Will We Run Out of Data? Limits of LLM Scaling Based on Human-Generated Data
We estimate the stock of human-generated public text at around 300 trillion tokens. If trends continue, language models will fully utilize this stock between 2026 and 2032, or even earlier if intensely overtrained.
Published
Resources
Introduction
Scaling has been a key factor driving progress in AI. Models are growing in parameters and being trained on increasingly enormous datasets, leading to exponential growth in training compute, and dramatic increases in performance. For example, five years and four orders of magnitude of compute separate the barely coherent GPT-2 with the powerful GPT-4.
So far, AI developers have not faced major limits to scaling beyond simply procuring AI chips, which are scarce but rapidly growing in supply. If chips are the only bottleneck, then AI systems are likely to continue growing exponentially in compute and expanding the frontier of capabilities. As such, a key question in forecasting AI progress is whether inputs other than raw compute could become binding constraints.
In particular, scaling requires growing training datasets. The most powerful AI systems to date are language models that are primarily trained on trillions of words of human-generated text from the internet. However, there is only a finite amount of human-generated data out there, which raises the question of whether training data could become the main bottleneck to scaling.
In our new paper, we attempt to shed light on this question by estimating the stock of human-generated public text data, updating our 2022 analysis of this topic.
Results
We find that the total effective stock of human-generated public text data is on the order of 300 trillion tokens, with a 90% confidence interval of 100T to 1000T. This estimate includes only data that is sufficiently high-quality to be used for training, and accounts for the possibility of training models for multiple epochs.1
