A Compute-Based Framework for Thinking About the Future of AI
AI's potential to automate labor is likely to alter the course of human history within decades, with the availability of compute being the most important factor driving rapid progress in AI capabilities.
How should we expect AI to unfold over the coming decades? In this article, I explain and defend a compute-based framework for thinking about AI automation. This framework makes the following claims, which I defend throughout the article:
- The most salient impact of AI will be its ability to automate labor, which is likely to trigger a productivity explosion later this century, greatly altering the course of history.
- The availability of useful compute is the most important factor that determines progress in AI, a trend which will likely continue into the foreseeable future.
- AI performance is likely to become relatively predictable on most important, general measures of performance, at least when predicting over short time horizons.
While none of these ideas are new, my goal is to provide a single article that articulates and defends the framework as a cohesive whole. In doing so, I present the perspective that Epoch AI researchers find most illuminating about the future of AI. Using this framework, I will justify a value of 47% for the probability of Transformative AI (TAI) arriving before 2043.
Summary
The post is structured as follows.
In part one, I will argue that what matters most is when AI will be able to automate a wide variety of tasks in the economy. The importance of this milestone is substantiated by simple models of the economy that predict AI could greatly accelerate the world economic growth rate, dramatically changing our world.
In part two, I will argue that availability of data is less important than compute for explaining progress in AI, and that compute may even play an important role driving algorithmic progress.
In part three, I will argue against a commonly held view that AI progress is inherently unpredictable, providing reasons to think that AI capabilities may be anticipated in advance.
Finally, in part four, I will conclude by using the framework to build a probability distribution over the date of arrival for transformative AI.1
Part 1: Widespread automation from AI
When discussing AI timelines, it is often taken for granted that the relevant milestone is the development of Artificial General Intelligence (AGI), or a software system that can do or learn “everything that a human can do.” However, this definition is vague. For instance, it’s unclear whether the system needs to surpass all humans, some upper decile, or the median human.
Perhaps more importantly, it’s not immediately obvious why we should care about the arrival of a single software system with certain properties. Plausibly, a set of narrow software programs could drastically change the world before the arrival of any monolithic AGI system (Drexler, 2019). In general, it seems more useful to characterize AI timelines in terms of the impacts AI will have on the world. But, that still leaves open the question of what impacts we should expect AI to have and how we can measure those impacts.
As a starting point, it seems that automating labor is likely to be the driving force behind developing AI, providing huge and direct financial incentives for AI companies to develop the technology. The productivity explosion hypothesis says that if AI can automate the majority of important tasks in the economy, then a dramatic economic expansion will follow, increasing the rate of technological, scientific, and economic growth by at least an order of magnitude above its current rate (Davidson, 2021).
A productivity explosion is a robust implication of simple models of economic growth models, which helps explain why the topic is so important to study. What’s striking is that the productivity explosion thesis appears to follow naturally from some standard assumptions made in the field of economic growth theory, combined with the assumption that AI can substitute for human workers. I will illustrate this idea in the following section.2
But first, it is worth contrasting this general automation story with alternative visions of the future of AI. A widely influential scenario is the hard takeoff scenario as described by Eliezer Yudkowsky and Nick Bostrom (Yudkowsky 2013, Bostrom 2014). In this scenario, the impacts of AI take the form of a localized takeoff in which a single AI system becomes vastly more powerful than the rest of the world combined; moreover, this takeoff is often predicted to happen so quickly that the broader world either does not notice it occurring until it’s too late, or the AI cannot otherwise be stopped. This scenario is inherently risky because the AI could afterwards irrevocably impose its will on the world, which could be catastrophic if the AI is misaligned with human values.
However, Epoch AI researchers tend to be skeptical of this specific scenario. Many credible arguments have been given against the hard takeoff scenario (e.g., Christiano 2018, Grace 2018). We don’t think these objections rule out the possibility, but they make us think that a hard takeoff is not the default outcome (<20% probability). Instead of re-hashing the debate, I’ll provide just a few points that we think are important to better understand our views.
Perhaps the most salient reason to expect a hard takeoff comes from the notion of recursive self-improvement, in which an AI can make improvements to itself, causing it to become even better at self-improvement, and so on (Good 1965). However, while the idea of accelerating change resulting from AIs improving AIs seems likely to us, we don’t think there are strong reasons to believe that this recursive improvement will be unusually localized in space. Rather than a single AI agent improving itself, we think this acceleration will probably be more diffuse, and take the form of AIs accelerating R&D in a general sense. We can call this more general phenomenon recursive technological improvement, to distinguish it from the narrow case of recursive self-improvement, in which a single AI “fooms” upwards in capabilities, very quickly outstripping the rest of the world combined (e.g. in a matter of weeks).
There are many reasons for thinking that AI impacts will be diffuse rather than highly concentrated. Perhaps most significantly, if the bottleneck to AI progress is mostly compute rather than raw innovative talent, it seems much harder for initially-powerless AI systems to explode upwards in intelligence without having already taking over the semiconductor industry. Later, in part two, I will support this premise by arguing that there are some prima facie reasons to think that compute is the most important driver of AI progress.
Simple models of explosive growth
In the absence of technological innovation, we might reasonably expect output to scale proportionally to increases in inputs. For example, if you were to double the number of workers, double the number of tools, buildings, and roads that the workers rely on, and so on, then outputs would double as well. That’s what it would mean for returns to scale to be constant.
However, doubling the number of workers also increases the rate of idea production, and thus innovation. This fact is important because of a key insight — often attributed to Paul Romer — that ideas are non-rivalrous. The non-rivalry of ideas means that one person can use an idea without impinging on someone else’s use of that idea. For example, your use of the chain rule doesn’t prevent other people from using the chain rule. This means that doubling the inputs to production should be expected to more than double output, as workers adopt innovations created by others. Surprisingly, this effect is very large even under realistic assumptions in which new ideas get much harder to find over time (Erdil and Besiroglu 2023).
Given increasing returns to scale and the fact that inputs can accumulate and be continually reinvested over time, the semi-endogenous model of economic growth says that we should see a productivity explosion as a consequence of population growth in the long run, tending towards higher levels of economic growth over time.
This model appears credible because it offers a simple explanation for the accelerated growth in human history, while also providing a neat explanation for why this acceleration appeared to slow down sometime in the mid-20th century.
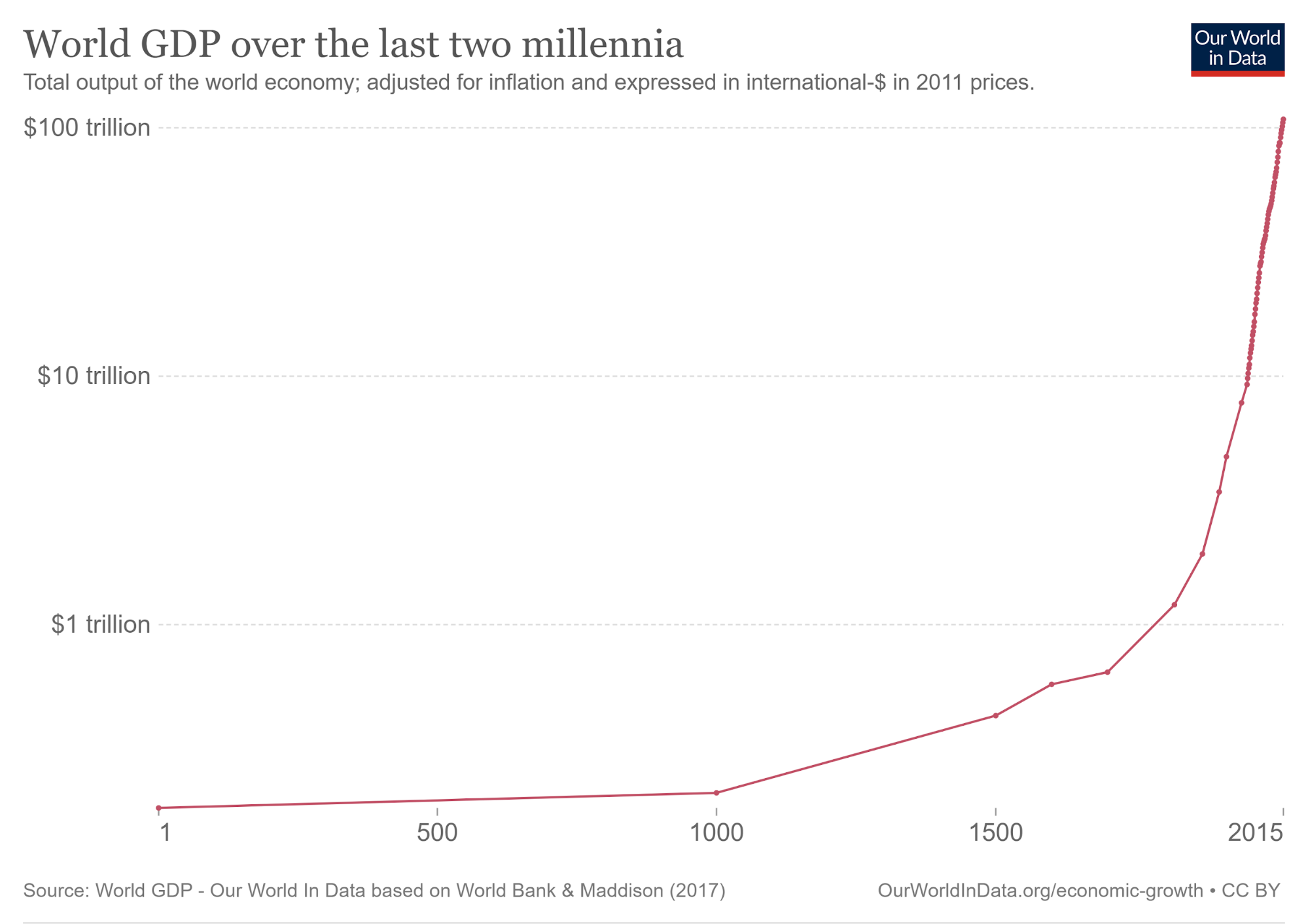
Plot from AI Impacts.
