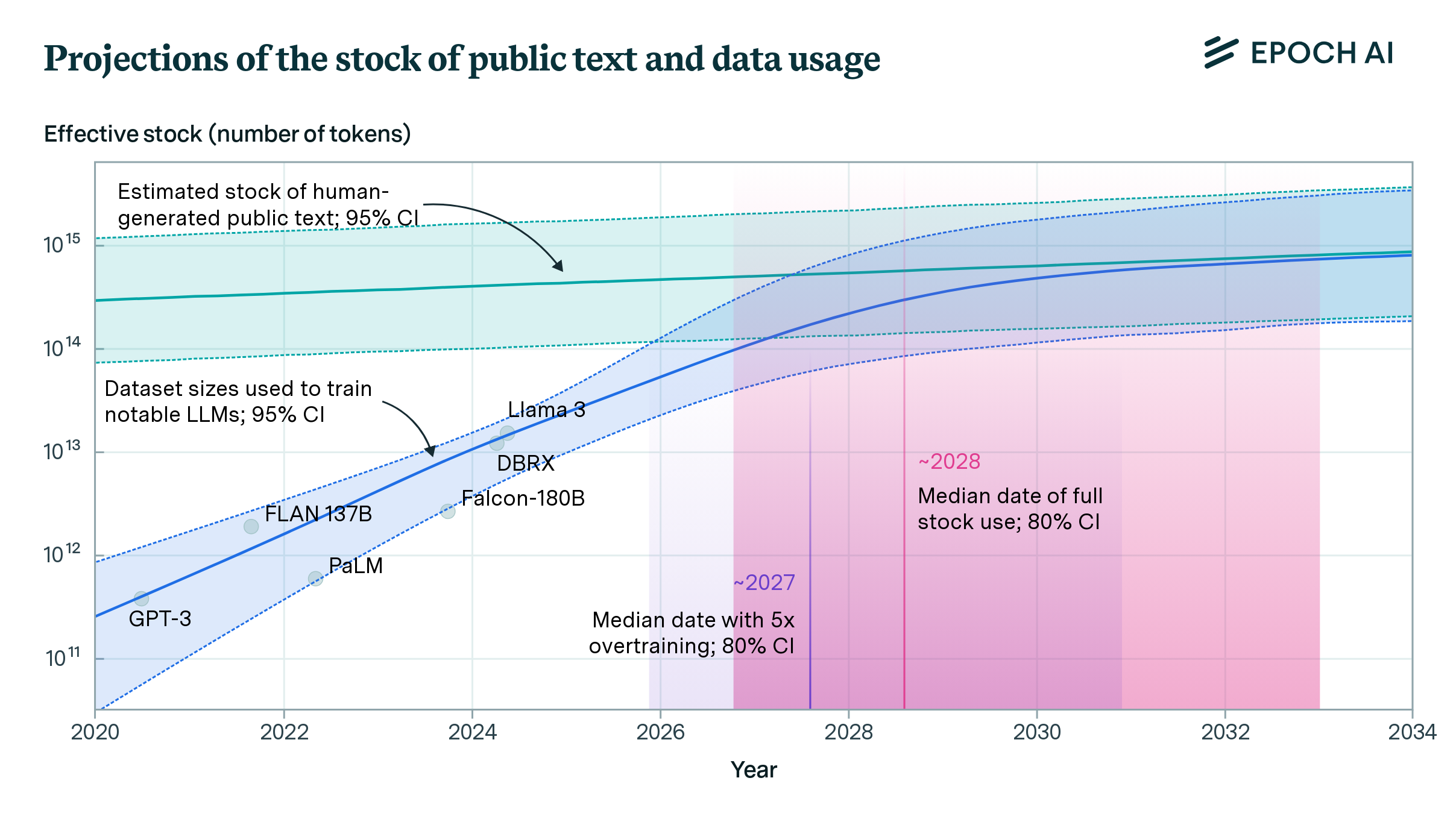
Will we run out of data? Limits of LLM scaling based on human-generated data
We estimate the stock of human-generated public text at around 300 trillion tokens. If trends continue, language models will fully utilize this stock between 2026 and 2032, or even earlier if intensely overtrained.