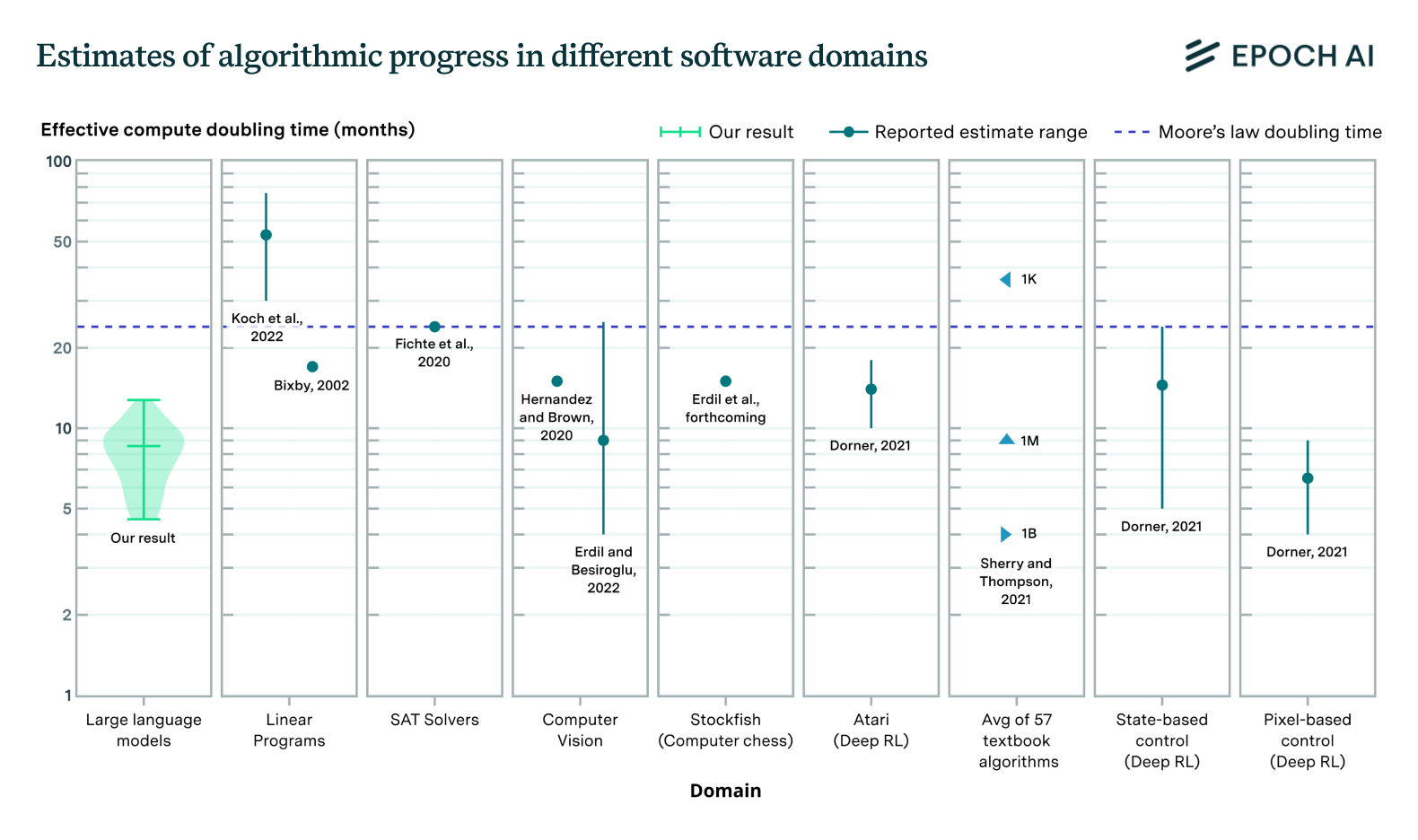
We report estimates of the stocks of several types of data in Figure 1.
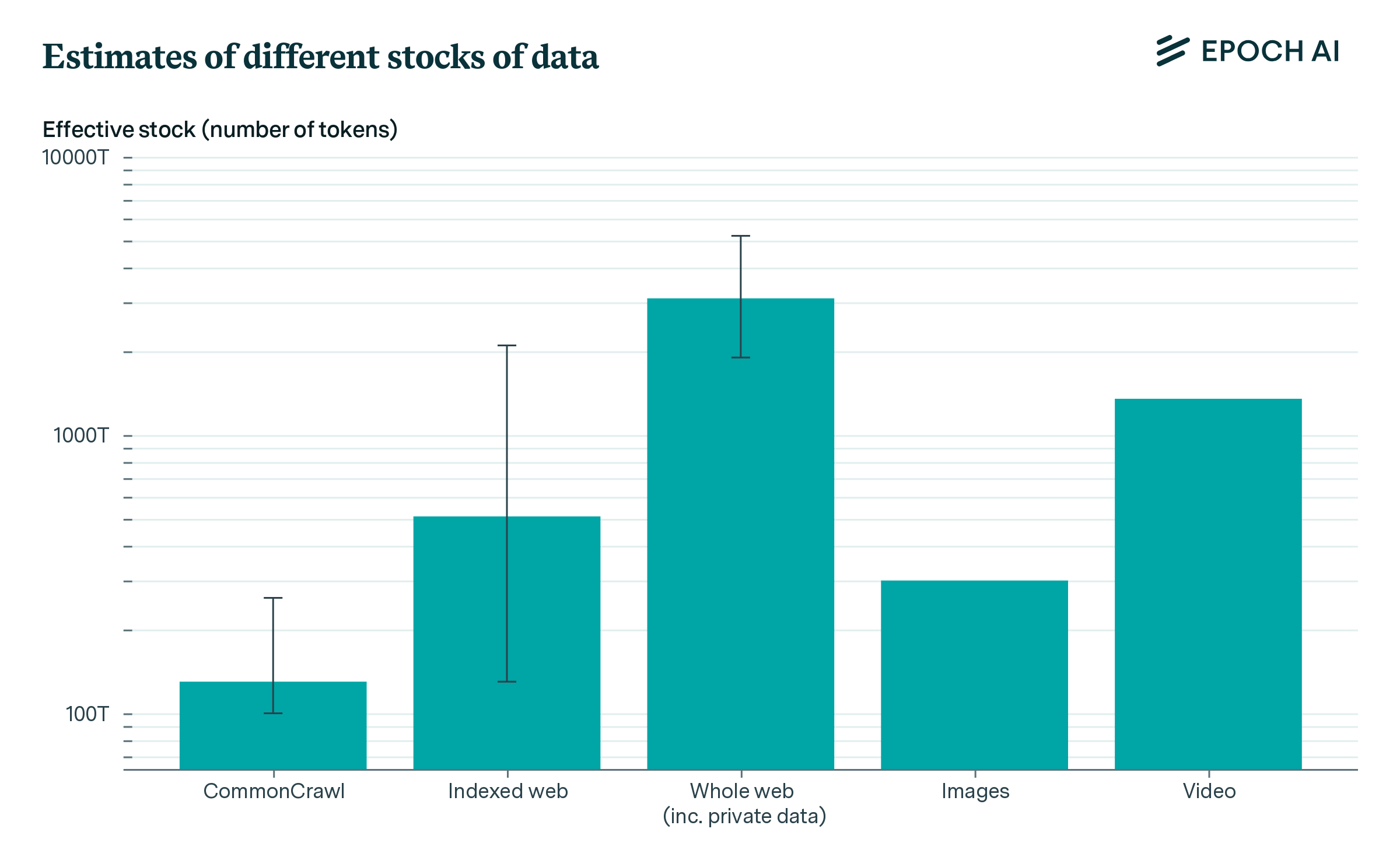
Figure 1: Estimates of different stocks of data, in tokens.2 These estimates do not take data quality or multi-epoch training into account.
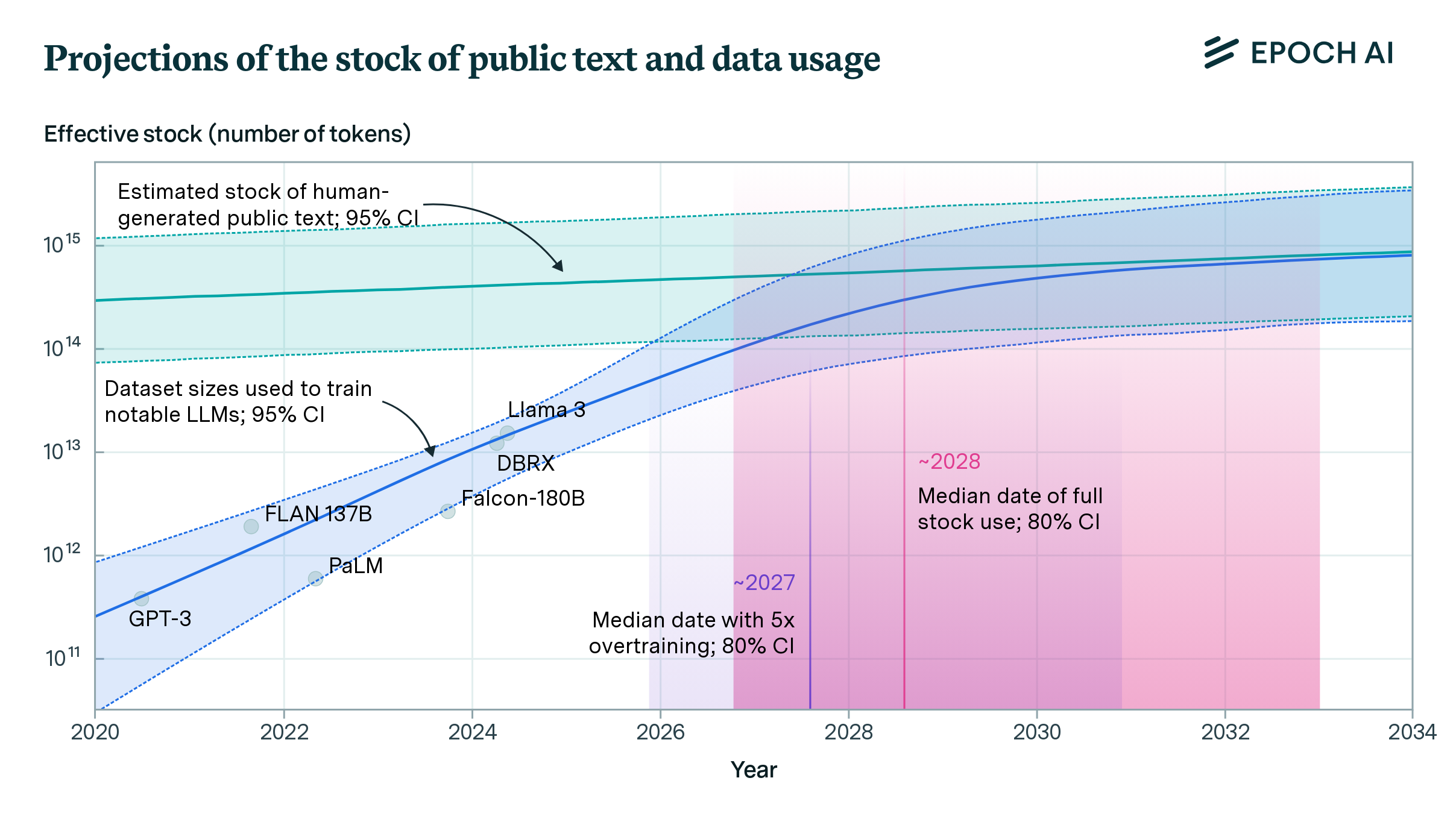
Given our estimate of the data stock, we then forecast when this data would be fully utilized. We develop two models of dataset growth. One simply extrapolates the historical growth rate in dataset sizes, and the other accounts for our projection of training compute growth and derives the corresponding dataset size (more below). Our overall projection, shown in Figure 2, comes from combining these two models. Our 80% confidence interval is that the data stock will be fully utilized at some point between 2026 and 2032.
However, the exact point in time at which this data would be fully utilized depends on how models are scaled. If models are trained compute-optimally,3 there is enough data to train a model with 5e28 floating-point operations (FLOP), a level we expect to be reached in 2028 (see Figure 2). But recent models, like Llama 3, are often “overtrained” with fewer parameters and more data so that they are more compute-efficient during inference.4
We develop a simplified model of revenues and costs, and solve it to find the scaling policy that would maximize AI developers profits. Depending on how demand for AI inference changes with the performance of the model, we find it might make sense to overtrain models up to 100x.
We then make projections of future dataset sizes using these profit-maximizing policies, as shown in Figure 3. If models are overtrained by a modest factor of 5x, the stock of data will be fully used by 2027, but if they are overtrained by 100x, the stock of data will be fully used by 2025. For context, Llama 3-70B was overtrained by 10x.
