Large-Scale AI Models
Our Large-Scale AI Models database documents over 200 models trained with more than 1023 floating point operations, at the leading edge of scale and capabilities.
Published June 19, 2024, last updated October 22, 2024
Data insights
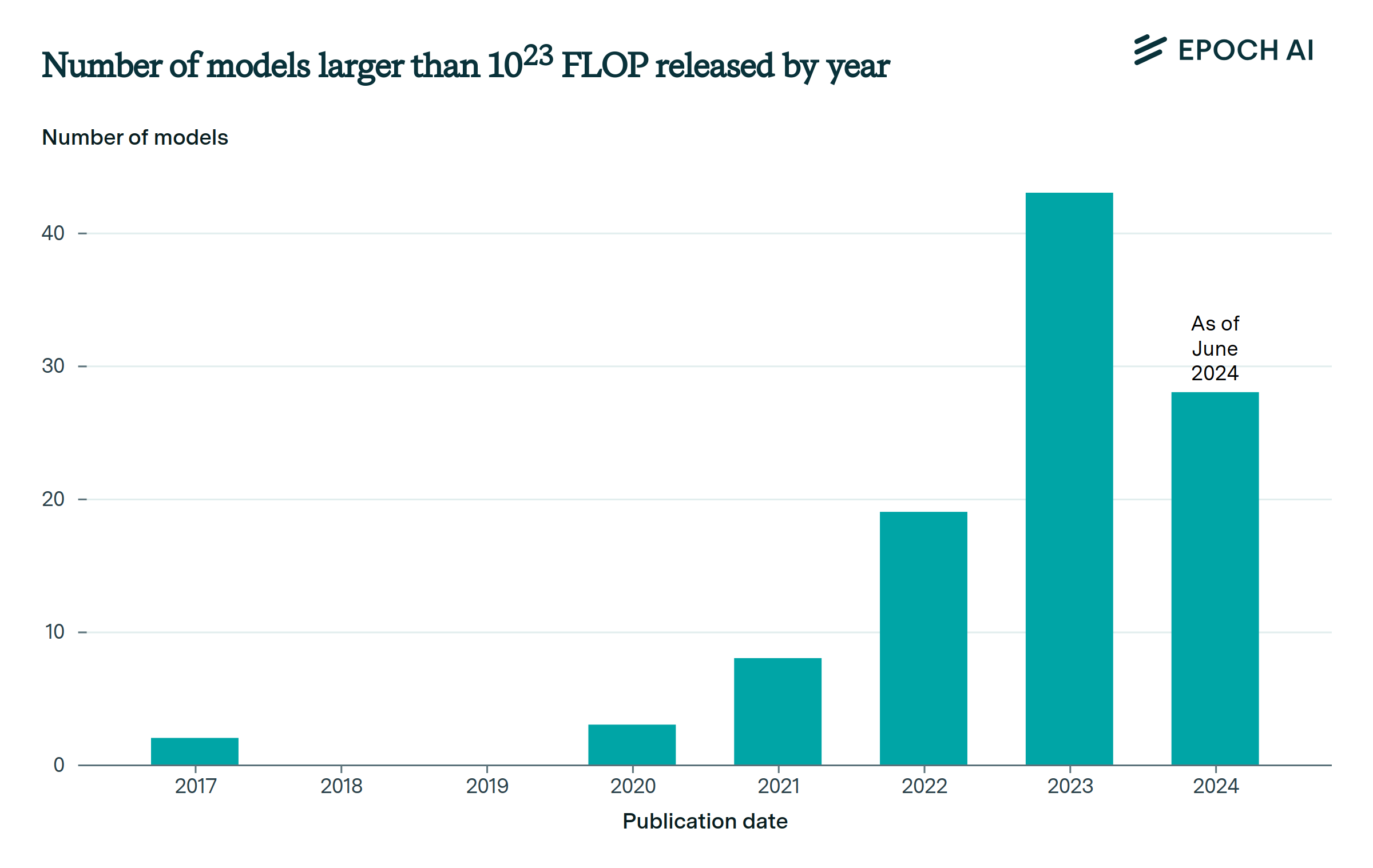
The pace of large-scale model releases is accelerating.
In 2017, only two models exceeded 1023 FLOP in training compute. By 2020, this grew to five models; by 2022, there were 32, and by 2024, there were 127 models known to exceed 1023 FLOP in our database, and 94 more with unconfirmed training compute that likely exceed 1023 FLOP. As AI investment increases and training hardware becomes more cost-effective, models at this scale come within reach of more and more developers.