Largest training dataset used to train an LLM
Stock of data on the internet
Hardware Trends
Computational performance
Lower-precision number formats
Memory capacity
Memory bandwidth
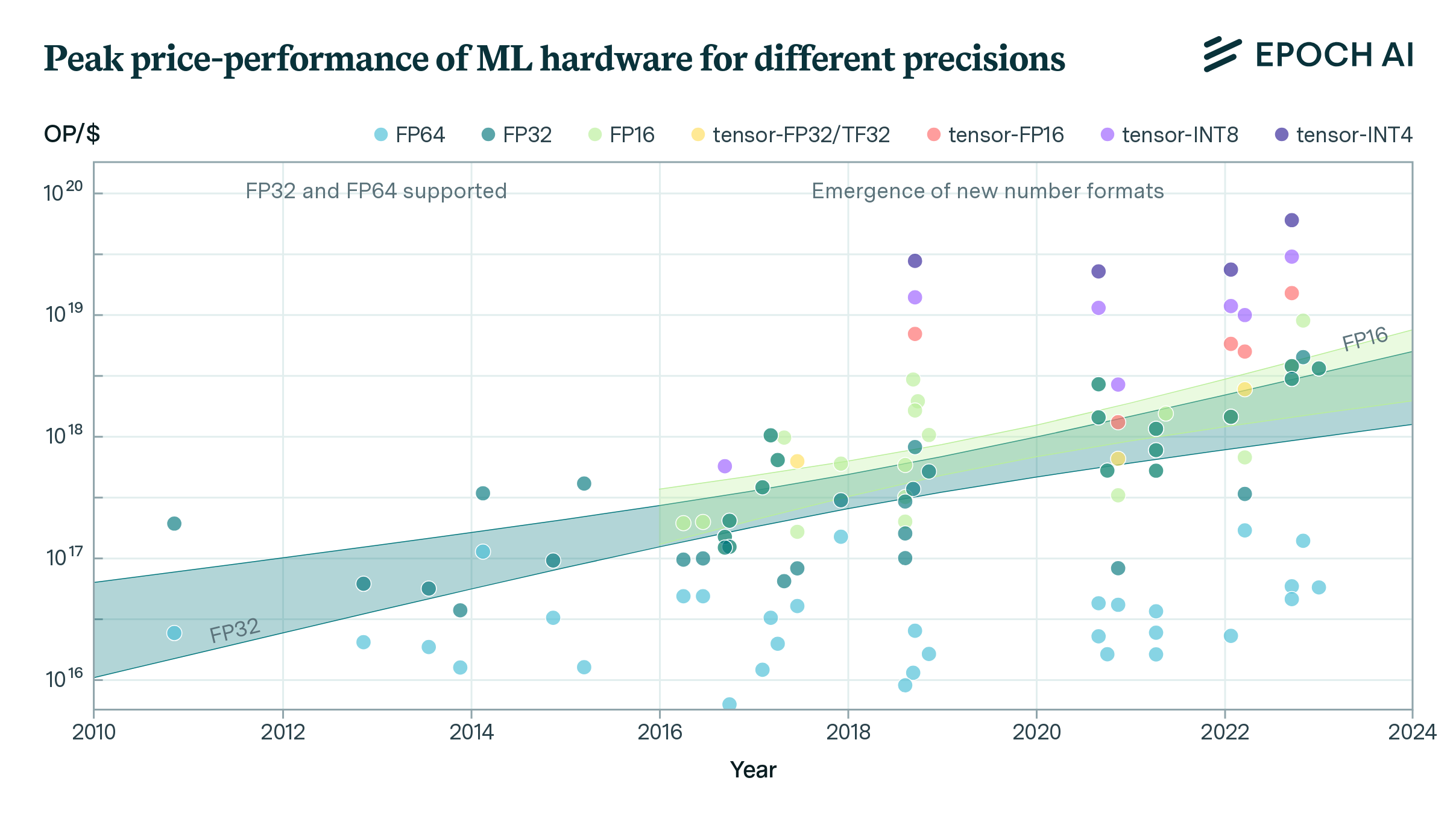
Trends in Machine Learning Hardware
FLOP/s performance in 47 ML hardware accelerators doubled every 2.3 years. Switching from FP32 to tensor-FP16 led to a further 10x performance increase. Memory capacity and bandwidth doubled every 4 years.
