Tracking Large-Scale AI Models
We present a dataset of 81 large-scale models, from AlphaGo to Gemini, developed across 18 countries, at the leading edge of scale and capabilities.
Published
Resources
Explore our Large-scale AI models dataset through interactive visualizations and documentation on our dedicated data page.
We present a new dataset tracking AI models with training compute over 1023 floating point operations (FLOP). This corresponds to training costs of hundreds of thousands of dollars or more.1 We have identified 81 such models, and another 86 models that may exceed the 1023 FLOP threshold but don’t have confirmed training details.
Our previous work has examined the crucial role of training compute in the development of modern AI, and how it drives model capabilities. Existing AI regulation explicitly acknowledges the importance of training compute: both the recent US Executive Order on AI development and the EU AI Act establish reporting requirements based on compute thresholds. Motivated by these developments, we plan to track models with training compute above 1023 FLOP by updating this dataset on an ongoing basis. We call models above this threshold “large-scale models”.
The dataset offers insight into several recent trends in AI development. We share our findings in more detail below, including these:
-
The pace of large-scale model releases is accelerating. Only 11 models exceeded 1023 FLOP in 2020. By 2024, this grew to 81 models in our dataset, and the trend shows no sign of slowing. More.
-
The large majority of large-scale models are language models, but many others are multimodal or process images. Despite early breakthroughs in game-playing, language and image generation have dominated since 2021. More.
-
Over half of known large-scale models were developed in the United States. A quarter were developed in China, with this proportion growing in recent years. More.
-
Almost half of the large-scale models in our dataset had published, downloadable weights, mostly with training compute between 1023 and 1024 FLOP. Publicly released model weights are common, but are trained with less compute than the very largest proprietary models. More.
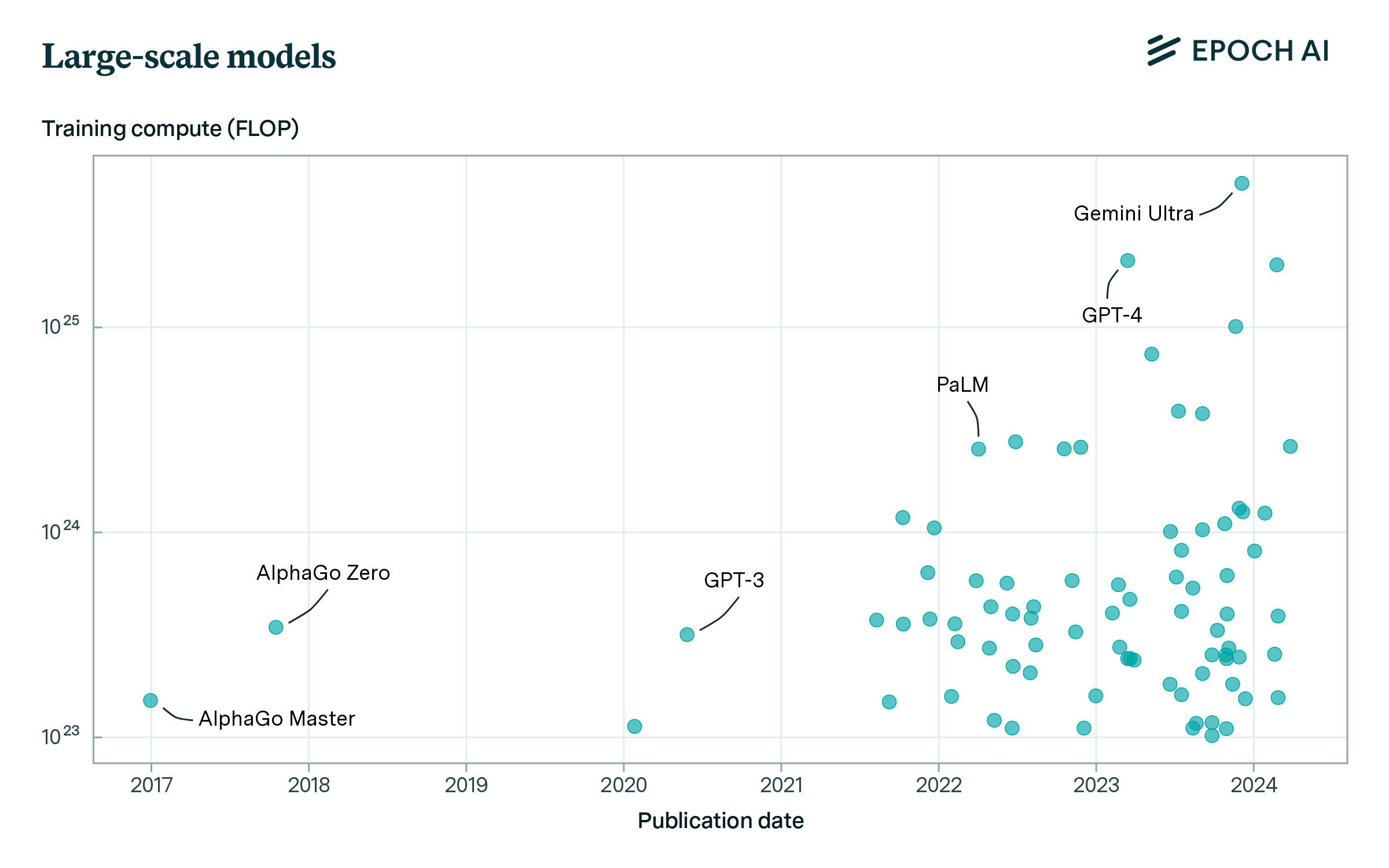
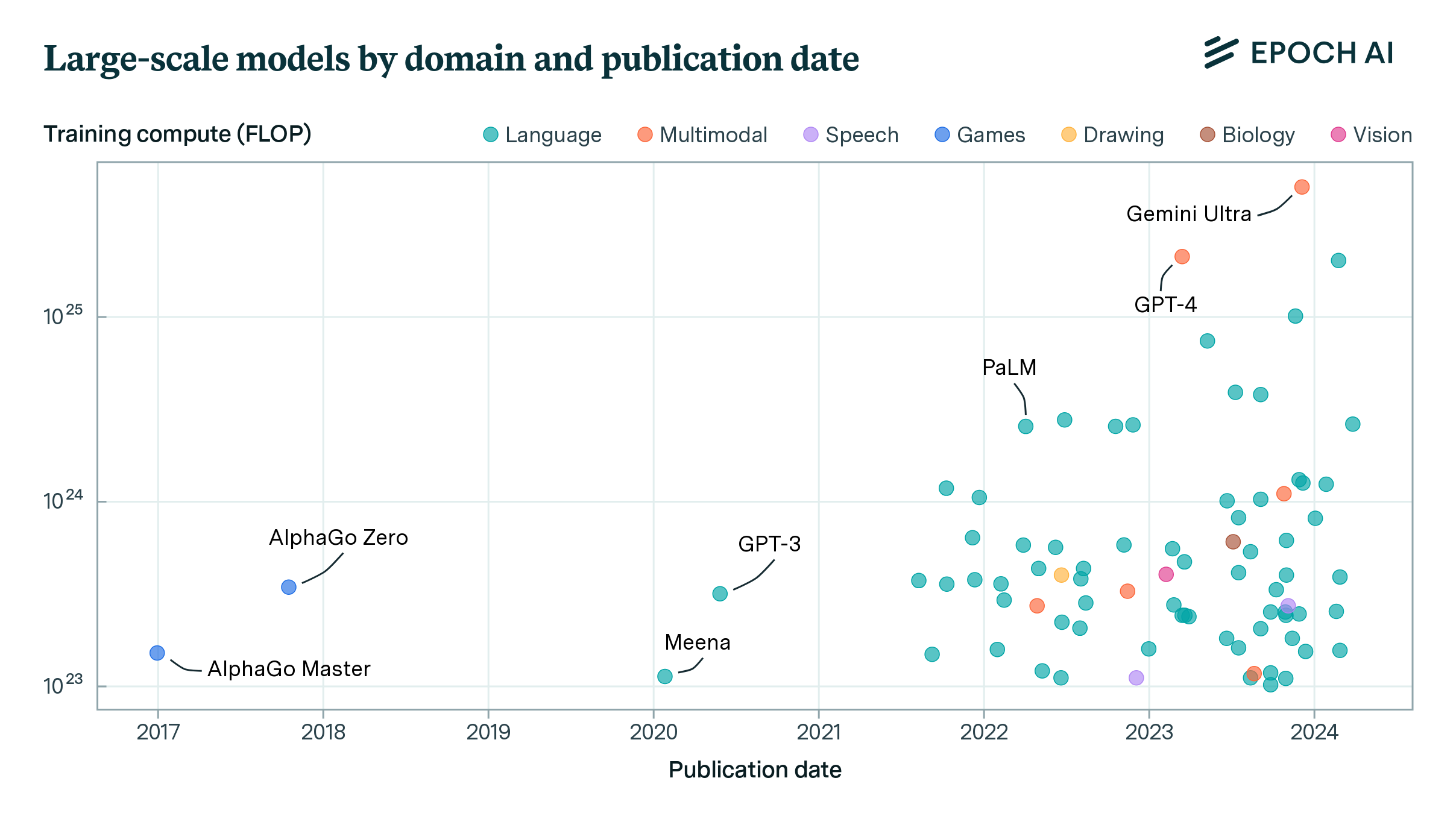
Figure 1: Interactive plot showing the 81 largest models in our dataset, with estimated training compute above 1023 FLOP.
While compiling this dataset, we have conducted an exhaustive search process relying on existing benchmarks and repositories, an automated search for non-English model announcements, and other sources. We explain our methods in depth later in the article. To download the data, see the Appendix or visit our online database.
Results
There are few models at the leading edge, but the frontier advances rapidly

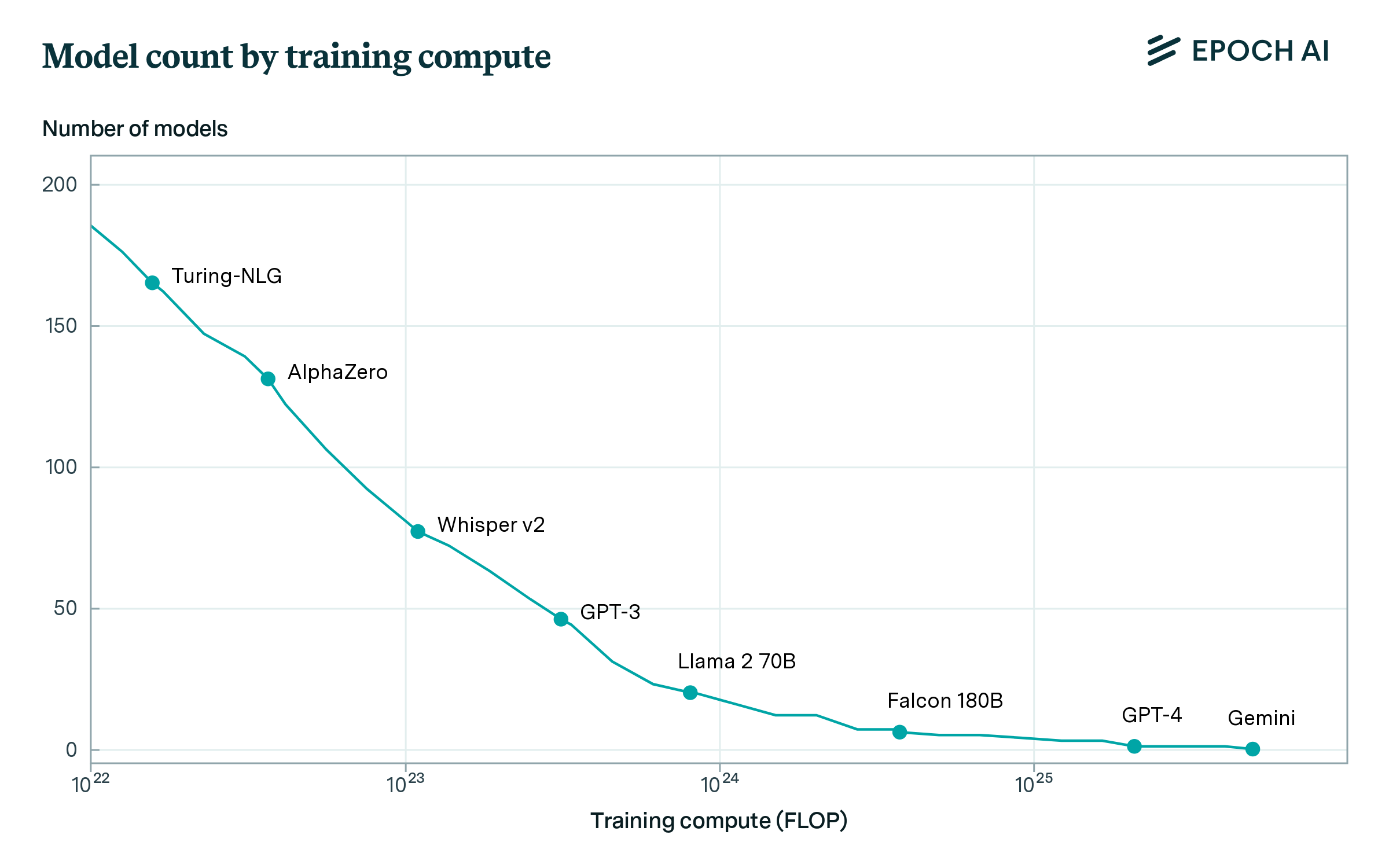
Figure 2: a) Number of models with training compute of at least 1023 FLOP published in each year, 2017 through 2024.
b) Number of models with training compute over different thresholds as of 2024 March 31. Supplemental data on models below 1023 FLOP is taken from our broader database of AI models.