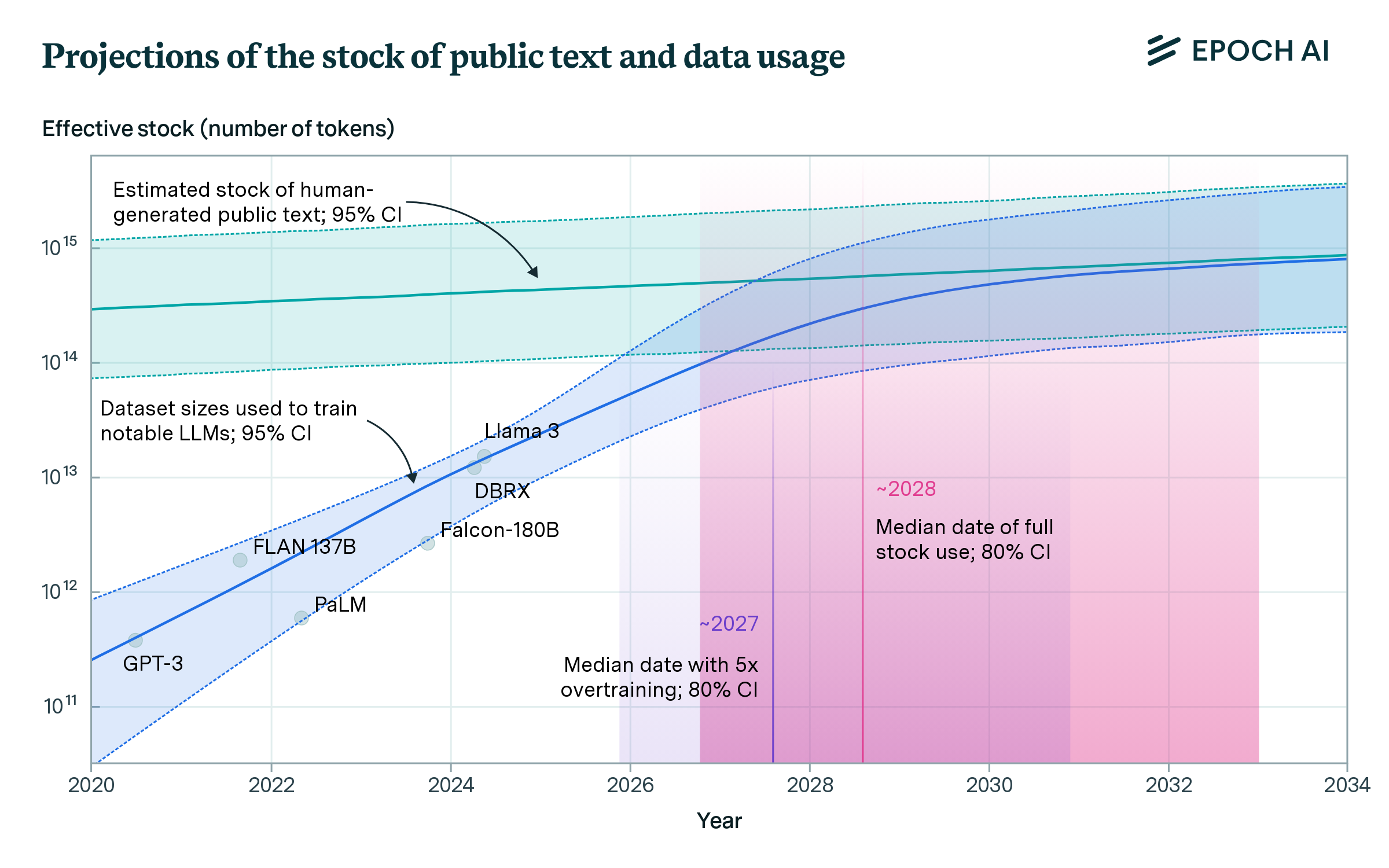
Figure 2: Projection of effective stock of human-generated public text and dataset sizes used to train notable LLMs. Individual dots represent dataset sizes of specific notable models. The dataset size projection is a mixture of an extrapolation of historical trends and a compute-based projection that assumes models are trained compute-optimally.