Highest performing GPU in Tensor-FP16
Highest performing GPU in INT8
Algorithmic Progress
Compute-efficiency in language models
Compute-efficiency in computer vision models
Contribution of algorithmic innovation
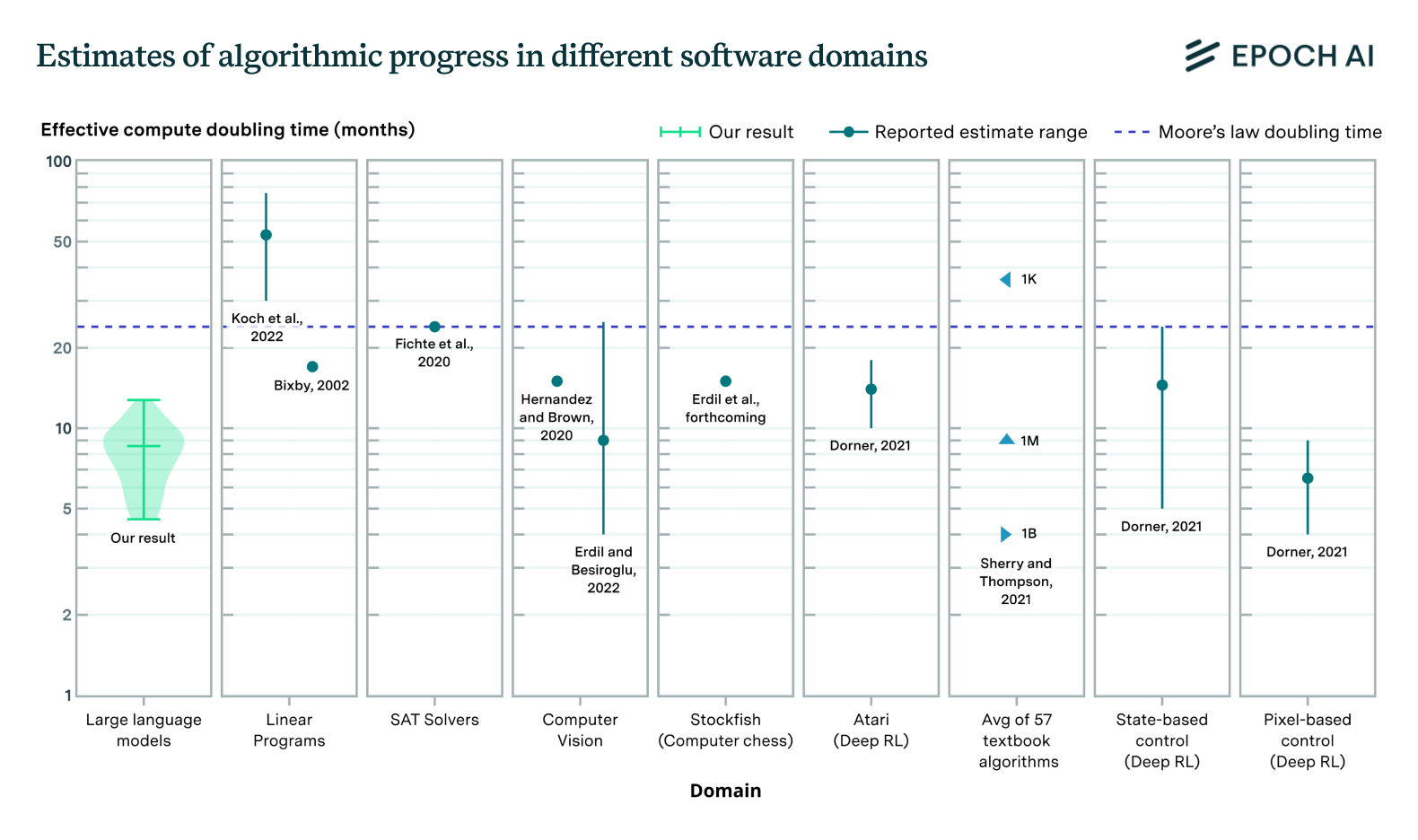
Algorithmic Progress in Language Models
Progress in language model performance surpasses what we’d expect from merely increasing computing resources, occurring at a pace equivalent to doubling computational power every 5 to 14 months.