Figure 2b shows how there are few models at the frontier of training compute, currently 1025 FLOP or more. However, as shown in Figure 2a, the frontier advances rapidly over time. In 2020, only two models were trained with more than 1023 FLOP. This increased exponentially over the subsequent three years, and over 40 models trained at this scale were released in 2023.
The rapid advance of the frontier is consistent with exponential increases in ML R&D investment and hardware performance. If training compute continues to increase 4x per year, the top models will surpass 1026 FLOP in 2024, and models at the 1024 scale will be over 1000x smaller than the top models by 2026. Meanwhile, the number of models above smaller thresholds is also quickly expanding, so compute thresholds for monitoring models may need to rise correspondingly over time, if they are to remain focused on models at the cutting edge of capabilities.
Most large-scale AI models are language models
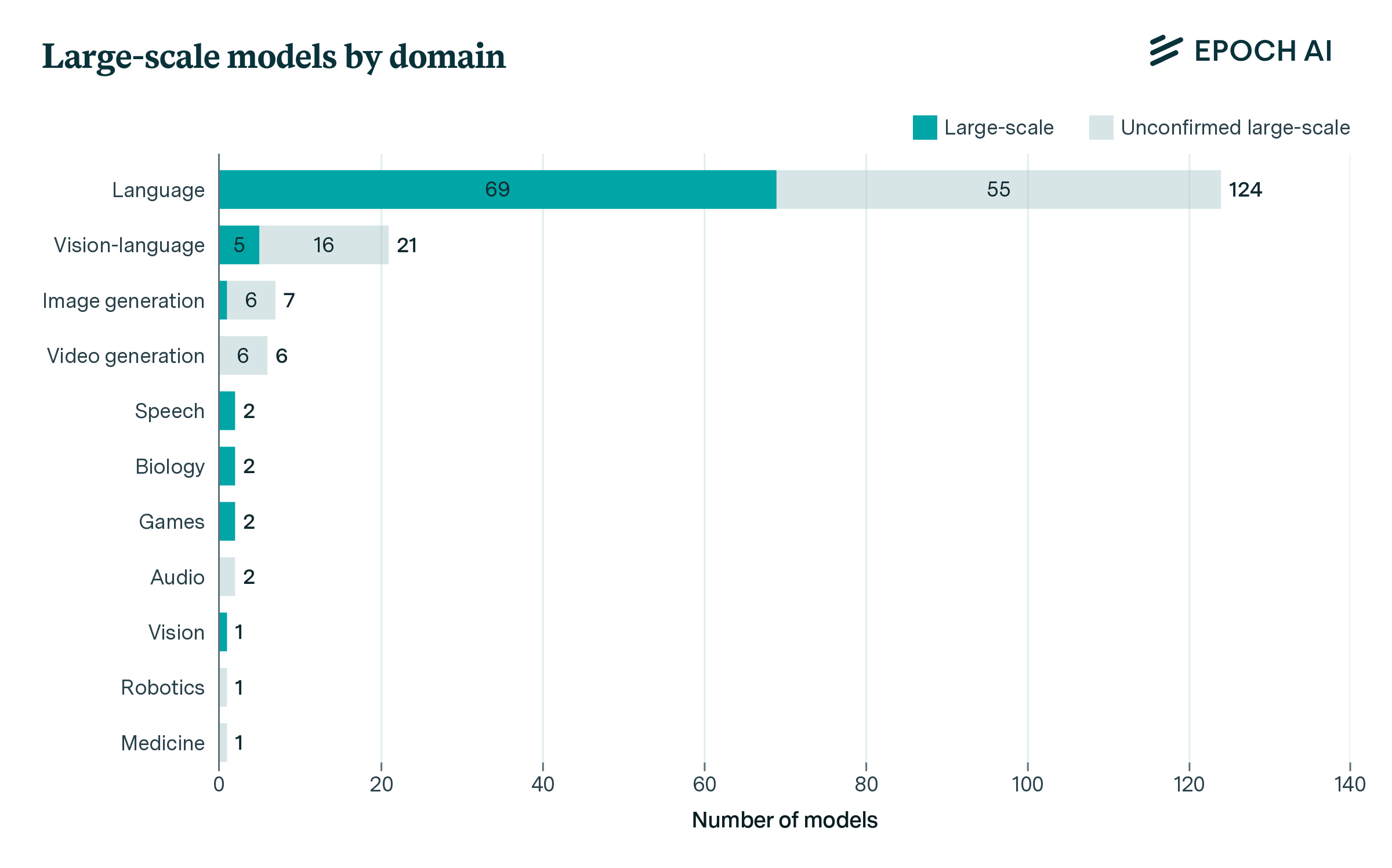
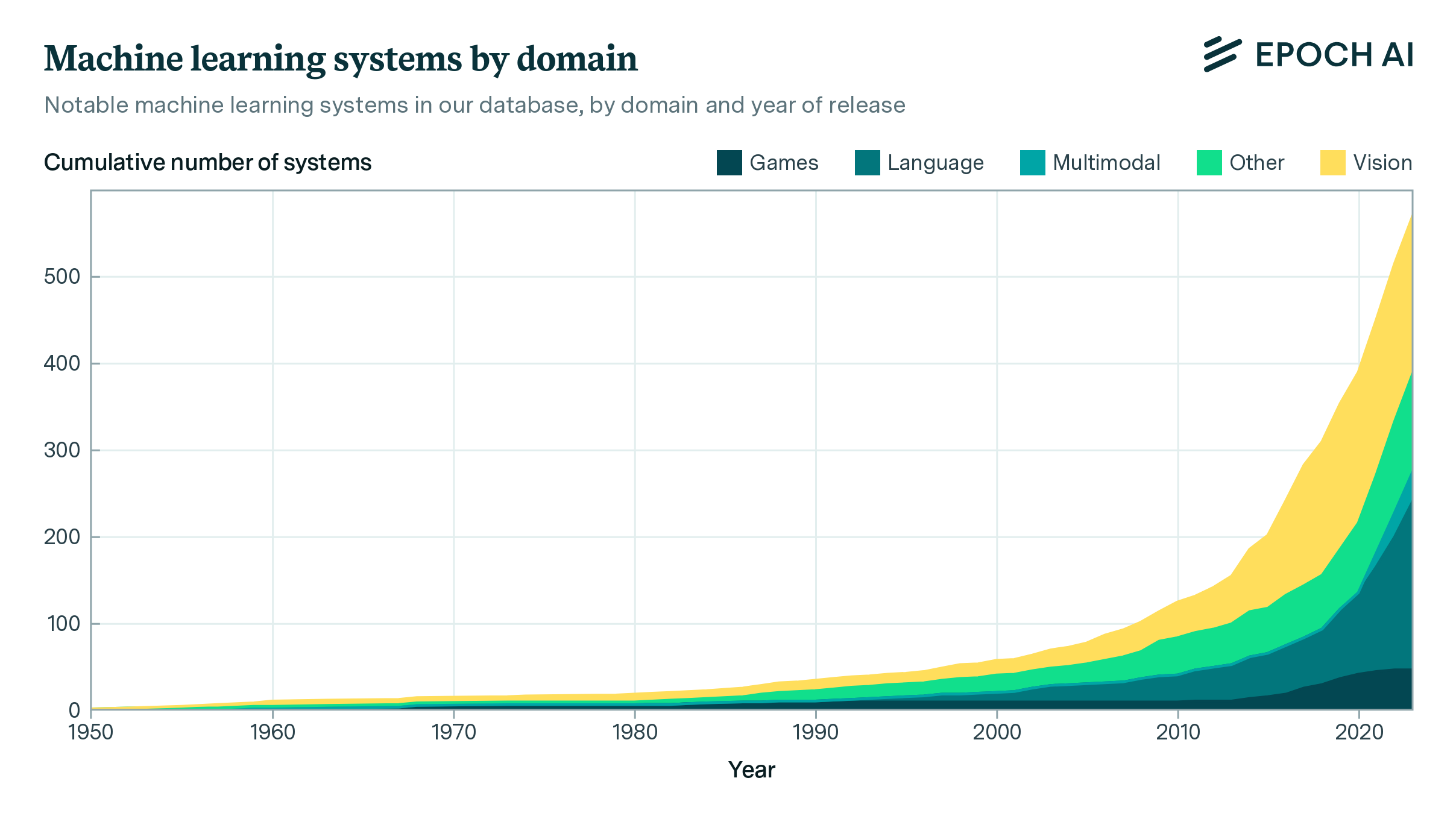
Figure 3: Large-scale AI models categorized by domains of machine learning. Language models trained for both general-purpose language tasks and biology tasks, such as Galactica, are counted within both language and biology.
Figure 3 shows how a large majority (69 out of 81, or 85%) of large-scale models in our dataset are language models, and a few more (5 out of 81, about 6%) are vision-language models. Common applications for these models include general language modeling, chat, and code