The slowdown we observed around the mid-20th century straightforwardly follows from the semi-endogenous model once the demographic transition is taken into account, which uncoupled the link between population growth and economic growth, resulting in declining fertility and, ultimately, declining rates of economic growth.
By contrast, since computing hardware manufacturing is not bound by the same constraints as human population growth, an AI workforce can expand very quickly — much faster than the time it takes to raise human children. Perhaps more importantly, software can be copied very cheaply. The ‘population’ of AI workers can therefore expand drastically, and innovate in the process, improving the performance of AIs at the same time their population expands.
It therefore seems likely that, unless we coordinate to deliberately slow AI-driven growth, the introduction of AIs that can substitute for human labor could drastically increase the growth rate of the economy, at least before physical bottlenecks prevent further acceleration, which may only happen at an extremely high level of growth by current standards.
Strikingly, we can rescue the conclusion of explosive growth even if we dispense with the assumption of technological innovation. Consider that Carlsmith (2020) estimated that the human brain uses roughly \(10^{15}\) FLOP per second. If it became possible to design computer software that was as economically useful as the human brain per unit of FLOP, that would suggest we could expand the population of human-equivalent workers as quickly as we can manufacture new computing hardware. Assuming the current price of compute stays constant, at roughly \(4*10^{17}\) FLOP/$, re-investing perhaps 45% of economic output into new computing hardware causes economic growth to exceed 30% in this simple model. Obviously, if FLOP prices decrease over time, this conclusion becomes even stronger.
Of course, knowing that advanced AI can eventually trigger explosive growth doesn’t tell us much about when we should expect that to happen. To predict when this productivity explosion will happen, we’ll need to first discuss the drivers of AI progress.
Part 2: A compute-centered theory of AI automation
There appear to be three main inputs to performance in the current AI paradigm of deep learning: algorithmic progress, compute, and data. Leaving aside algorithmic progress for now, I’ll present a prima facie case that compute will ultimately be most important for explaining progress in the foreseeable future.
At the least, there seem to be strong reasons to think that growth in compute played a key role in sustaining AI progress in the past. Almost all of the most impressive AI systems in the last decade, such as AlphaGo Zero and GPT-4, were trained using an amount of compute that would have been prohibitively expensive in, say, 1980. Historically, many AI researchers believed that creating general AI would be more about coming up with the right theories of intelligence, but over and over again, researchers eventually found that impressive results only came after the price of computing fell far enough that simple, “blind” techniques began working (Sutton 2019).
In the last year, we’ve seen predictions that the total amount of data available on the internet could constrain AI progress in the near future. However, researchers at Epoch AI believe there are a number of strong reasons to doubt these predictions.
Most importantly, according to recent research on scaling laws, if compute is allocated optimally during training runs, we should expect parameter counts and training data to grow at roughly the same rate (Hoffmann et al. 2022). Since training compute is proportional to the number of parameters times the number of training tokens, this implies that data requirements will grow at roughly half the growth rate of compute. As a result, you should generally expect compute to be a greater bottleneck relative to data.
More detailed investigations have confirmed this finding, with Villalobos et al. 2022 estimating that there is enough low-quality internet data to sustain current trends in dataset size growth until at least 2030 and possibly until 2050. 3
It is also possible that we can generate nearly unlimited synthetic data, borrowing compute to generate any necessary data (Huang et al. 2022, Eldan and Li 2023). Another possibility is that training on multi-modal data, such as video and images, could provide the necessary “synergy,” where performance on one modality is improved by training on the other and vice versa (Aghajanyan et al. 2023). This would allow models to be trained at much larger scales without being bottlenecked by limited access to textual data. This possibility is lent credibility by research showing that training on multiple modalities may be more beneficial for learning concepts than training on text alone, above a certain scale.
Broadly speaking, researchers at Epoch AI currently think that the total availability of data will not constrain general AI progress in the foreseeable future. Nonetheless, the idea of a general data bottleneck is important to distinguish from the idea that AI will be bottlenecked by data on particular tasks. While we don’t seem likely to run out of internet data in the medium-term future, it seems relatively more likely that widespread automation will be bottlenecked by data on a subset of essential tasks that require training AI on scarce, high-quality data sources.
If we become bottlenecked by essential but hard-to-obtain data sources, then AI progress will be constrained until these bottlenecks are lifted, delaying the impacts of AI. Nonetheless, the possibility of a very long delay, such as one lasting 30 years or more, appears less plausible in light of recent developments in language models.
For context, in the foundation models paradigm, models are trained in two stages, consisting of a pre-training stage in which the model is trained on a vast, diverse corpus, and a fine-tuning stage in which the model is trained on a narrower task, leveraging its knowledge from the pre-training data (Bommasani et al. 2021). The downstream performance of foundation models seems to be well-described by a scaling law for transfer, as a function of pre-training data size, fine-tuning data size, and the transfer gap (Hernandez et al. 2021, Mikami et al. 2021). The transfer gap is defined as the maximum possible benefit of pre-training.
If the transfer gap from one task to another is small, then compute is usually more important for achieving high performance than fine-tuning data. That’s because, if the transfer gap is small, better performance can be efficiently achieved by simply training longer on the pre-training distribution with more capacity, and transferring more knowledge to the fine-tuning task. Empirically, it seems that the transfer gap between natural language tasks is relatively small since large foundation models like GPT-4 can obtain state-of-the-art performance on a wide variety of tasks despite minimal task-specific fine-tuning (OpenAI 2023).
Of course, the transfer gap between non-language tasks may be larger than what we’ve observed for language tasks. In particular, the transfer gap from simulation to reality in robotics may be large and hard to close, which many roboticists have claimed before (e.g., Weng 2019). However, there appear to be relatively few attempts to precisely quantify the size of the transfer gap in robotics, and how it’s changing over time for various tasks (Paull 2020). Until we better understand the transfer gap between robotic tasks, it will be hard to make confident statements about what tasks might be limited more by data than compute.
That said, given the recent impressive results in language models, it is likely that the transfer gap between intellectual tasks is not prohibitively large. Therefore, at least for information-based labor, compute rather than data will be the more important bottleneck when automating tasks. Since nearly 40% of jobs in the United States can be performed entirely remotely, and these jobs are responsible for a disproportionate share of US GDP (Neiman et al. 2020), automating even purely intellectual tasks would plausibly increase growth in output many-fold, having a huge effect on the world.
What about algorithmic progress?
The above discussion paints an incomplete picture of AI progress, as it neglects the role of algorithmic progress. Algorithmic progress lowers the amount of training compute necessary to achieve a certain level of performance over time and, in at least the last decade, it’s been very rapid. For example, Erdil and Besiroglu 2022 estimated that the training compute required to reach a fixed level of performance on ImageNet has been cutting in half roughly every nine months, albeit with wide uncertainty over that value.
In fact, algorithmic progress has been found to be similarly as important as compute for explaining progress across a variety of different domains, such as Mixed-Integer Linear Programming, SAT solvers, and chess engines – an interesting coincidence that can help shed light on the source of algorithmic progress (Koch et al. 2022, Grace 2013). From a theoretical perspective, there appear to be at least three main explanations of where algorithmic progress ultimately comes from:
- Theoretical insights, which can be quickly adopted to improve performance.
- Insights whose adoption is enabled by scale, which only occurs after there’s sufficient hardware progress. This could be because some algorithms don’t work well on slower hardware, and only start working well once they’re scaled up to a sufficient level, after which they can be widely adopted.
- Experimentation in new algorithms. For example, it could be that efficiently testing out all the reasonable choices for new potential algorithms requires a lot of compute.
Among these theories, (1) wouldn’t help to explain the coincidence in rates mentioned earlier. However, as noted by, e.g., Hanson 2013, theories (2) and (3) have no problem explaining the coincidence since, in both cases, what ultimately drove progress in algorithms was progress in hardware. In that case, it appears that we once again have a prima facie case that compute is the most important factor for explaining progress.
Nonetheless, since this conclusion is speculative, I recommend we adopt it only tentatively. In general, there are still many remaining uncertainties about what drives algorithmic progress and even the rate at which it is occurring.
One important factor affecting our ability to measure algorithmic progress is the degree to which algorithmic progress on one task generalizes to other tasks. So far, much of our data on algorithmic progress in machine learning has been on ImageNet. However, there seem to be two ways of making algorithms more efficient on ImageNet. The first way is to invent more efficient learning algorithms that apply to general tasks. The second method is to develop task-specific methods that only narrowly produce progress on ImageNet.