Chinchilla scaling laws
Investment Trends
Training costs
Hardware acquisition costs
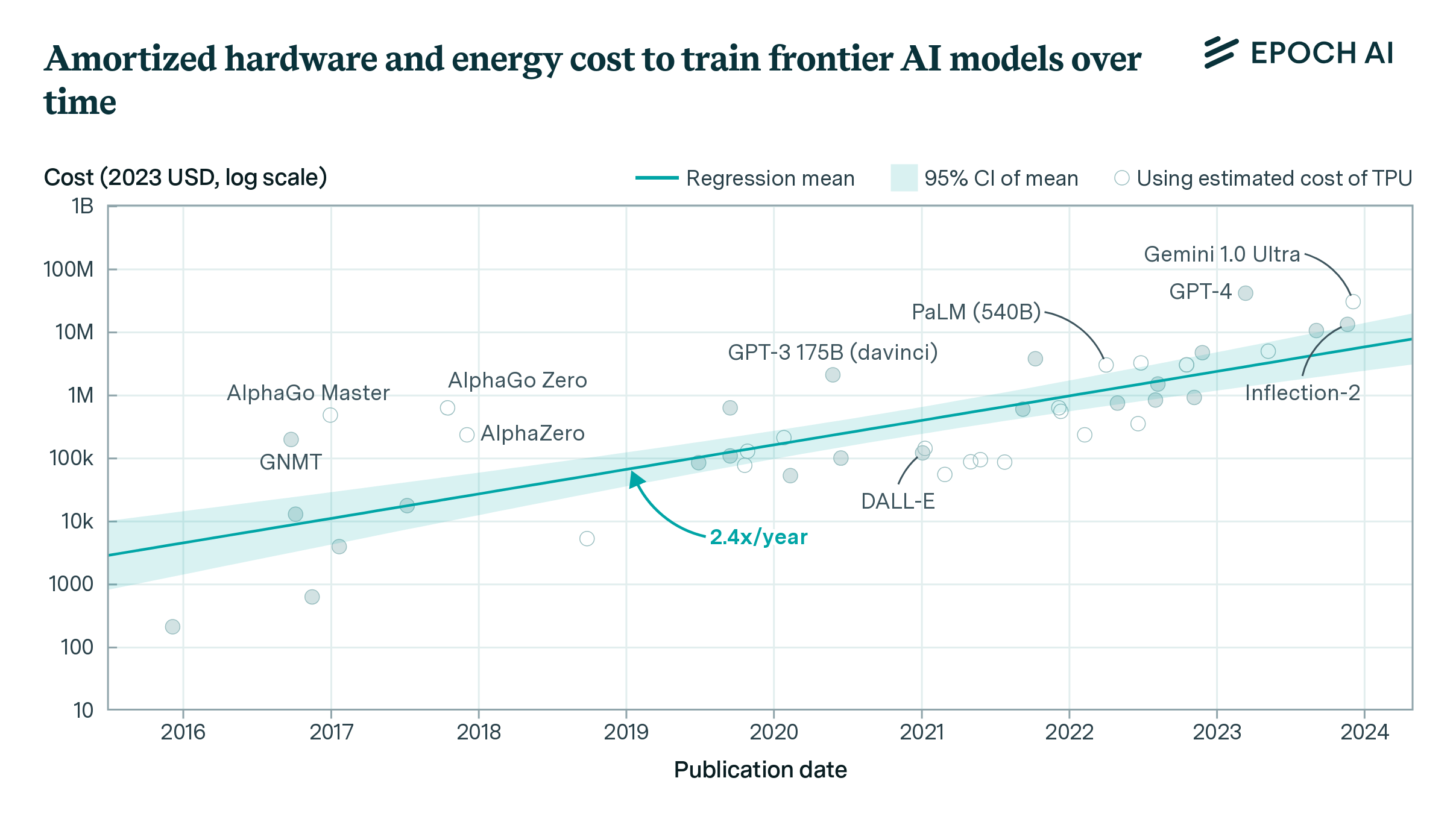
How Much Does It Cost to Train Frontier AI Models?
The cost of training frontier AI models has grown by a factor of 2 to 3x per year for the past eight years, suggesting that the largest models will cost over a billion dollars by 2027.