generation. Among language models, the majority are used for natural-language tasks, like chatting with users and following text-based instructions, and some are trained for tasks such as code generation and protein-sequence prediction. Only a small minority of large-scale models (7 out of 81, about 9%) are not trained on language or text data, instead using audio, image, or game data.
To gain a fuller picture of domains for large-scale models, Figure 3 also shows domains for models with unconfirmed training compute. These models lack public information about their training process, but may be trained with over 1023 FLOP, based on what we know about them (see Unconfirmed large-scale models). The domain breakdown is broadly similar, but a higher proportion of them deal with other applications such as image generation, video generation, and robotics.
Proprietary models, such as Runway’s Gen-2 video generator, typically don’t disclose details of their training datasets and hardware. Robotics systems, such as Nvidia’s CALM, typically require the authors to gather custom, proprietary datasets rather than using open-source datasets which are publicly available and well-documented.
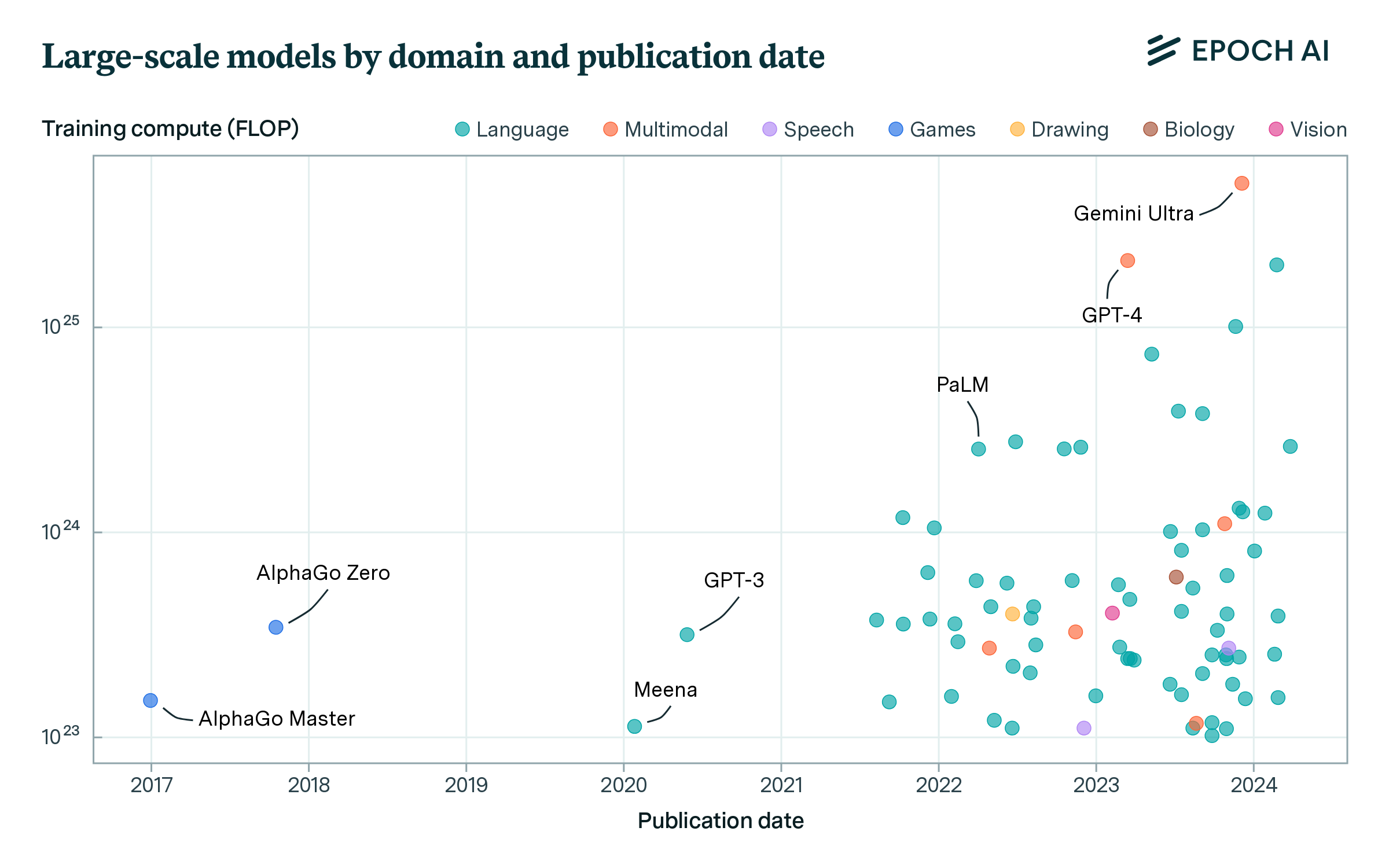
Figure 4: Large-scale AI models by year, separated by domain. Game-playing models such as AlphaGo Master were the first to exceed the 10²³ FLOP threshold, and it took two years for language models to catch up. After 2021, the number of LLMs rapidly increased, while there were no more game-playing models at this scale of compute.