We care more about the rate of general algorithmic progress, which in theory will be overestimated by measuring the rate of algorithmic progress on any specific narrow task. This consideration highlights one reason to think that estimates overstate algorithmic progress in a general sense.
Part 3: Predictability of AI performance
Even if compute is the ultimate driver of progress in machine learning, with algorithmic progress following in lockstep, in order to forecast when to expect tasks to be automated, we first need some way of mapping training compute to performance.
Fortunately, there are some reasons to think that such a method can be developed. Despite some claims that AI performance is inherently unpredictable as a function of scale, there are reasons to think this claim is overstated. Recently, Owen 2023 found that for most tasks he considered, AI performance can be adequately retrodicted by taking into account upstream loss as predicted by neural scaling laws. This approach was unique because it leveraged more information than prior research, which mostly tried to retrodict performance as a function of model scale, leaving aside the role of training data size.
Perhaps the most significant barrier standing in the way of predicting model performance is the existence of emergent abilities, defined as abilities that suddenly appear at certain model scales and thus cannot be predicted by extrapolating performance from lower scales (Wei et al. 2022). There is currently an active debate about the prevalence and significance of emergent abilities, with some declaring that supposedly emergent abilities are mostly a mirage (Schaeffer et al. 2023).
Overgeneralizing a bit, at Epoch AI we are relatively more optimistic that AI performance is predictable, at least in the near-term future. While this is a complex debate relying on a number of underexplored lines of research, we have identified some preliminary reasons for optimism.
Why predicting AI performance may be tractable
For many examples of emergence, it appears to result from the fact that performance on the task is inherently discontinuous. For example, there is a discrete difference between being unable to predict the next number in the sequence produced by the middle-square algorithm, and being able to predict the next number perfectly (which involves learning the algorithm). As a result, it is not surprising that models might learn this task suddenly at some scale.
However, most tasks that we care about automating, such as scientific reasoning, do not take this form. In particular, it seems plausible that for most important intellectual tasks, there is a smooth spectrum between “being able to reason about the subject at all” and “being able to reason about the subject perfectly.” This model predicts that emergence will mostly occur on tasks that won’t lead to sudden jumps in our ability to automate labor.
Moreover, economic value typically does not consist of doing only one thing well, but rather doing many complementary things well. It appears that emergence is most common on narrow tasks rather than general tasks, which makes sense if we view performance on general tasks as an average performance over a collection of narrow subtasks.
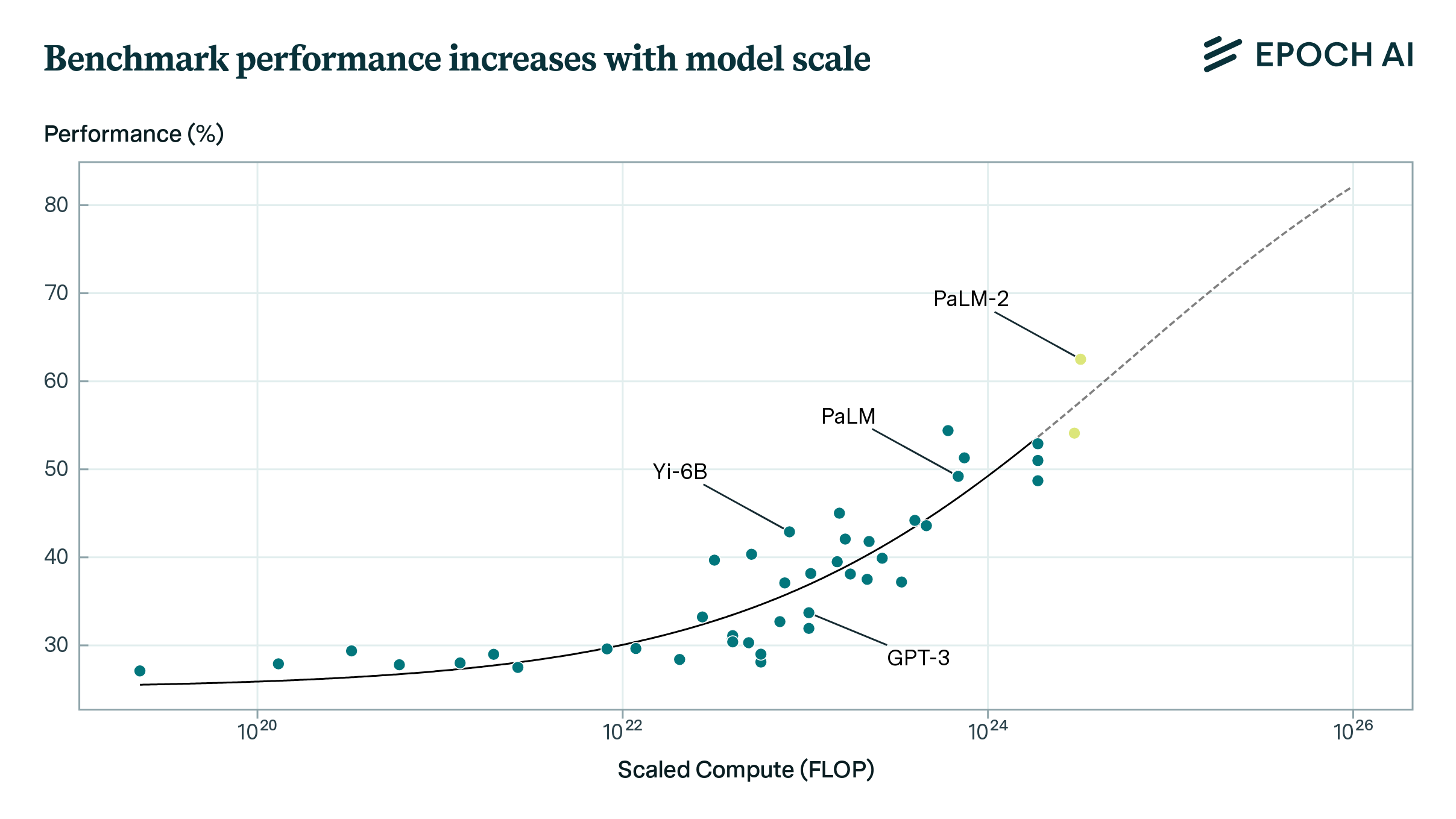
For example, Owen 2023 found that performance appeared to increase smoothly on both an average of BIG-bench and MMLU tasks as a function of scale — both of which included a broad variety of tasks requiring complex reasoning abilities to solve. These facts highlight that we may see very smooth increases in average performance over the collection of all tasks in the economy as a function of scale.
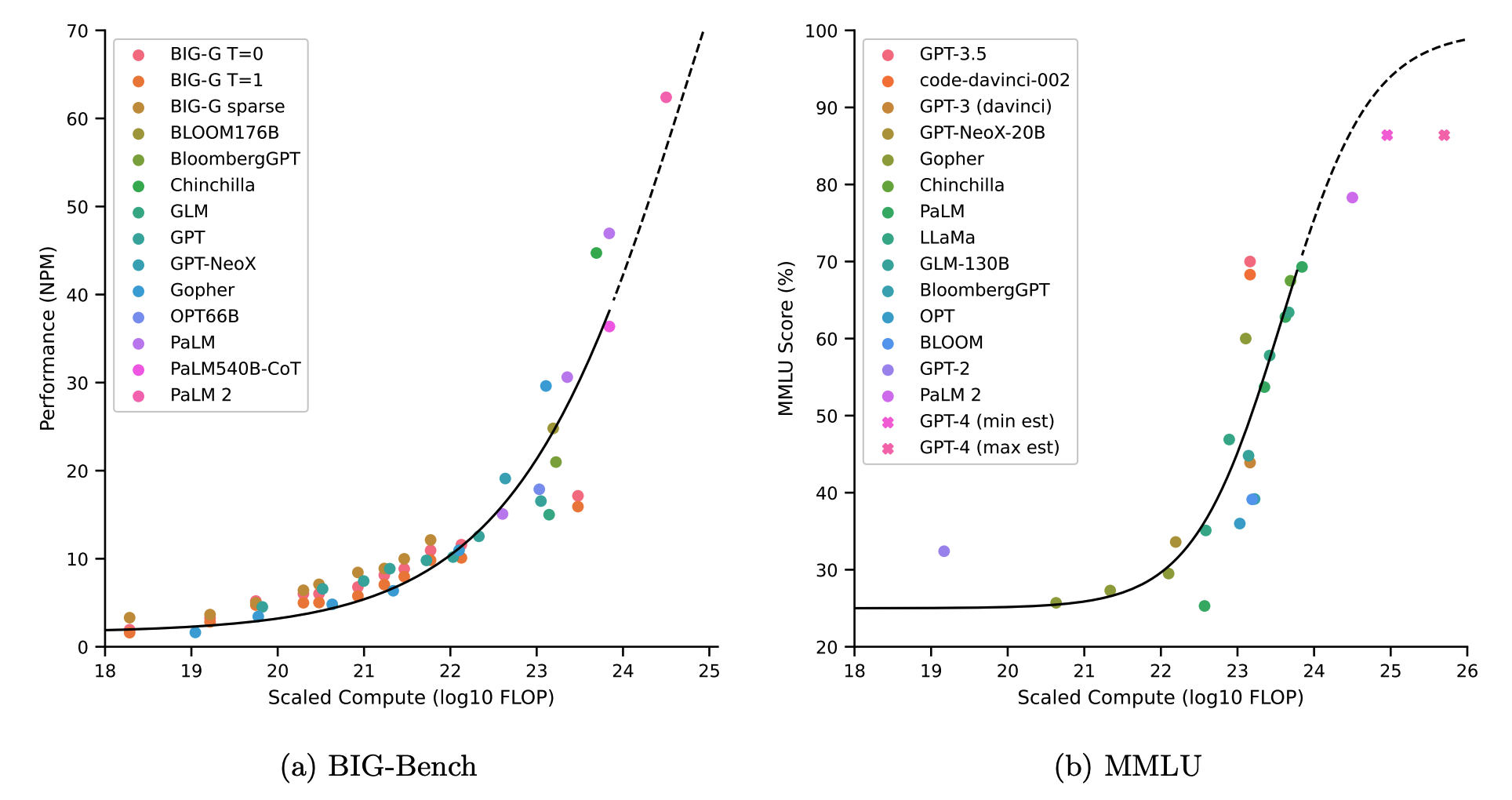
Aggregate benchmark performance is fairly predictable from scale. Graph from Owen 2023.