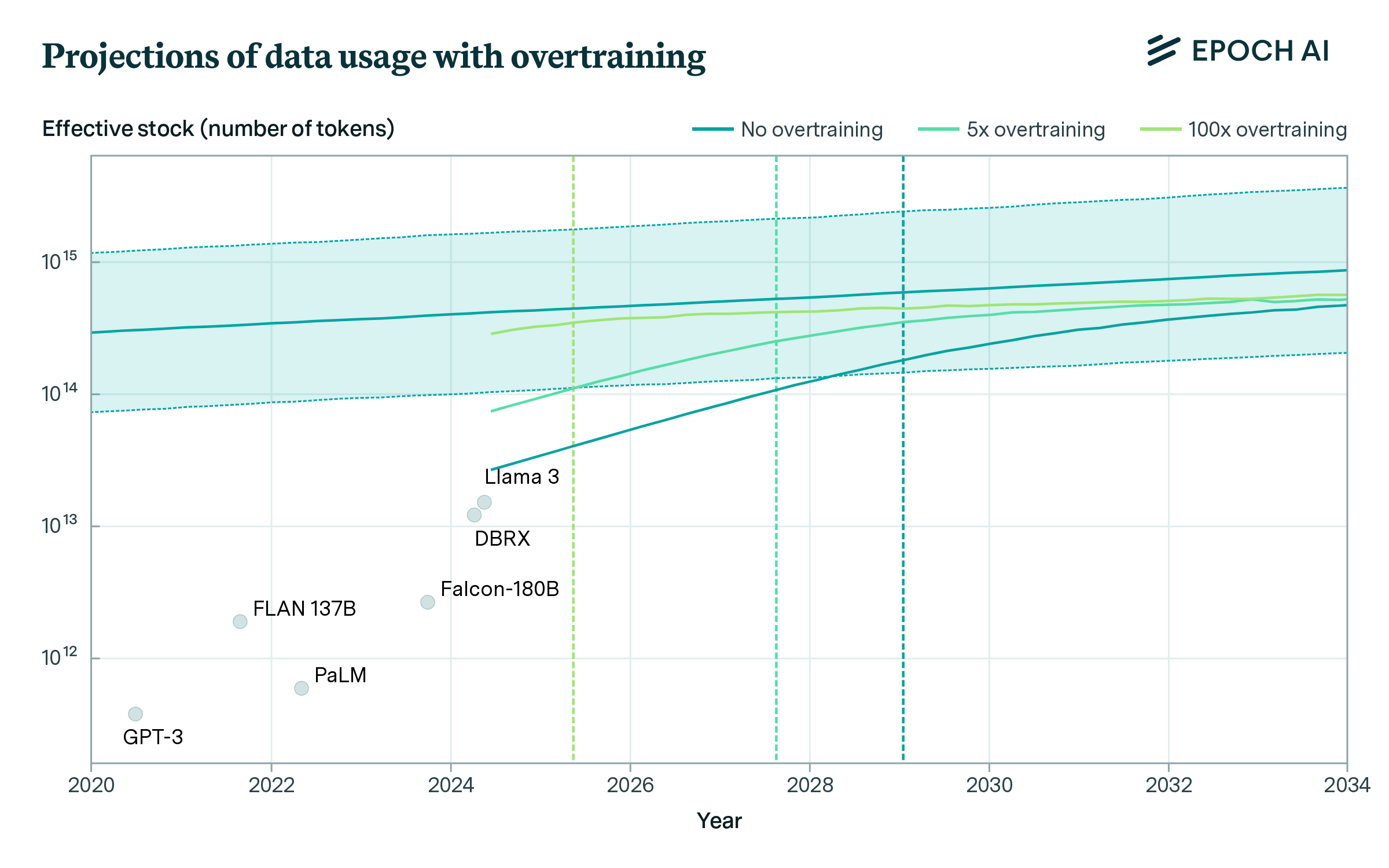
Figure 3: Projections of future dataset sizes according to three different scaling policies. Depending on the degree of overtraining, the stock is fully used between 2025 and 2030.
Comparison with previous estimates
Our 2022 paper predicted that high-quality text data would be fully used by 2024, whereas our new results indicate that might not happen until 2028. This discrepancy is due to a difference in methodology and the incorporation of recent findings that have altered our understanding of data quality and model training.