Although language models have been the dominant category of large AI models from 2020 onward, the first two large-scale models under our definition were both game-playing models. The first models trained on over 1023 FLOP, AlphaGo Master and AlphaGo Zero, were developed by DeepMind and published in 2017. These models were trained with an unprecedented amount of compute, over an order of magnitude more than any preceding model. There are no game-playing models in the dataset after these. Figure 4 shows how the next model trained at a similar scale, Google’s GPT-inspired Meena, was not published until 2020. GPT and GPT-2 were below 1023 FLOP, but GPT-3 arrived later the same year, followed by other GPT-inspired language models such as Jurassic-1.
Computer vision is a prominent area of research, but only one non-generative vision model (ViT-22B, current SOTA for ObjectNet) is near today’s frontier of compute. The largest models in our database, GPT-4 and Gemini Ultra,2 are both multimodal models that accept non-text inputs — since multimodal models are more useful than pure language models, this may become a trend among large models. Many of these models have been used in commercial products, such as GPT-4 in ChatGPT, Gemini, and ERNIE in Ernie Bot.
Diffusion models have also been used in many image- and video-generation products, like DALL-E and Midjourney. Several of these may be near the compute frontier, but their developers have typically not published training details.
Most large-scale models are developed by US companies
43 out of 81 large-scale AI models were developed by organizations based in the United States, followed by 19 in China and 6 in the UK. 10 models were developed in other countries outside the US, China, and the UK, and three were developed by collaborations involving researchers and organizations from multiple countries. DeepMind is responsible for every large-scale model developed exclusively in the UK; since merging with the AI teams at Google, it has produced two more as multinational collaborations.
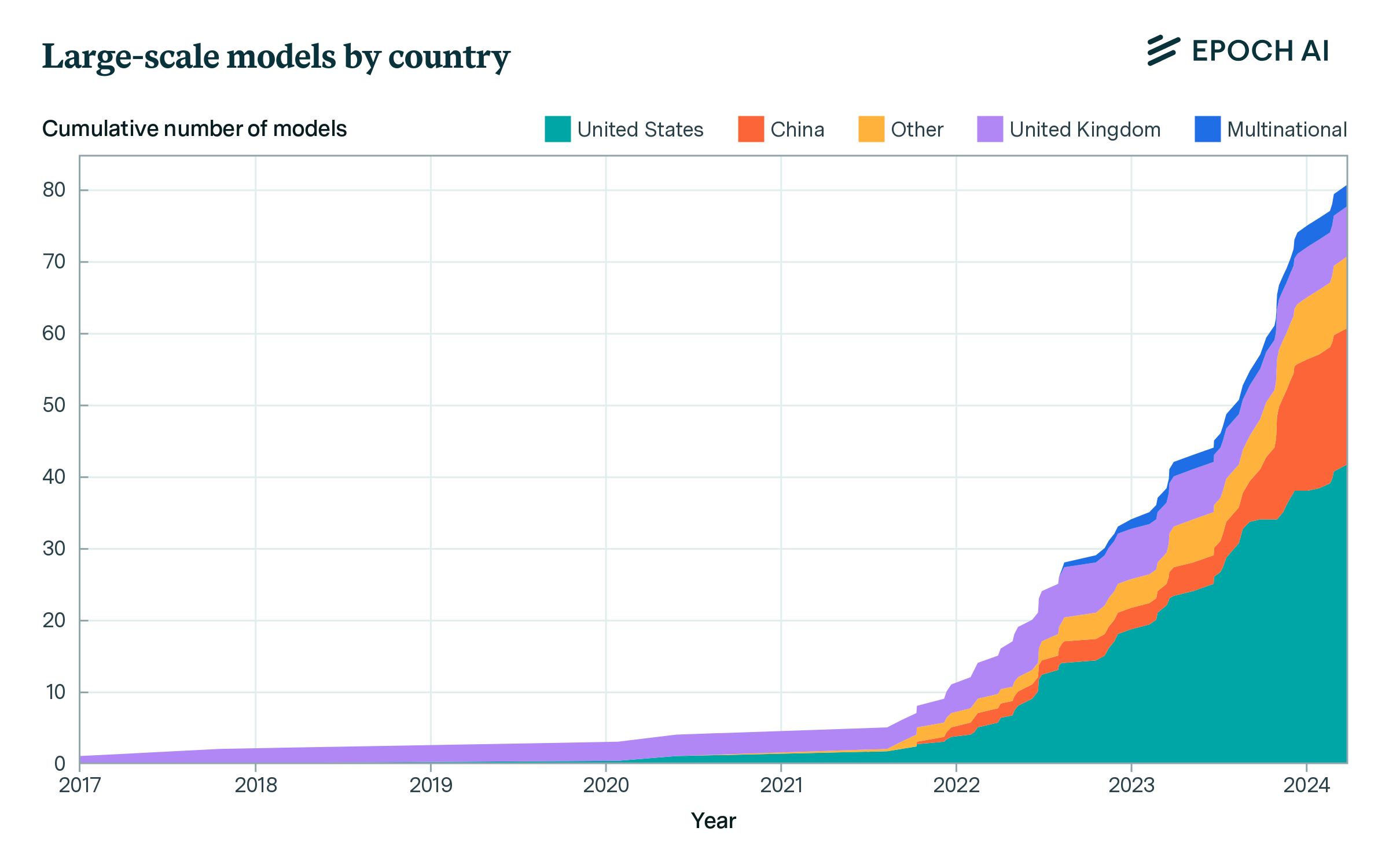
Figure 5: Number of large-scale AI models developed by selected countries, over time. Multinational refers to models developed by collaborators in multiple countries. DeepMind is considered to be within the United Kingdom prior to April 2023; following its merger with Google Brain, models developed by Google DeepMind are considered multinational. Other refers to models developed within any single country not listed in the legend.3
The leading organizations in number of confirmed large-scale models are Google, Meta, DeepMind4, Hugging Face, and OpenAI. Other developers include corporations, universities, and governments.5 Findings are broadly similar when including unconfirmed models, although organizations such as Anthropic and Alibaba move further up the ranking. The vast majority of large-scale models are developed by industry (71) rather than academia (2), with a few industry-academia collaborations (6), and a couple developed by government institutions (2). Slightly over half (53) have been documented in an academic format, although only 17 of these have been published in a peer-reviewed journal or conference, with the remaining 36 published as arXiv preprints or similar.