It is also important to note that additional information beyond training inputs can be incorporated to predict model performance. For example, Jason Wei points out that people have yet to fully explore using surrogate metrics to predict performance on primary metrics. 4
Predicting performance via a theoretical model
Of course, even if AI performance is, in principle, predictable as a function of scale, we lack data on how AIs are currently improving on the vast majority of tasks in the economy, hindering our ability to predict when AI will be widely deployed. While we hope this data will eventually become available, for now, if we want to predict important AI capabilities, we are forced to think about this problem from a more theoretical point of view.
The “Direct Approach” is my name for a theoretical model that attempts to shed some light on the problem of predicting transformative AI that seeks to complement other models, mainly Ajeya Cotra’s biological anchors approach.
The name comes from the fact that it attempts to forecast advanced AI by interpreting empirical scaling laws directly. The following is a sketch of the primary assumptions and results of the model, although we painted a more comprehensive picture in a recent blog post (here’s the full report).
In my view, it seems that the key difficulty in automating intellectual labor is getting a machine to think reliably over long sequences. By “think reliably,” I mean “come up with logical and coherent reasons that cohesively incorporate context and arrive at a true and relevant conclusion.” By “long sequences,” I mean sufficiently long horizons over which the hardest and most significant parts of intellectual tasks are normally carried out.
While this definition is not precise, the idea can be made more amenable to theoretical analysis by introducing a simple framework for interpreting the upstream loss of models on their training distribution.
The fundamental assumption underlying this framework is the idea that indistinguishability implies competence. For example, if an AI is able to produce mathematics papers that are indistinguishable from human-written mathematics papers, then the AI must be at least as competent as human mathematicians. Otherwise, there would be some way of distinguishing the AI’s outputs from the human outputs.
With some further mathematical assumptions, we can use scaling laws to calculate how many tokens it will take, on average, to distinguish between model-generated outputs and outputs in the training distribution, up to some desired level of confidence. 5
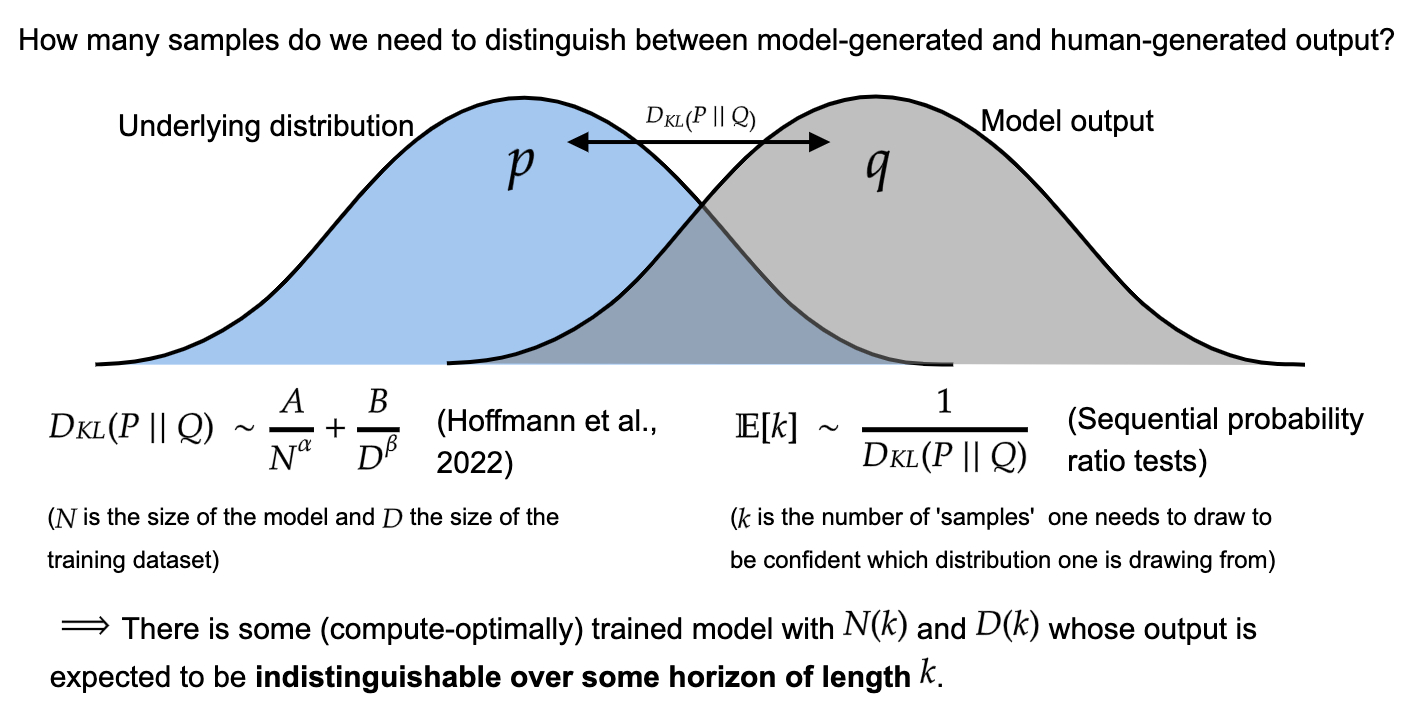
Given the assumption that indistinguishability implies competence, this method permits a way of upper bounding the training compute required to train a model to reach competence over long horizon lengths, i.e., think reliably over long sequences. The model yields an upper bound rather than a direct estimate, since alternative ways of creating transformative AI than emulating human behavior using deep learning may be employed in the future.
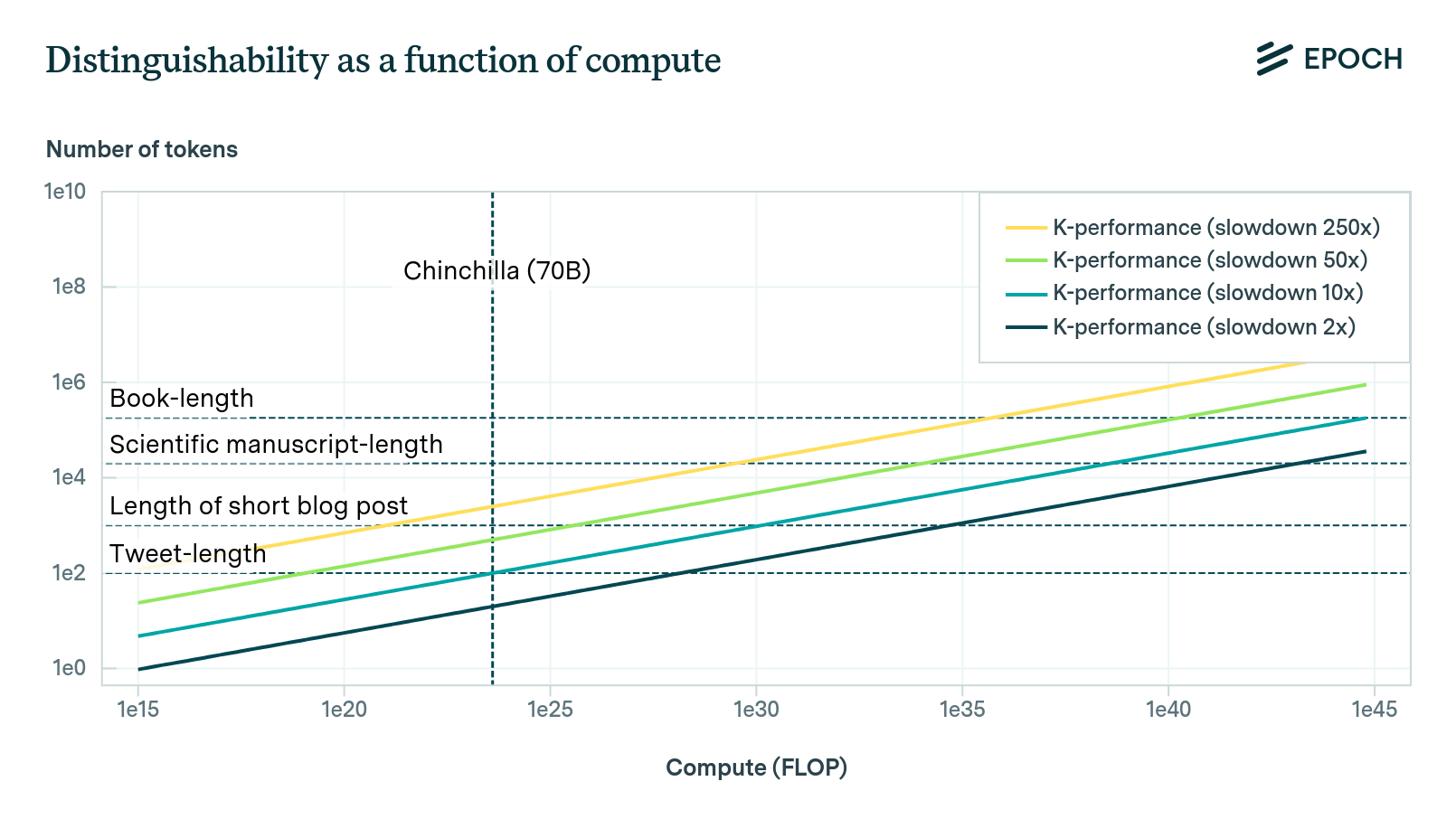
These results can be summarized in the following plot, which shows how distinguishability evolves as a function of compute, given 2022 algorithms. The two essential parameters are (1) the horizon length over which you think language models must be capable of performing reliable high-quality reasoning before they can automate intellectual labor, and (2) the ability of humans to discriminate between outputs relative to an ideal predictor (called the “slowdown” parameter), which sets a bound on how good humans are at picking out “correct” results. Very roughly, lower estimates in the slowdown correspond to thinking that model outputs must be indistinguishable according to a more intelligent judge in order for the model to substitute for real humans, with slowdown=1 being an ideal Bayesian judge.