In our previous work, we modeled high-quality data as consisting of roughly an even mix of scraped web data and human-curated corpora such as published scientific papers or books. This produced an estimate of about 10 trillion tokens of high-quality data. However, later results indicated that web data can outperform curated corpora, if it is filtered carefully (Penedo et al., 2023). Since web data is much more abundant than manually curated data, this led to a 5x increase in our estimate of the stock of high-quality data.
Another recent finding that challenged our old assumptions is that models can be trained on several epochs without significant degradation (Muennighoff et al., 2023). This discovery suggests that the same dataset can be used multiple times during training, effectively increasing the amount of data available to the model. As a result, this further expanded our estimate of the effective stock by a factor of 2-5x, contributing to the revised projection of when the data stock might be fully utilized.
The combination of these findings – the effectiveness of carefully filtered web data and the ability to train models on multiple epochs—has led to a substantial increase in our estimate of the available high-quality data stock. This, in turn, has pushed back our projected date for when this data might be fully utilized by language models.
Discussion
There are many types of data beyond human-generated publicly-available text data, including images and video, private data such as instant messaging conversations, and AI-generated synthetic data. We chose to focus on public human text data for three reasons:
- Text is the main modality used to train frontier models and is more likely to become a key bottleneck, as other modalities are easier to generate (in the case of images and video) or have not demonstrated their usefulness for training LLMs (for example, in the case of astronomical or other scientific data).
- AI-generated synthetic data is not yet well understood, and has only been shown to reliably improve capabilities in relatively narrow domains like math and coding.
- Non-public data, like instant messages, seems unlikely to be used at scale due to legal issues, and because it is fragmented over several platforms controlled by actors with competing interests.
Even if models come to be trained on all available public human text data, this would not necessarily lead to a complete halt of progress in model capabilities. One way in which progress can continue is if models grow in terms of parameters while keeping their dataset size constant, a strategy called “undertraining”.5 While undertraining can deliver the equivalent of up to two additional orders of magnitude of compute-optimal scaling (see Figure 4), it is expected to eventually lead to a plateau.