Most expensive AI model
Hardware acquisition cost for the most expensive AI model

Biological Models
Training compute
Key DNA sequence database
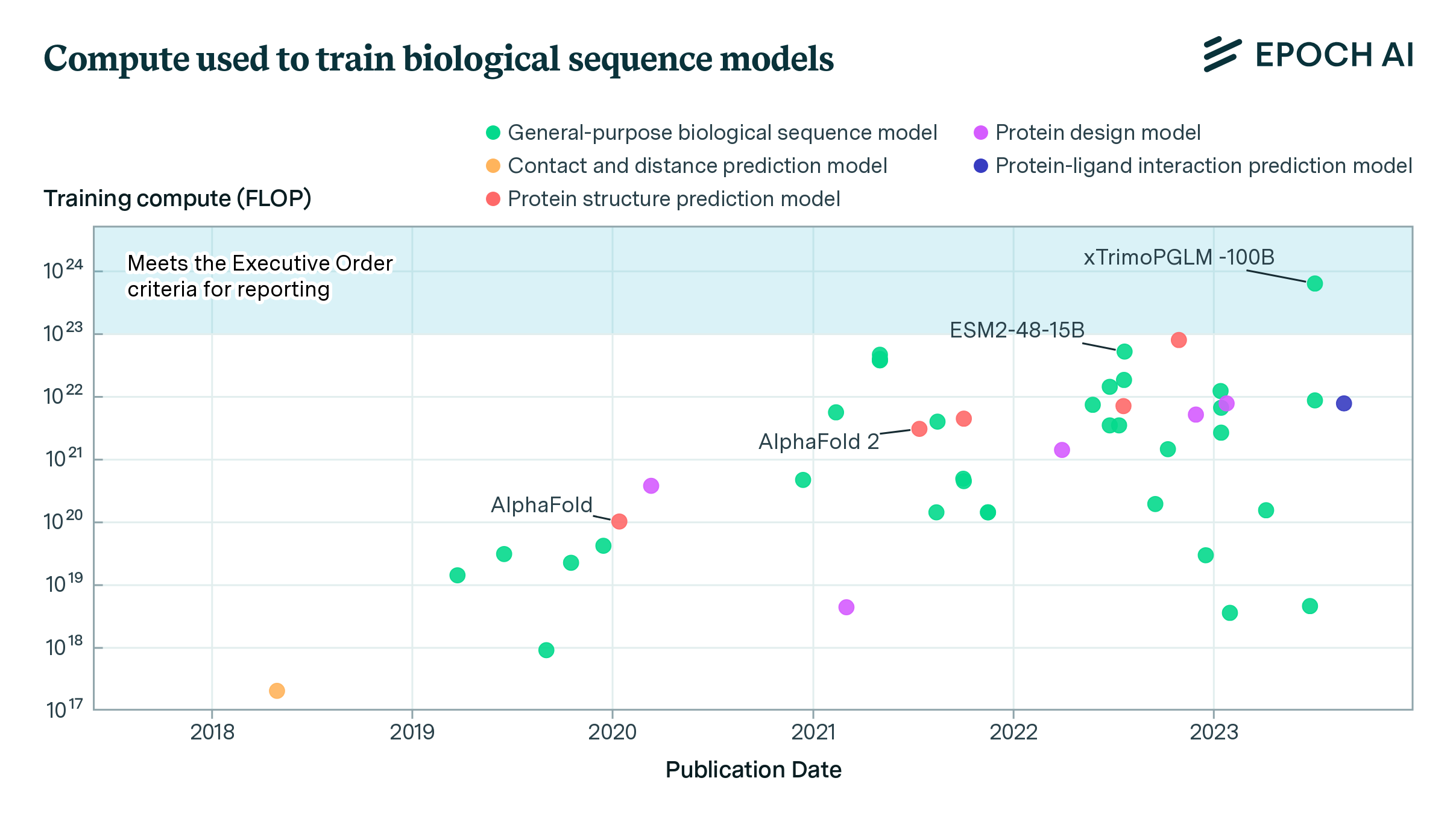
Biological Sequence Models in the Context of the AI Directives
The expanded Epoch database now includes biological sequence models, revealing potential regulatory gaps in the White House’s Executive Order on AI and the growth of the compute used in their training.
Most compute-intensive biological sequence model
Protein sequence data
Acknowledgements
We thank Tom Davidson, Lukas Finnveden, Charlie Giattino, Zach Stein-Perlman, Misha Yagudin, Jai Vipra, Patrick Levermore, Carl Shulman, Ben Bucknall and Daniel Kokotajlo for their feedback.
Several people have contributed to the design and maintenance of this dashboard, including Jaime Sevilla, Pablo Villalobos, Anson Ho, Tamay Besiroglu, Ege Erdil, Ben Cottier, Matthew Barnett, David Owen, Robi Rahman, Lennart Heim, Marius Hobbhahn, David Atkinson, Keith Wynroe, Christopher Phenicie, Nicole Maug, Aleksandar Kostovic, Alex Haase, Robert Sandler, Edu Roldan and Andrew Lucas.
Citation

Cite this work as
Epoch AI (2023), "Key Trends and Figures in Machine Learning". Published online at epochai.org. Retrieved from: 'https://epochai.org/trends' [online resource]BibTeX citation
@misc{epoch2023aitrends,
title="Key Trends and Figures in Machine Learning",
author={{Epoch AI}},
year=2023,
url={https://epochai.org/trends},
note={Accessed: }
}