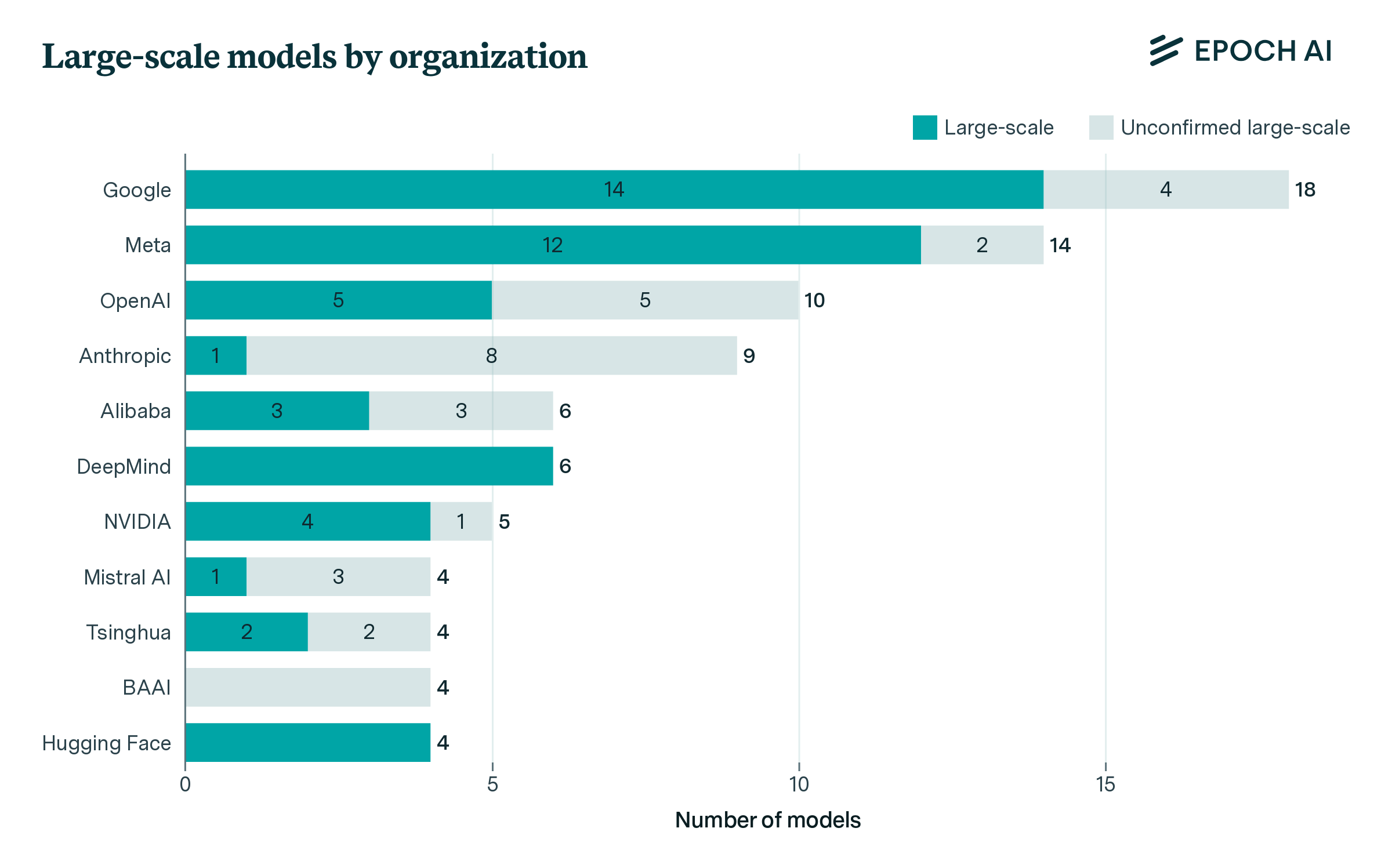
Figure 6: Number of large-scale AI models by organization, for organizations involved in at least 4 such models. Some models are developed by multiple organizations and therefore appear in each of their tallies.
Downloadable models are common, but have lower training compute
38 out of 81 large-scale models are downloadable6, with their model weights available to the public. The downloadable model trained with the most compute to date is Falcon-180B, which was trained using 3.8 * 1024 FLOP, or roughly ⅕ as much compute as GPT-4. Most (86%) of these downloadable models were trained on between 1023 and 1024 FLOP. Meta’s OPT-175B, released in May 2022, was the first downloadable model to reach the 1023 level. To date, Meta has now released a dozen downloadable models at this scale and has committed to continuing this approach in the future, suggesting that open-access ML will continue to grow with the investments of one of the largest tech companies.
Chinese labs are well-represented among large-scale downloadable models — 12 were developed by organizations based in China. Alibaba’s Qwen is one notable example, achieving state-of-the-art performance on several Chinese benchmarks. All large-scale downloadable models from China are large language models trained on datasets containing trillions of tokens of English and Chinese text. Most of them primarily function as chatbots, but several are also trained for code generation. The organizations developing these large models include established companies from the Chinese technology industry like Alibaba, Baidu, Huawei, and research institutions such as Tsinghua University. There are also several new AI startups, including DeepSeek and Baichuan.
Methods for finding large-scale models
We used a variety of resources to find candidate models that were plausibly trained using more than 1023 FLOP. We then estimated how much compute was used to train these models when it is not directly reported by the developers. The models were added to our database, along with estimates of their training compute, number of parameters, and amount of training data whenever this information was available. Models trained with over 1023 FLOP were tallied and the results presented in this article.
Benchmarks and Repositories
Benchmark leaderboards are an important tool for identifying frontier models because researchers evaluate their models against benchmarks as part of standard practice and models trained on the most compute tend to perform the best. We have searched a variety of benchmarks in depth, selected to provide coverage of many different domains of machine learning.
Papers With Code (PWC) maintains a collection of machine learning research papers that have been published along with their repositories, allowing other researchers to replicate their work. It also has a collection of benchmarks, each with a leaderboard tracking the state-of-the-art level of benchmark performance over time. For every benchmark with over 100 model evaluations submitted, we examined the top-performing model. Additionally, we examined every model in the PWC dataset that had at least 1 billion parameters, estimating their training compute based on their associated papers, and added them to our database.