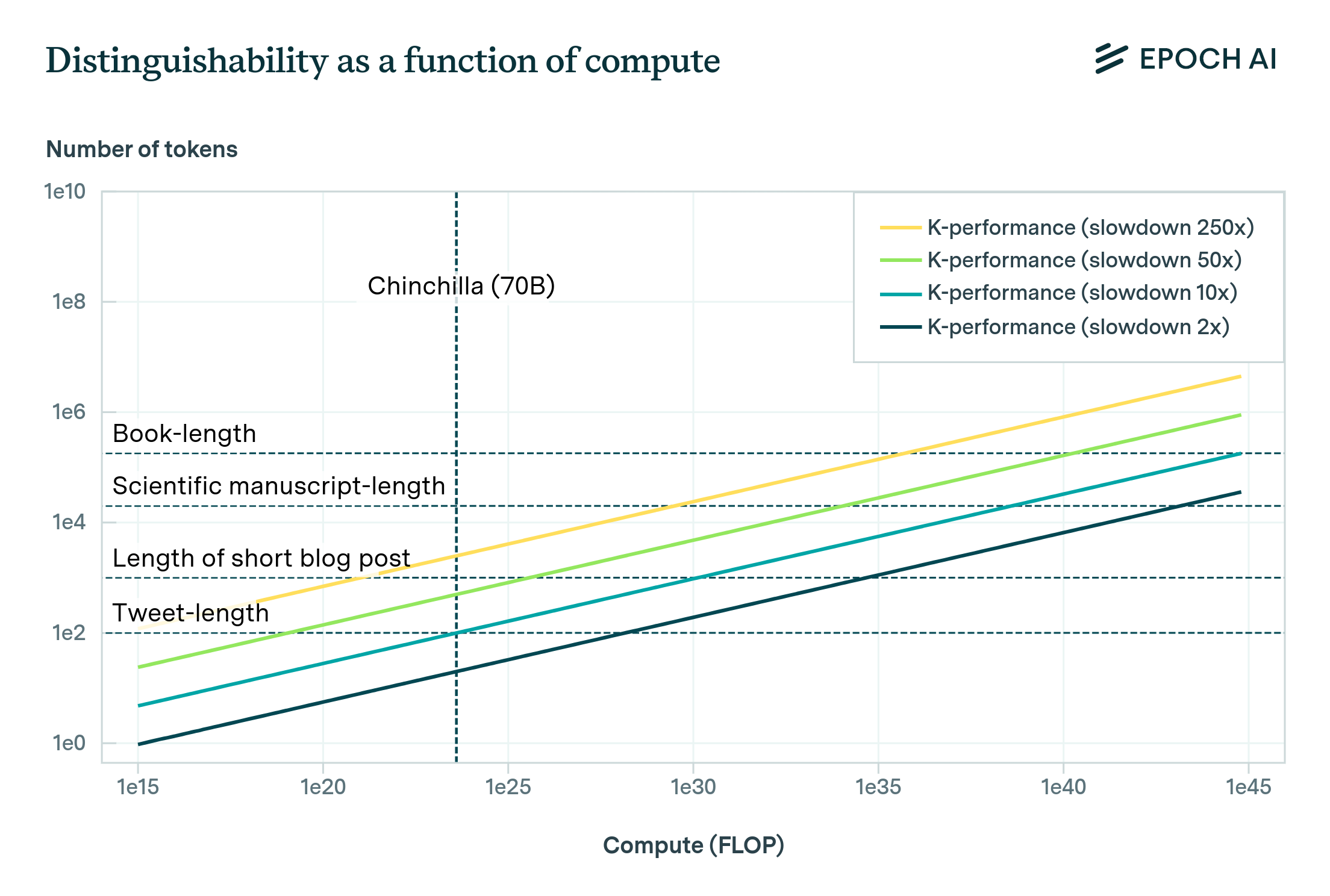
Since the Direct Approach relies on Hoffmann et al. 2022, which trained on general internet data, it might not apply to more complex distributions. That said, in practice, power law scaling has been found to be ubiquitous across a wide variety of data distributions, and even across architectures (Henighan et al. 2020, Tay et al. 2022). While the coefficients in these power laws are often quite different, the scaling exponents appear very similar across data distributions (Henighan et al. 2020). Therefore, although one’s estimate using the Direct Approach may systematically be biased in light of the simplicity of data used in the Hoffmann et al. 2022 study, this bias can plausibly be corrected by simply keeping the bias in mind (for example, by adding 2 OOMs of compute to one’s estimate).
After taking into account this effect, I personally think the Direct Approach provides significant evidence that we can probably train a model to be roughly indistinguishable from a human over sequences exceeding the average scientific manuscript using fewer than ~\(10^{35}\) FLOP, using 2022 algorithms. Notably, this quantity is much lower than the evolutionary anchor of ~\(10^{41}\) FLOP found in the Bio Anchors report; and it’s still technically a (soft) upper bound on the true amount of training compute required to match human performance across a wide range of tasks.
Part 4: Modeling AI timelines
If compute is the central driving force behind AI, and transformative AI (TAI) comes out of something looking like our current paradigm of deep learning, there appear to be a small set of natural parameters that can be used to estimate the arrival of TAI. 1 These parameters are:
- The total training compute required to train TAI
- The average rate of growth in spending on the largest training runs, which plausibly hits a maximum value at some significant fraction of GWP
- The average rate of increase in price-performance for computing hardware
- The average rate of growth in algorithmic progress
Epoch AI has built an interactive model that allows you to plug in your own estimates over these parameters into this model, and obtain a distribution over the arrival of TAI.