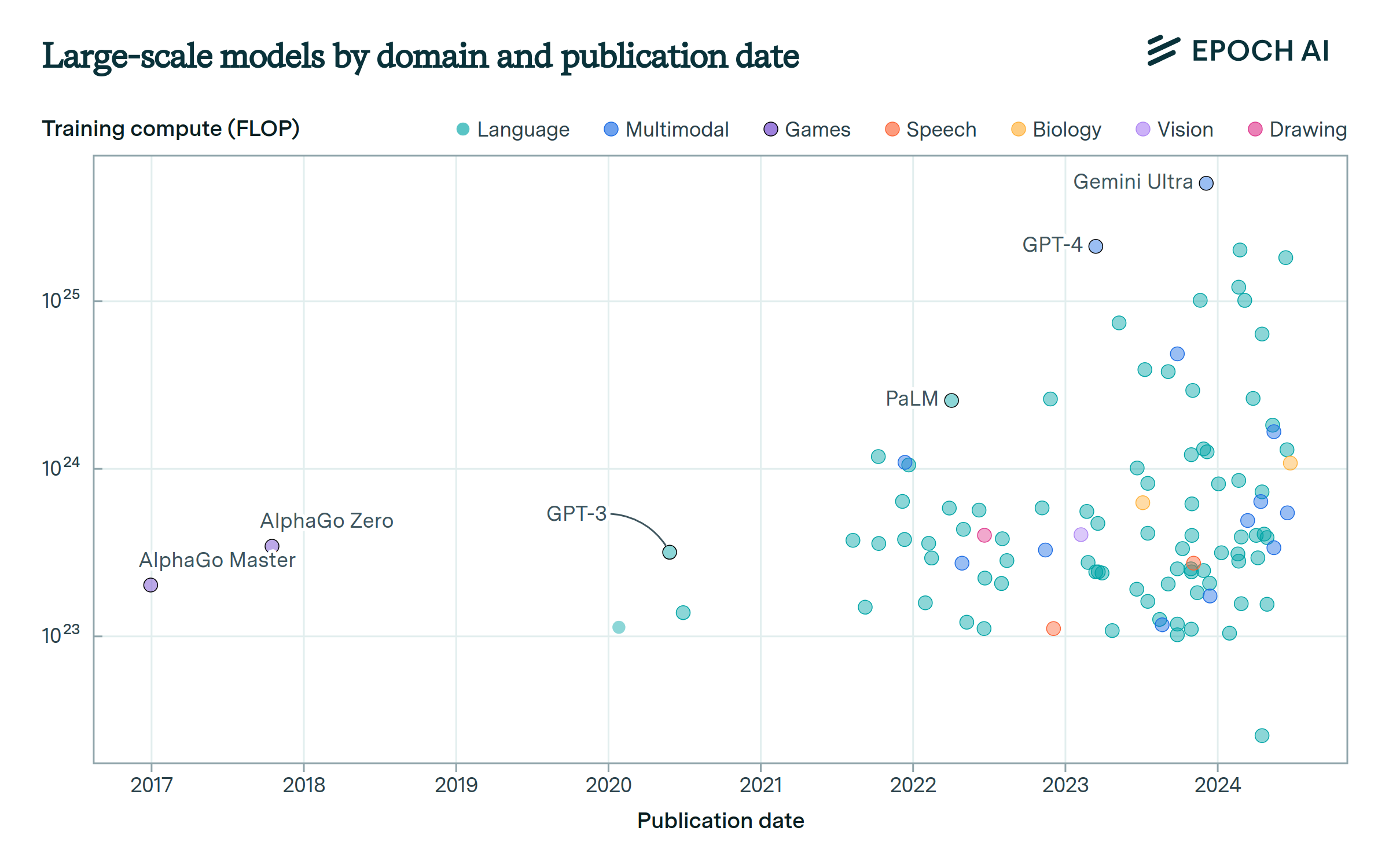
Language models compose the large majority of large-scale AI models.
Out of 221 large-scale models with known compute, 198 are language models, of which 30 are vision-language models such as GPT-4. The first models trained with 1023 FLOP were for game-playing, but language has dominated since 2021. Other large-scale models have been developed for image and video generation, biological sequence modeling, and robotics.