The Center for Research on Foundation Models (CRFM) at Stanford University also works on tracking large models, especially foundation models used in downstream applications after fine-tuning, and has some resources showing a number of large-scale systems. Their Holistic Evaluation of Language Models7 project has a live leaderboard ranking many large models on a variety of metrics and scenarios. CRFM also graphically tracks the ecosystem of foundation models, child models, and datasets, and provides a table of information on these components. We’ve checked their sources for information relevant for estimating compute and collected candidate models from the models table.
Hugging Face is a company that maintains a large online repository of open-source model weights. We used their API to search for models with over 100 downloads and at least 1 billion parameters. Hugging Face also operates Chatbot Arena, a crowdsourced comparison platform where users chat with two LMs at once and choose the one whose responses they like better, which adjusts the models’ Elo ratings accordingly. Chatbot Arena’s leaderboard then ranks all the competing models by Elo rating. We’ve collected all of the models from the leaderboard with training runs likely to have used at least 1023 FLOP.
Non-English news and websites
As the fields of AI and ML grow, development of large models is spreading around the world, and systems developed in regions where languages other than English are predominant may not receive enough coverage in English-language media to come to our attention unless we seek them out. Considering the most commonly spoken languages around the world and in areas with active technology industries, we selected the following languages and did searches using the most popular search engines for each language: Chinese, Hindi, Spanish, French, Arabic, Bengali, Portuguese, Russian, Urdu, German, Japanese, Turkish, Korean, Persian, and Hebrew.8 We looked at the top 100 results for each of the 3-6 most relevant AI keywords in each language, filtered to 2020-present, encompassing the time period when models began to regularly exceed 1023 FLOP.
One of the most fruitful search avenues has been Chinese-language media, which has extensively covered recent AI developments. We found a large number of previously unfamiliar large-scale models through Baidu searches for terms such as “chatbot”, “trillion parameter”, and “large AI model”. For each keyword, we translated the term into Chinese using Google Translate, searched for the translated term on Baidu, and recorded any AI models mentioned in the first 100 search results. These were then researched to determine whether they were trained using at least 1023 floating-point operations.
We also looked at two leaderboards, SuperCLUE (Chinese Language Understanding Evaluation) and OpenCompass, that rank many LLMs by their performance on Chinese-language benchmarks. Most of these LLMs were developed in China. These leaderboards were checked for models previously missing from Epoch AI’s database.
Other sources
Several other sources were used to identify models for the database, though these were not checked exhaustively. We reviewed blog posts and press releases from the major frontier labs (Anthropic, Google, DeepMind, Microsoft, OpenAI) from the past few years to identify research and products involving large models. Epoch AI staff also follow machine learning research and announcements on various platforms and newsletters. We collect new model releases and then add them to the database.
We periodically conduct literature searches of machine learning topics in order to find highly influential research. large-scale systems are frequently (but not always) highly cited, which is to be expected because well-funded research has more potential to achieve breakthroughs and attention within the field. However, during this focused effort to find large-scale models, no models were identified in scholarly searches or bibliographies that were not already identified by the other methods above.
Unconfirmed large-scale models
A challenge in this work is that many models do not report enough details to estimate training compute. Our dataset focuses on models with known training compute, but this precludes many notable models such as Claude 3 or Sora. To mitigate this, we collected a separate table of unconfirmed large-scale models, where compute is unknown but available information suggests their training compute could exceed 1023 FLOP. This data is also downloadable in the Appendix.
We selected models in our database published in 2022 or later, with unknown training compute. We excluded models with fewer than 3 billion parameters or 10 billion training data points. These thresholds were based on parameter counts and dataset sizes in models with confirmed compute. We also excluded models fine-tuned from other models. We then manually inspected candidates to rule out models likely to fall below 1023 FLOP, for example based on training hardware or model capabilities. Although some of these models may nevertheless have been trained with less than 1023 FLOP, this data provides more context about large-scale models, for example in Figures 3 and 6.
Outcomes and limitations
There are limits to our search methods, and some models within the scope of our search may not be possible to find by these or other methods. Commercial products are often proprietary and their technical details not divulged, especially in the cybersecurity and B2B service industries. The cybersecurity suite Darktrace and anti-malware software McAfee are typical examples of this, as is the custom chatbot service Dante.
Sometimes, there are publicly announced AI products which may or may not have important models behind them. Microsoft Azure offers chatbots which may have been developed within Microsoft or may be using GPT-4. Salesforce’s competing service EinsteinGPT is similar and may be using an OpenAI model on the backend or may involve a custom, fine-tuned model. ByteDance’s Tako chatbot (used in TikTok) is almost certainly not based on GPT-4, but it is unclear how much compute or data was used when creating it. The image generation service Craiyon may involve a large model, possibly based on Stable Diffusion. The chat and writing services YouChat and rytr, on the other hand, definitively do not contain bespoke models, instead relying on the GPT API.
In other cases, labs may develop large models but forgo announcing them in order to maintain secrecy. We don’t know how many such models have flown under the radar. Determining the number or identity of organizations capable of creating these models would be a useful endeavor, but was beyond the scope of this process.
Conclusion
Large-scale AI models are of particular interest for policymakers and researchers. We have collected a dataset covering 81 large-scale models, trained with large amounts of compute. Analyzing this dataset confirms several key insights. First, language modeling is by far the most common domain. This trend seems likely to continue, with language prioritized in development of the next generation of frontier models, even as they become multimodal. Second, large-scale models are primarily developed by US companies, but a quarter come from Chinese labs, and this proportion has grown in recent years. Finally, almost half of highly large-scale models are downloadable, a trend suggesting that new cutting-edge capabilities become widely available soon after they are developed in proprietary models.
Ultimately, we can never find every machine learning model in existence, so our search continues. A key challenge in this work has been the large number of models without known training compute.9 We urge machine learning developers to report your compute so that the policy and research communities can maintain a well-informed view of the frontier of the field.
To keep our database up-to-date, 15 foreign languages have been incorporated into an automated pipeline that searches 5 languages per month for AI news articles published since the previous search, to find any model within three months of its release in any language. As machine learning companies, talent, and infrastructure spread around the world, these search results will reveal more and more large models.
We’ll continue tracking new leading models on previously searched benchmarks, models leading on benchmarks newly exceeding 100 evaluated systems, and models with over 1 billion parameters submitted to Papers With Code and Hugging Face. Suggestions for large ML systems not featured in our database can be submitted using this form. If this data has been useful to you, we’d love to hear from you at data@epochai.org.
Appendix
Dataset
Large-scale models: These models were trained with over 1023 FLOP, based on our estimates of training compute.
Unconfirmed and known large-scale models: This dataset includes both models that were trained with over 1023 FLOP as well as models which have unknown training compute but may have been trained on over 1023 FLOP. Further details are described in Unconfirmed large-scale models.