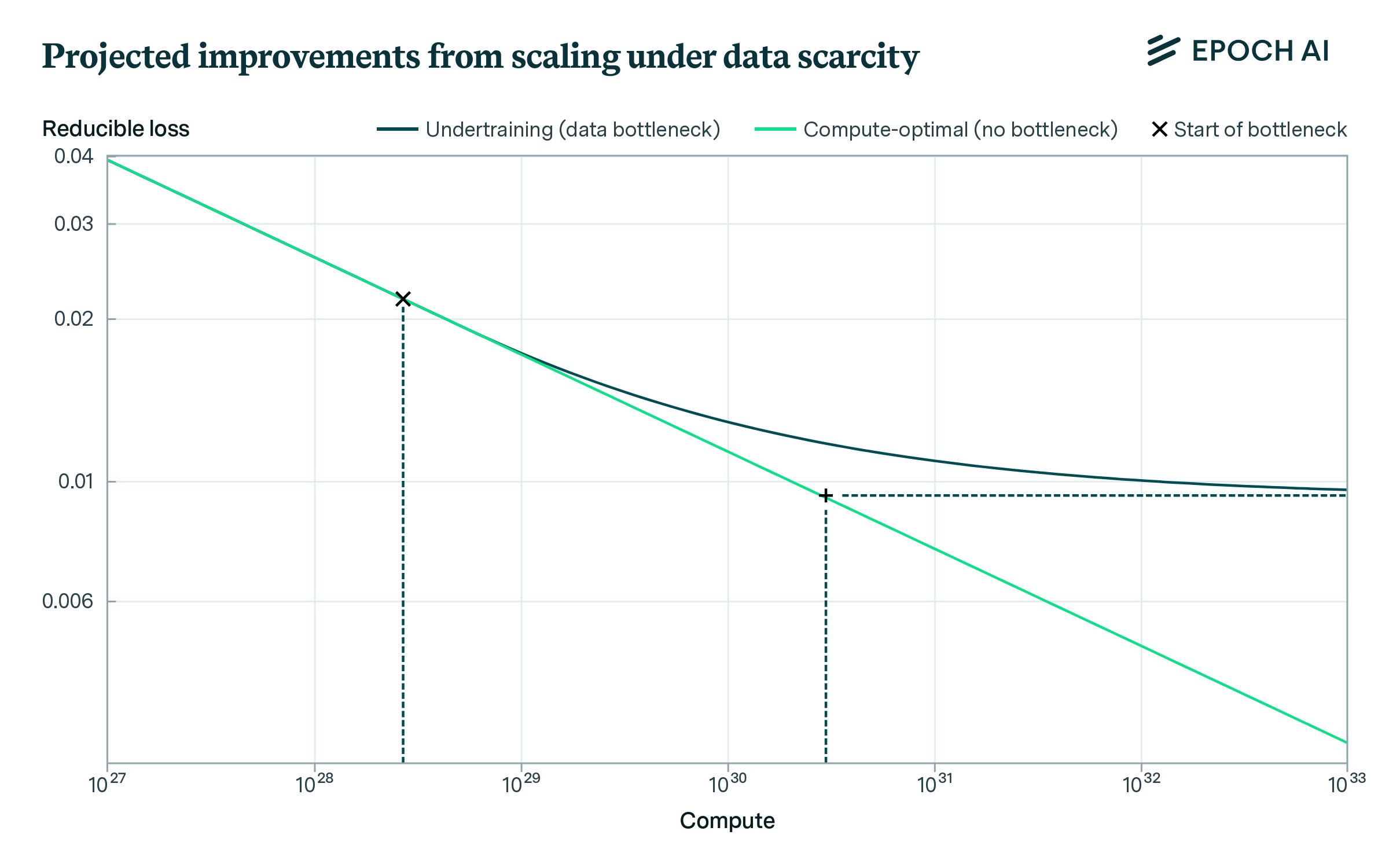
Figure 4: A toy model of a data bottleneck based on the scaling laws derived by Hoffmann et al. (2022). Assuming the dataset size is fixed at 300T tokens, the gains that can be achieved by undertraining models eventually plateau at a level that is equivalent to ~2 additional orders of magnitude of compute-optimal scaling.
But ultimately, new innovations will be required to maintain progress beyond 2030. While we cannot predict which innovations will succeed, we identify three categories that seem especially relevant: synthetic data, learning from other modalities of data, and data efficiency improvements. As data becomes more scarce relative to compute, the amount of resources dedicated to developing these and other techniques will increase substantially.6 Given this increased level of investment, we expect such efforts to succeed.
For more information, read the full paper on ArXiv https://arxiv.org/abs/2211.04325.
Notes
-
That is, multiple passes through the training dataset. ↩
-
Tokens are pieces of text that are fed into LLMs for processing. A reasonable rule of thumb is that one token corresponds to 0.8 English words on average. In the case of images and video, one image and one second of video are both assumed to correspond to roughly 30 tokens of text. ↩
-
The term “compute-optimal” refers to selecting the size of the model and dataset in a way that results in the best possible performance at a fixed level of training compute. According to Hoffmann et al. (2022), for dense models this is achieved by training models on around 20 tokens for each model parameter. ↩
-
Overtrained models are those that are trained on more data than what is prescribed by compute-optimal scaling laws. Holding training compute constant, overtrained models are more efficient during inference (because they have fewer parameters), at the cost of more data usage and somewhat lower performance. ↩
-
Undertraining is the opposite of overtraining: it reduces the need for data at the cost of lower inference efficiency and a somewhat lower performance at the same level of compute. ↩
-
So far, the amount of money spent by top AI research laboratories in sourcing compute dwarfs the amount spent in sourcing data. If data became a bottleneck, we would expect this situation to reverse. ↩
About the authors






Related posts