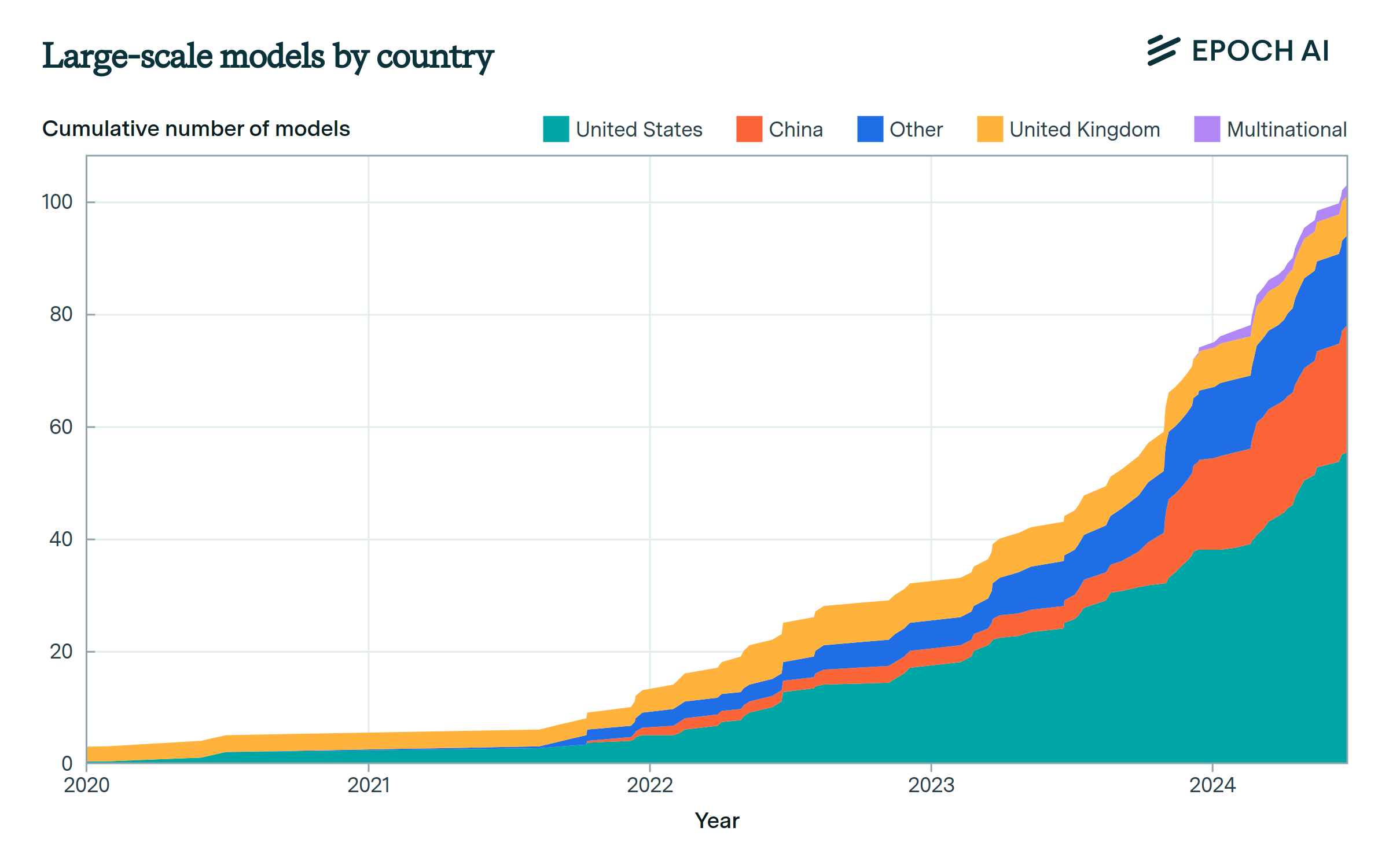
Most large-scale models are developed by US companies.
Over half of known large-scale models were developed in the United States. A quarter were developed in China, and this proportion has been growing in recent years. The European Union trails them with 14 models, while the United Kingdom has developed 6. Graph axes start at 2020, as the majority of large-scale models were developed after this.