The data can be downloaded using the dropdown menu at the top of the embedded table. We also offer a downloadable large-scale model dataset, updated daily, on our database portal and at this CSV link.
Growth of the compute frontier
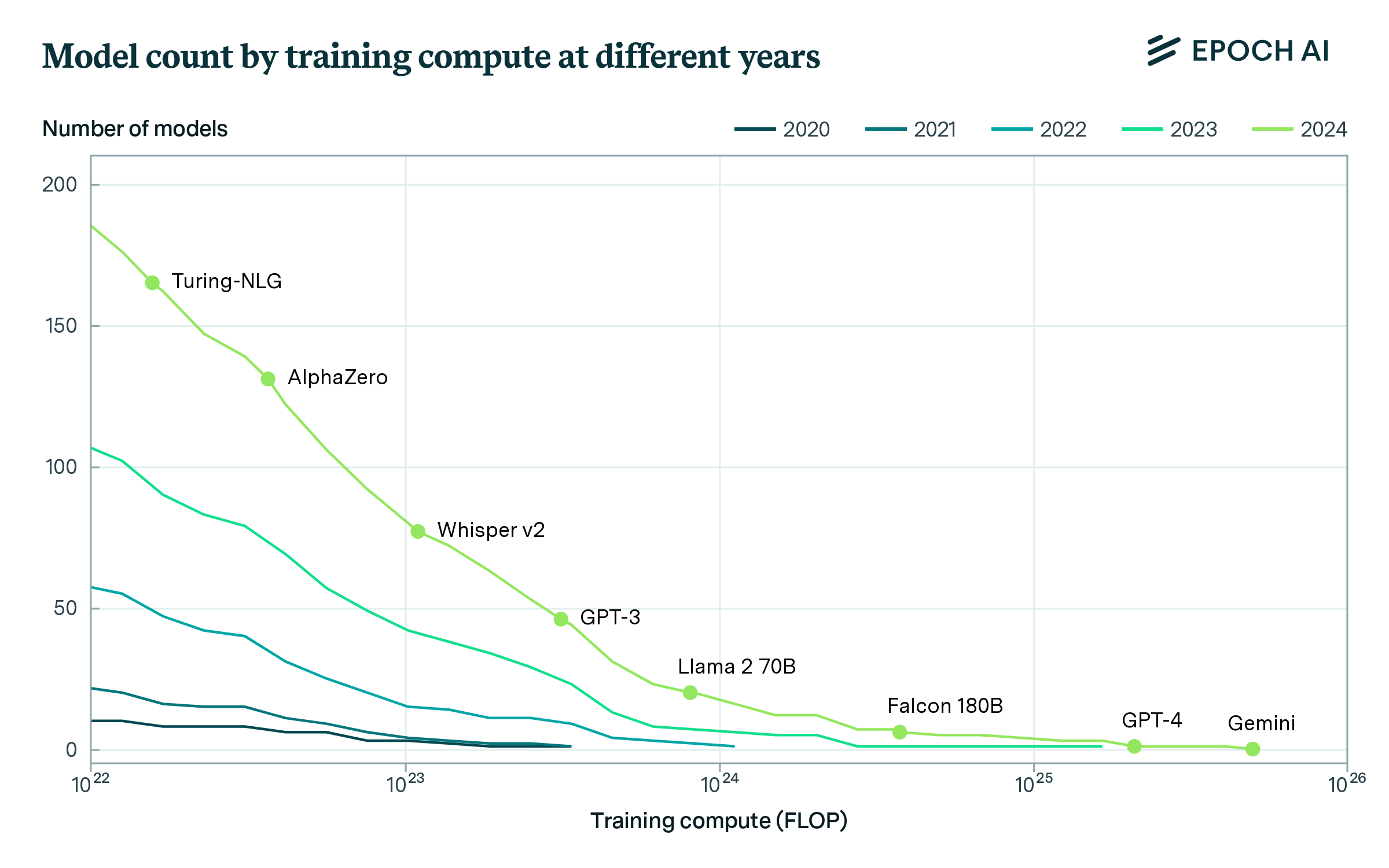
Figure 7: number of models (y-axis) above different compute thresholds (x-axis) in different years (legend). In any year, the figure illustrates how many models had been published after being trained on a given amount of compute. The annual counts are spaced one year apart, with numbers as of March 31 in each year.
The compute frontier of large models advanced rapidly after 2021. Most existing large-scale models were published in the last two years: 21 during 2022, and 42 in 2023. A similar pattern holds across all compute thresholds between 1022 and 1024 FLOP. At any given time, there were a small number of models at the leading edge of training compute. However, once the first model was trained at a given compute scale, subsequent models followed at an increasing rate. The frontier has grown rapidly: in 2020 a handful of models were above 1022 FLOP, but by 2024 there were hundreds, as illustrated in Figure 7.
Credits
This article was written by Robi Rahman, David Owen, and Josh You.
The frontier model search was conducted by Robi Rahman, Josh You, David Owen, and Ben Cottier. The training compute of models identified during the search was estimated by Josh You, Bartosz Podkanowicz, and Robi Rahman.
We thank Anson Ho, Jaime Sevilla, Robert Sandler, Tamay Besiroglu, Ben Cottier, and Markus Anderljung for review and feedback on the drafts, and Edu Roldan and Robert Sandler for formatting the article for online publication.
Notes
-
Based on December 2023 cloud compute cost rates to train a model with 1023 FLOPs at 30-50% model FLOPs utilization. For detailed training cost estimates, see our forthcoming study in the 2024 Stanford AI Index Report. ↩
-
Gemini 1.5 Pro and Claude 3 are two recently announced models that are also multimodal. They are likely among the largest models trained to date, though we do not have compute estimates for them yet. ↩
-
Countries included in the category Other include: the United Arab Emirates (2 models), France (2), Israel (1), South Korea (1), Russia (1), Germany (1), Japan (1), and Finland (1). ↩
-
Google’s AI division merged with DeepMind in 2023, forming an AI lab called Google DeepMind. Models created by Google DeepMind are counted as “Google” in this graph, while DeepMind models from before this merger are counted separately. ↩
-
TII, or Technology Innovation Institute, is a government research institute in the United Arab Emirates. ↩
-
Includes fully open-source models (weights, code, data), and models with weights released under permissive or open-source licenses. ↩
-
The most popular search engine is Google in every language except the following: Baidu is the top search engine for Chinese, Yandex for Russian, and Naver for Korean. ↩
-
Some models that were in fact trained on >1023 FLOP may be missing from our list of large-scale models because we don’t have enough information on how much compute was used to train them, not because we don’t know about them. See the appendix for a list of models we suspect may have been trained on over 1023 FLOP, but for which we do not have compute counts or compute estimates. ↩
About the authors



Related posts