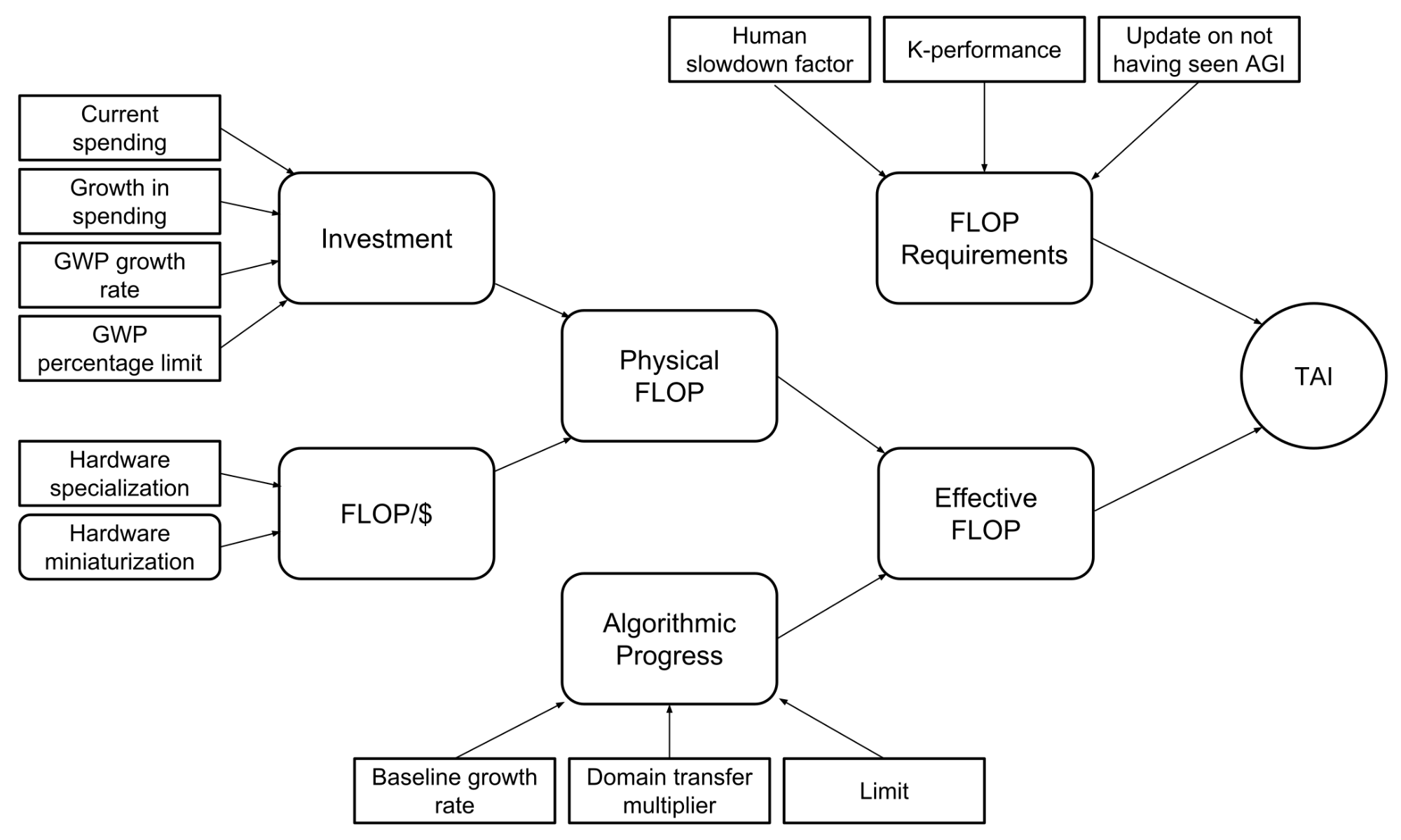
An overview of the interactive model the Epoch AI team has developed.
The interactive model provides some default estimates for each of the parameters. We employ the Direct Approach to estimate a distribution over training compute requirements, although the distribution given by Biological Anchors can easily be used in its place. We use historical data to estimate parameter values. In our experience, given reasonable parameter values, the model typically reveals short or medium-length timelines, in the range of 5-45 years from now.
Nonetheless, this model is conservative for two key reasons. The first is that the Direct Approach only provides an upper bound on the training compute required to train TAI, rather than a direct estimate. The second reason is that this model assumes that the rate of growth in spending, average progress in price-performance, and growth in algorithmic progress will continue at roughly the same rates as in the past. However, if AI expands economic output, it could accelerate the growth rate of each of these parameters.
Addressing how the gradual automation of tasks can speed up the trends so far would take a more careful analysis than we can present in this article. To get an intuition of how strong the effect is, we can study the model developed by Davidson (2023). Under the default parameter choice, full automation is reached around 2040, or 17 years from now. If we disable the effects of partial automation, 6 this outcome is achieved in 2053, or 30 years from now.
Against very short timelines
The compute-centric framework also provides some evidence against very short timelines (<4 years). One simple argument involves looking at the stock of current compute, and seeing whether transformative growth is possible if we immediately received the software for AGI at the compute-efficiency matching the human brain. Note that this is a bold assumption unless you think AGI is imminent, yet even in this case, transformative growth is doubtful in the very short term.
To justify this claim, consider that NVIDIA’s H100 80 GB GPU currently cost about $30k. Given that NVIDIA dominates the AI-relevant hardware market, we can infer that, since its data center revenue is currently on the order of $15 billion per year, and given the compound annual growth rate in its revenue at ~21.3% since 2012 plus rapid hardware progress in the meantime, there’s likely less than $75 billion dollars worth of AI hardware currently in the world right now on par with the H100 80 GB. Since the H100 80 GB GPU can use at most ~4000 TFLOP/s, this means that all the AI hardware in the world together can produce at most about \(10^{22}\) FLOP/s.
The median estimate of the compute for the human brain from Carlsmith (2020) is ~\(10^{15}\) FLOP/s, which means that if we suddenly got the software for AGI with a compute-efficiency matching the human brain, we could at most sustain about 10 million human-equivalent workers given the current stock of hardware.
Even if you are inclined to bump up this estimate by 1-2 orders of magnitude given facts like (1) an AGI could be as productive as a 99th percentile worker, and (2) AGI would never need to sleep and could work at full-productivity throughout the entire day, the potential AGI workforce deployed with current resources would still be smaller than the current human labor force, which is estimated at around 3 billion.
Moreover, nearly all technologies experience a lag between when they’re first developed and when they become adopted by billions of people. Although technology adoption lags have fallen greatly over time, the evidence from recent technologies indicates that the lag for AI will likely be more than a year.