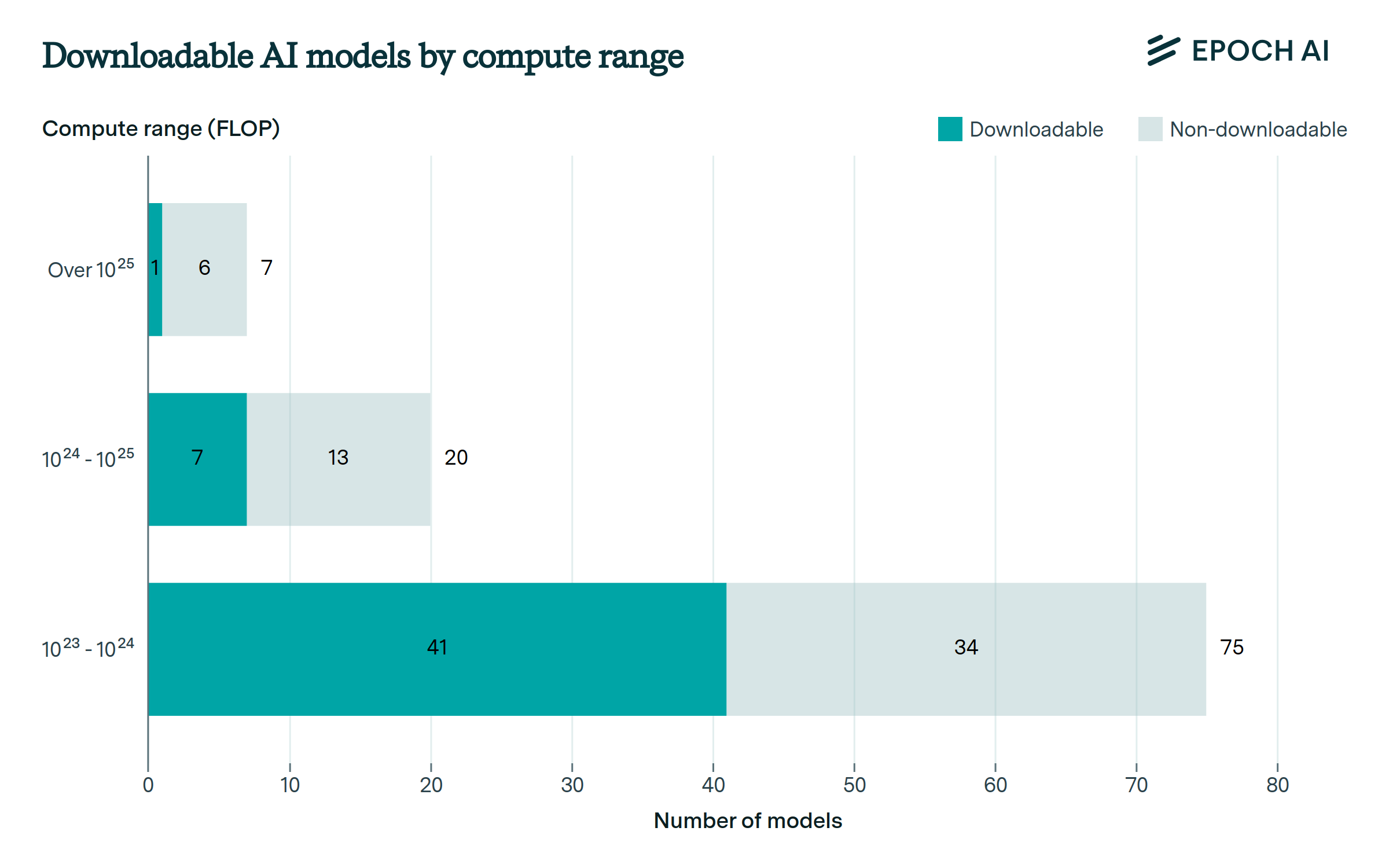
Almost half of large-scale models have published, downloadable weights.
0 large-scale models with known compute have downloadable weights. Most of these have a training compute between 1023 and 1024 FLOP, which is less compute than the largest proprietary models. The developers that have released the largest downloadable models today are Meta and the Technology Innovation Institute.
Related work


FAQ
What is a large-scale model?
This database highlights models with training compute over 1023 floating point operations (FLOP). This is roughly the compute scale of GPT-3 and above.
What is an unconfirmed large-scale model?
Many models do not report enough details to estimate their training compute. Focusing on models with known training compute leaves out many notable models, such as Claude 3 or Sora. To mitigate this, we collected models where the training compute is unknown but available information suggests it likely exceeds 1023 FLOP.
Why are the number of models in the database and the results in the explorer different?
The explorer only shows models where we have estimates to visualize, e.g. for training compute, parameter count, or dataset size. While we do our best to collect as much information as possible about the models in our databases, this process is limited by the amount of publicly available information from companies, labs, researchers, and other organizations. Further details about coverage can be found in the Records section of the Notable Models documentation.
Why is this data important?
Training compute plays a crucial role in the development of modern AI, and both the US Executive Order on AI development and the EU AI Act establish reporting requirements based on compute thresholds. These regulations underscore the need to monitor and report the computational resources of AI models, ensuring transparency in their development.
How do these large-scale models compare to regulatory compute thresholds?
A few models likely surpass the EU AI Act’s reporting requirements for models trained over 1025 FLOP, including GPT-4 and Gemini Ultra. Currently, no models in our dataset are believed to surpass the 1026 FLOP reporting requirements of the US Executive Order on AI and California’s proposed SB-1047 bill. If training compute continues to increase at a rate of 4x/year, we estimate that the top models will likely surpass 1026 FLOP in 2024 or 2025.
How was the large-scale database created?
Our methodology is designed to identify and track the largest AI models worldwide. Our strategies include benchmark monitoring, repository scanning, global media searches, and lab tracking. A complete overview of the methodology used to collect this data can be found here.
What is the difference between the Large-Scale and Notable AI Models databases?
The Large-Scale AI Models database highlights models with training compute over 1023 floating point operations (FLOP). The Notable AI Models database is our largest database, featuring over 800 machine learning models chosen for their significant technological advancements, wide citations, historical importance, extensive use, and/or high training costs. Large-scale models are also included in the Notable AI Models database when they meet the notability criteria.
How is the data licensed?
Epoch AI’s data is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons Attribution license. Complete citations can be found here.
How do you estimate details like training compute?
Where possible, we collect details such as training compute directly from publications. Otherwise, we estimate details from information such as model architecture and training data, or training hardware and duration. The documentation describes these approaches further. Per-entry notes on the estimation process can be found within the database.
How accurate is the data?
Records are labeled based on the uncertainty of their training compute, parameter count, and dataset size. “Confident” records are accurate within a factor of 3x, “Likely” records within a factor of 10x, and “Speculative” records within a factor of 30x, larger or smaller. Further details are available in the documentation. If you spot a mistake, feel free to report it to data@epochai.org.
How up-to-date is the data?
We strive to maintain a comprehensive and up-to-date database, though the field of machine learning is active with frequent new releases, so there will inevitably be some models that have not yet been added. Generally, major models should be added within two weeks of their release, and others are added periodically during literature reviews. If you notice a missing model, you can notify us at data@epochai.org.
How can I access this data?
Download the data in CSV format.
Explore the data using our interactive tools.
View the data directly in a table format.
Who can I contact with questions or comments about the data?
Feedback can be directed to the data team at data@epochai.org.
Methodology
We use a variety of resources to find candidate models that are plausibly trained using more than 1023 FLOP, including:
- Benchmarks: We monitor leading ML benchmarks and investigate the top-performing models, which are often trained with large amounts of data and compute.
- Repositories: Using APIs and searches, we scan repositories like Papers With Code and Hugging Face to identify large-scale models, especially those with over 1 billion parameters.
- Global Internet Search: Our search extends beyond English-language sources, incorporating news from fifteen other languages to capture developments globally.
- Lab Tracking: We stay informed of new breakthroughs by monitoring announcements and publications from prominent AI research labs.
This approach ensures we capture a wide spectrum of AI innovations and maintain up-to-date data on large-scale AI models globally.
The full methodology is described in our report on compute-intensive models.
Use this work
Licensing
Epoch’s data is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons Attribution license.
Citation
Epoch AI, ‘Data on Large-Scale AI Models’. Published online at epochai.org. Retrieved from ‘https://epochai.org/data/large-scale-ai-models’ [online resource]. Accessed .BibTeX Citation
@misc{EpochLargeScaleModels2024,
title = “Data on Large-Scale AI Models”,
author = {{Epoch AI}},
year = 2024,
url = {https://epochai.org/data/large-scale-ai-models},
note = “Accessed: ”
}Download this data
Large-Scale AI Models
CSV, Updated October 22, 2024