Therefore, it appears that even if we assume that the software for AGI is right around the corner, as of 2023, computer hardware manufacturing must be scaled up by at least an order of magnitude, and civilization will require a significant period of time before AI can be fully adopted. Given that a typical semiconductor fab takes approximately three years to build, it doesn’t seem likely that explosive growth (>30% GWP growth) will happen within the next four years.
Note that I do think very near-term transformative growth is plausible if the software for superintelligence is imminent.7 However, since current AI systems are not close to being superintelligent, it seems that we would need a sudden increase in the rate of AI progress in order for superintelligence to be imminent. The most likely cause of such a sudden acceleration seems to be that pre-superintelligent systems could accelerate technological progress. But, as I have just argued above, a rapid general acceleration of technological progress from pre-superintelligent AI seems very unlikely in the next few years.
My personal AI Timelines
As of May 2023, I think very short (<4 years) TAI timelines are effectively ruled out (~1%) under current evidence, given the massive changes that would be required to rapidly deploy a giant AI workforce, and the arguments against hard takeoff, which I think are strong. I am also inclined to cut some probability away from short timelines given the lack of impressive progress in general-purpose robotics so far, which seems like an important consideration given that the majority of labor in the world currently requires a physical component. That said, assuming no substantial delays or large disasters such as war in the meantime, I believe that TAI will probably arrive within 15 years.8 My view here is informed by my distribution over TAI training requirements, which is centered somewhere around \(10^{32}\) FLOP using 2023 algorithms with a standard deviation of ~3 OOMs.9
Unconditionally, after considering all potential delays (including regulation, which I think is likely to be substantial) and model uncertainty, my overall median TAI timeline is more like 20 years from now, with a long tail extending many decades into the future.
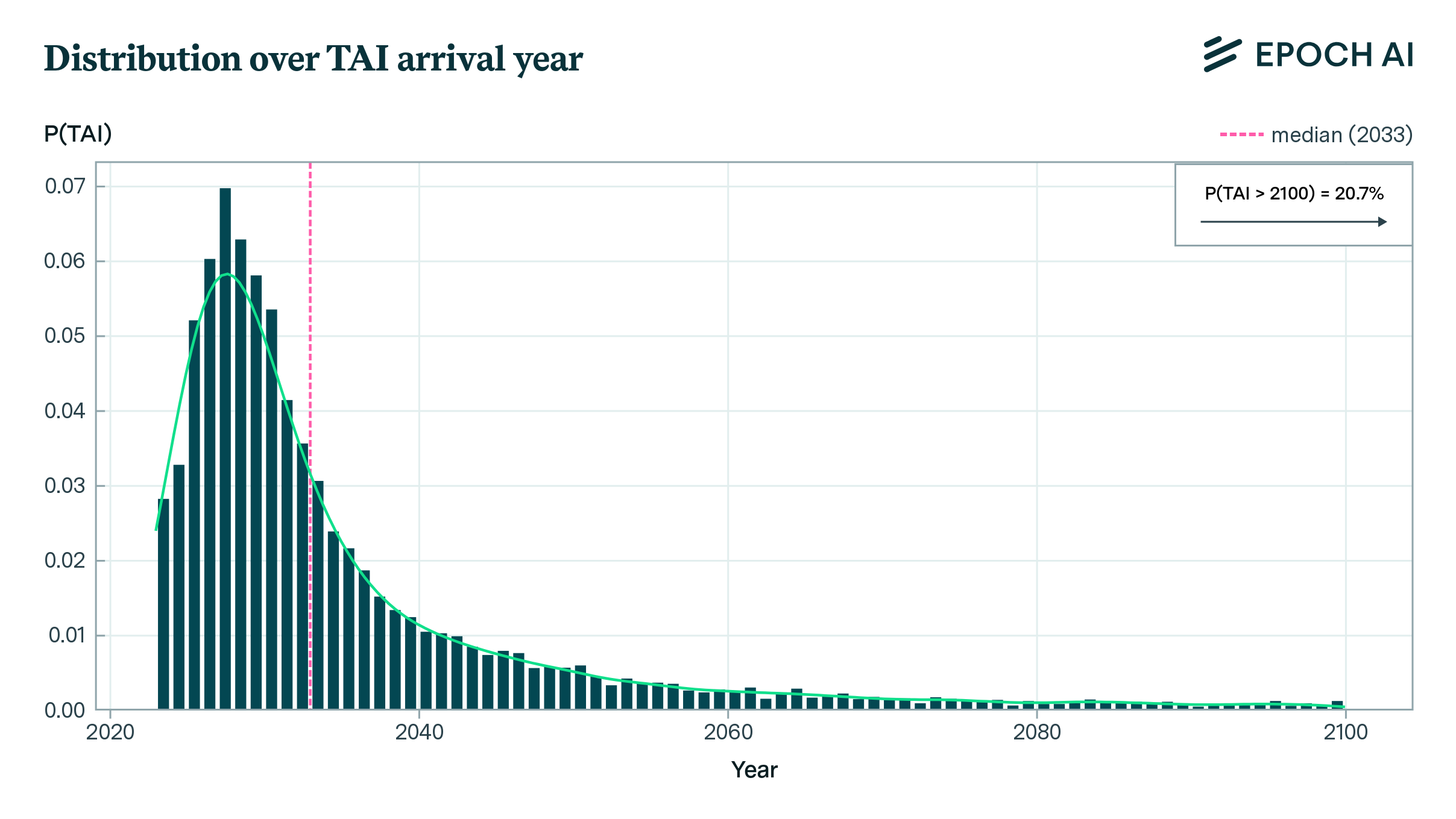
To sum up what I think all this evidence points to, I plotted a probability distribution to represent my beliefs over the arrival of TAI below. Note the fairly large difference between the median (2045) and the mode (2029).10
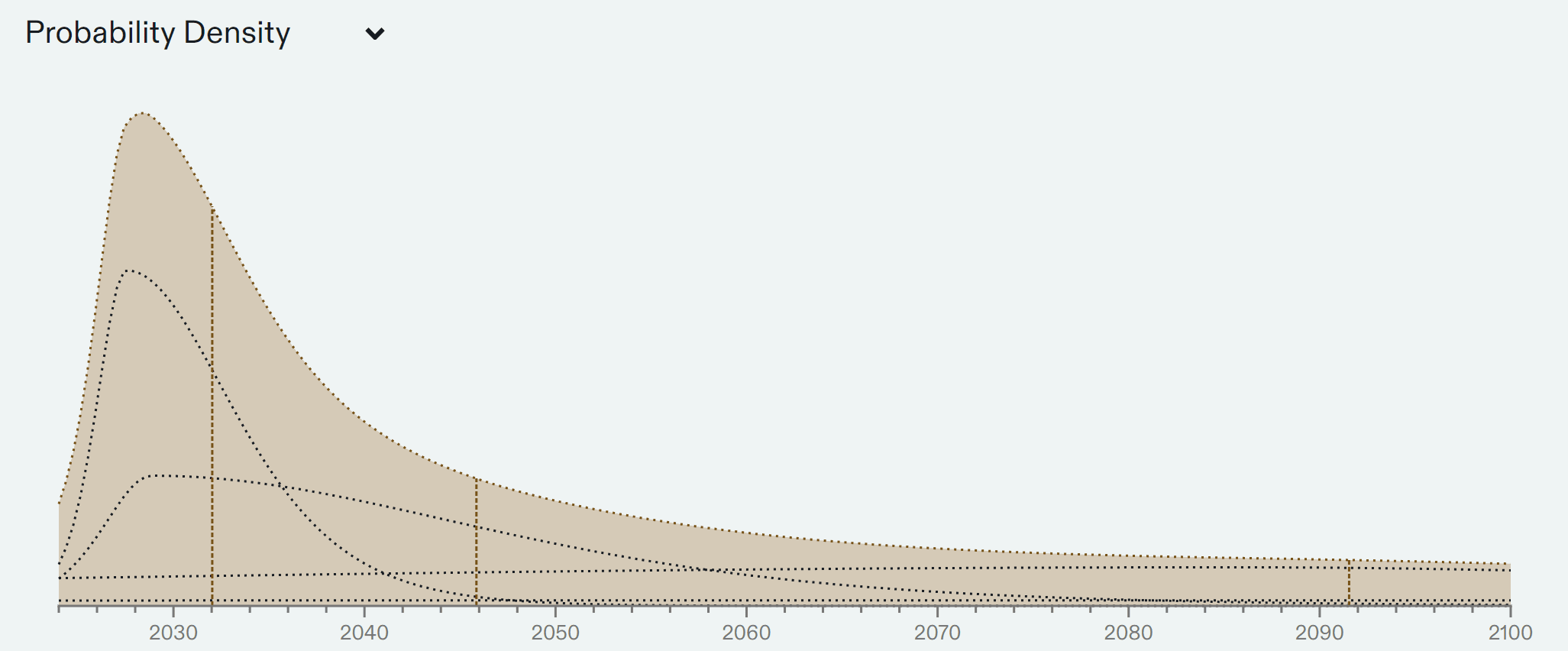
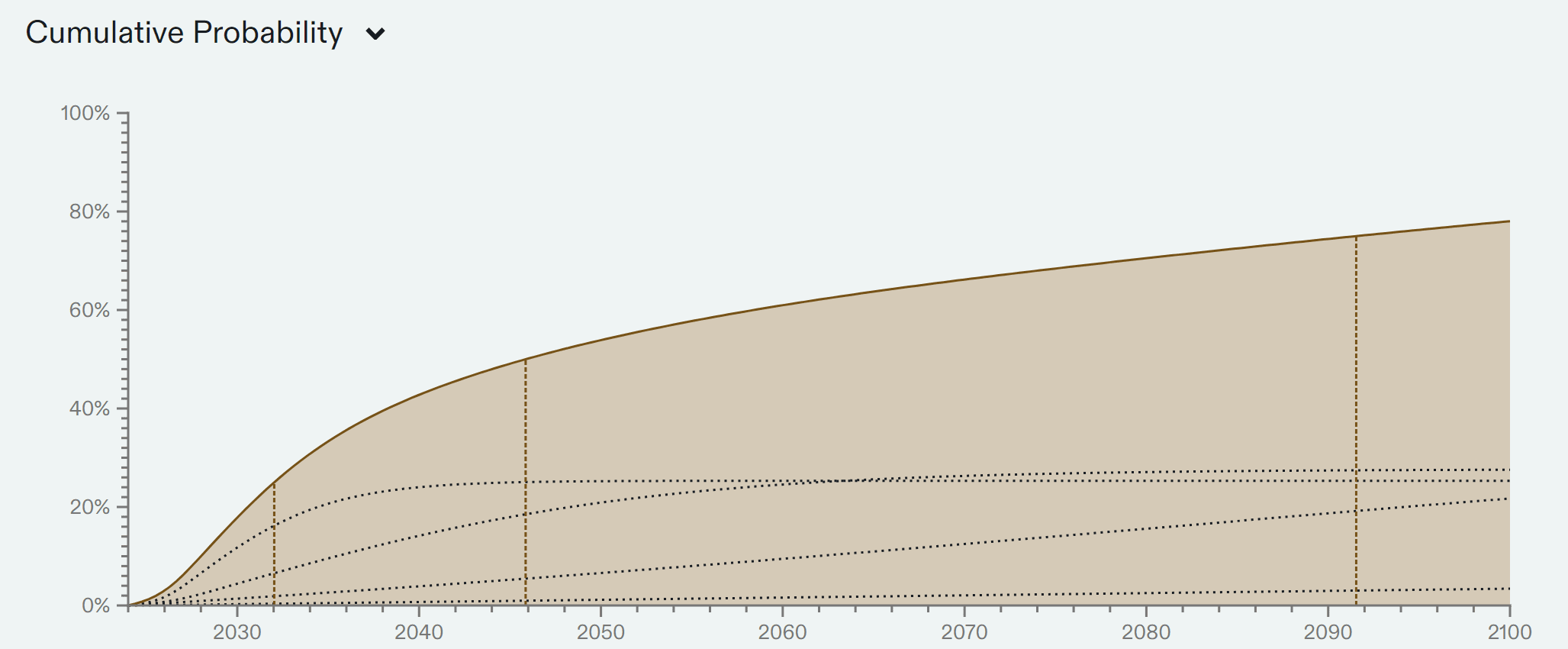
Given this plot, we can look at various years and find my unconditional probability of TAI arriving before that year. See footnote 11. For reference, there is a 47% chance that TAI will arrive before 2043 in this distribution.
Conclusion
Assuming these arguments hold, it seems likely that transformative AI will be developed within the next several decades. While in this essay, I have mostly discussed the potential for AI to accelerate economic growth, other downstream consequences from AI, such as value misalignment and human disempowerment, are worth additional consideration, to put it mildly (Christiano 2014, Ngo et al. 2022).
I thank Tamay Besiroglu, Jaime Sevilla, David Owen, Ben Cottier, Anson Ho, David Atkinson, Eduardo Infante-Roldan and the rest of the Epoch AI team for their support and suggestions through this article. Adam Papineau provided copy-writing.
Notes
-
Following Karnofsky 2016 and Cotra 2020, we will define TAI in terms of potential transformative consequences from advanced AI — primarily accelerated economic growth — but with two more conditions that could help cover alternative plausible scenarios in which AI has extreme and widespread consequences.
Definition of TAI: let’s define the year of TAI as the first year following 2022 during which any of these milestones are achieved:
- Gross world product (GWP) exceeds 130% of its previous yearly peak value
- World primary energy consumption exceeds 130% of its previous yearly peak value
- Fewer than one billion biological humans remain alive on Earth
The intention of the first condition is highlighted throughout this article, as I describe the thesis that the most salient effect of AI will be its ability to automate labor, triggering a productivity explosion. The second milestone is included in order to cover scenarios in which the world is rapidly transformed by AI but this change is not reflected in GDP statistics – for example, if GDP is systematically and drastically mismeasured. The third milestone covers scenarios in which AI severely adversely impacts the world, even though it did not cause a productivity explosion. More specifically, I want to include the hard takeoff scenario considered by Eliezer Yudkowsky and Nick Bostrom, as it’s hard to argue that AI is not “transformative” in this case, even if AI does not cause GWP or energy consumption to expand dramatically. ↩ ↩2
-
For a more in-depth discussion regarding the productivity explosion hypothesis, I recommend reading Davidson 2021, or Trammell and Korinek 2020. ↩
-
This conclusion was somewhat conservative since it assumed that we will run out of data after the number of tokens seen during training exceeds our total stock of textual internet data. However, while current large language models are rarely trained over more than one epoch (i.e., one cycle through the full training dataset), there don’t appear to be any strong reasons why models can’t instead be trained over more than one epoch, which was standard practice for language models before about 2020 (Komatsuzaki 2019).
While some have reported substantial performance degradation while training over multiple epochs (Hernandez et al. 2022), other research teams have not (Taylor et al. 2022). Since we do not at the moment see any strong theoretical reason to believe that training over multiple epochs is harmful, we suspect that performance segregation from training on repeated data is not an intractable issue. However, it may be true that there is only a slight benefit from training over multiple epochs, which would make this somewhat of a moot point anyway (Xue 2023). ↩
-
To help explain the utility of surrogate metrics, here’s a potential example. It might be that while accuracy on multi-step reasoning tasks improves suddenly as a function of scale, performance on single-step reasoning improves more predictably. Since multi-stage reasoning can plausibly be decomposed into a series of independent single-step reasoning steps, we’d expect a priori that performance on multi-step reasoning might appear to “emerge” somewhat suddenly at some scale as a consequence of the mathematics of successive independent trials. If that’s true, researchers could measure progress on single-step reasoning and use that information to forecast when reliable multi-step reasoning will appear. ↩
-
The central idea is that given model scaling data, we can estimate how the reducible loss falls with scale, which we can interpret as the KL-divergence of the training distribution from the model. Loosely speaking, since KL-divergence tells us the discrimination information between two distributions, we can use it to determine how many samples, on average, are required to distinguish the model from the true distribution. ↩
-
This is achieved by setting the training FLOP gap parameter equal to 1 in the takeoff speeds model. ↩
-
We will follow Bostrom 2003 in defining a superintelligence as “any intellect that is vastly outperforms the best human brains in practically every field, including scientific creativity, general wisdom, and social skills.” ↩
-
Here are my personal TAI timelines conditional on no coordinated delays, no substantial regulation, no great power wars or other large exogenous catastrophes, no global economic depression, and that my basic beliefs about reality are more-or-less correct (e.g. I’m not living in a simulation or experiencing a psychotic break).
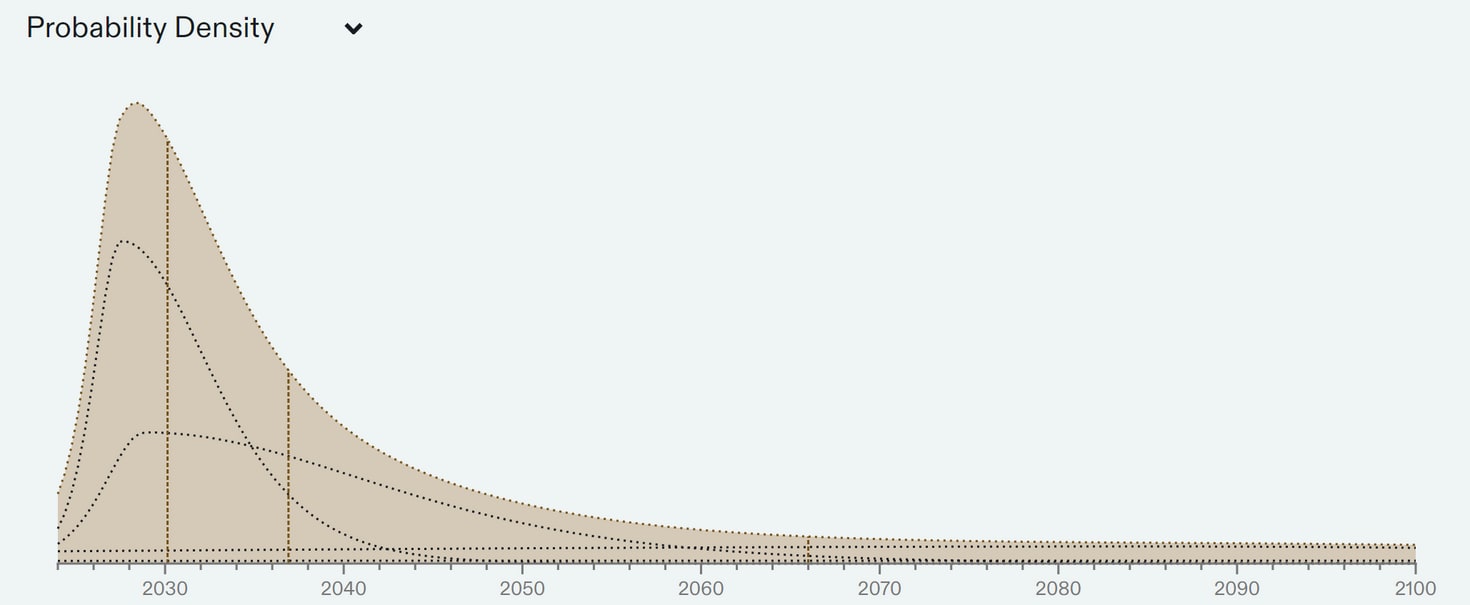
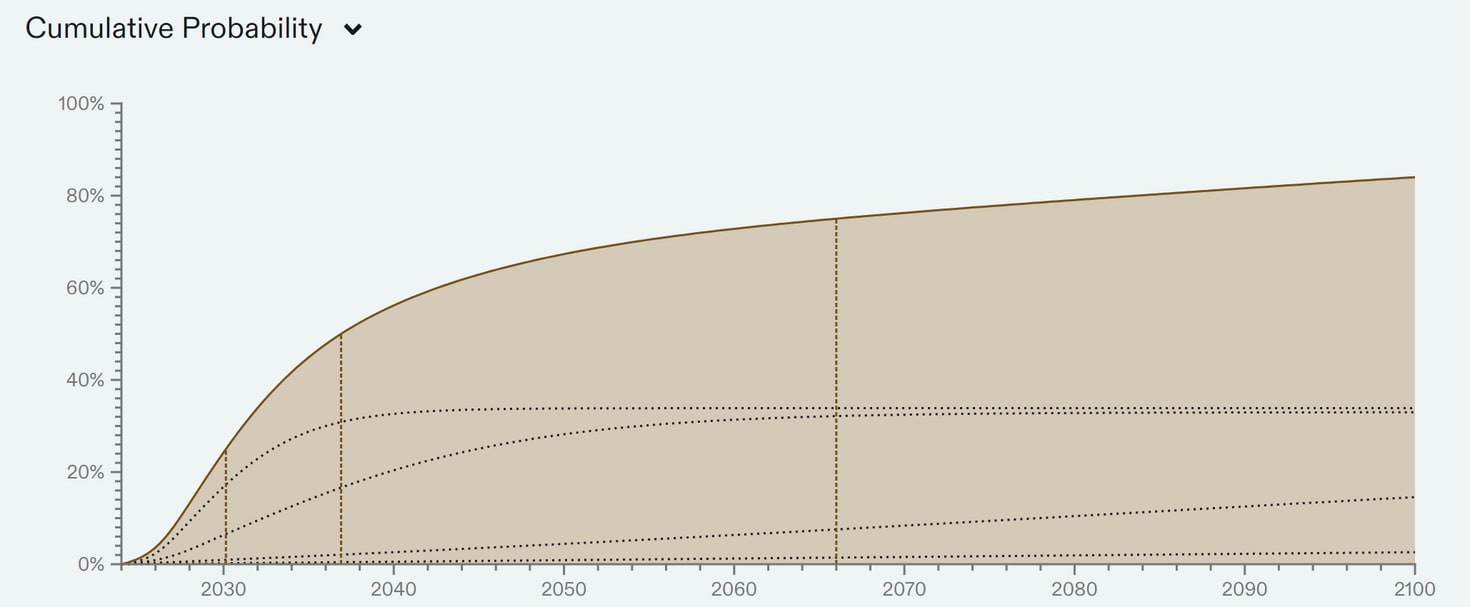
-
I’ll define transformative FLOP requirements as the size of the largest training run in the year prior to the year of TAI (definition given in footnote 1) assuming that no action is taken to delay TAI, such as substantial regulation. ↩
-
Note that this distribution was changed slightly in light of some criticism. I think the previous plot put an unrealistically low credence on TAI arriving before 2030. ↩
-
Year P(TAI < Year) 2030 18% 2035 34% 2040 43% 2043 47% 2045 50% 2050 54% 2060 61% 2070 66% 2080 71% 2090 74% 2100 78%
Updates
I reworded a sentence to better summarize the results of the interactive timelines model from Epoch AI.
About the authors

Related posts