Machine Learning Model Sizes and the Parameter Gap
The model size of notable machine learning systems has grown ten times faster than before since 2018. After 2020 growth has not been entirely continuous: there was a jump of one order of magnitude which persists until today. This is relevant for forecasting model size and thus AI capabilities.

Published
Resources
Summary: The model size of notable machine learning systems has grown ten times faster than before since 2018. After 2020 growth has not been entirely continuous: there was a jump of one order of magnitude which persists until today. This is relevant for forecasting model size and thus AI capabilities.
Trends in model size
In current ML systems, model size (number of parameters) is related to performance via known scaling laws. We used our dataset to analyze trends in the model size of 237 milestone machine learning systems. The systems are categorized into Language, Vision, Games and Other according to the task they solve.
Model size slowly increased by 7 orders of magnitude from the 1950s to around 2018. Since 2018, growth has accelerated for language models, with model size increasing by another 4 orders of magnitude in the four years from 2018 to 2022 (see Figure 1). Other domains like vision have grown at a more moderate pace, but still faster than before 2018.
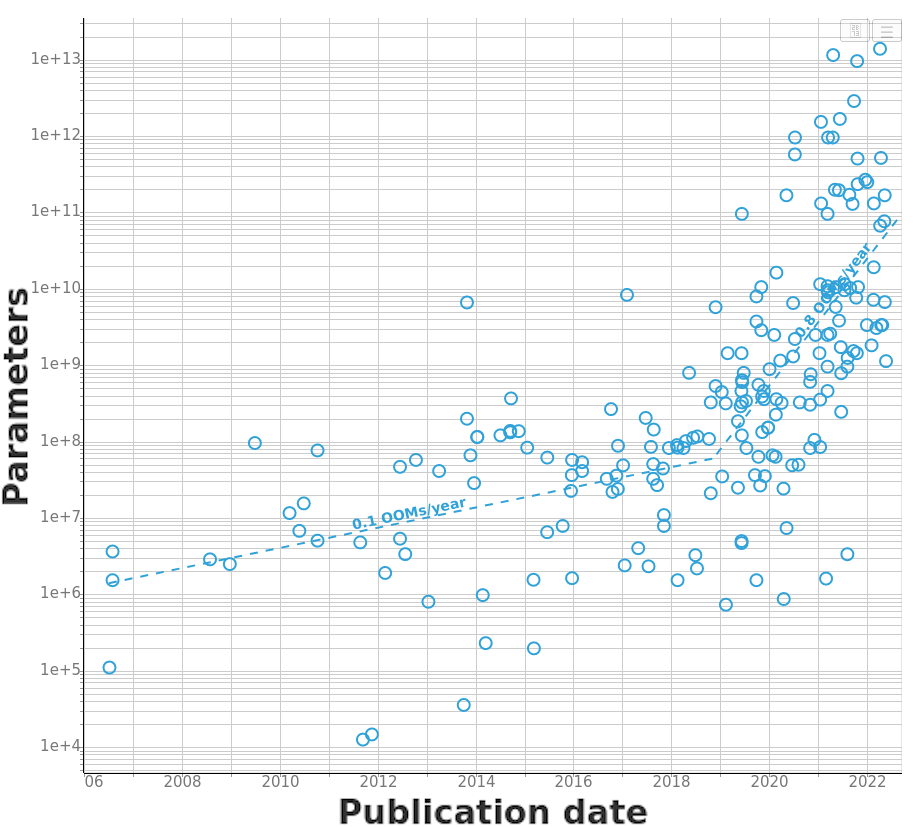
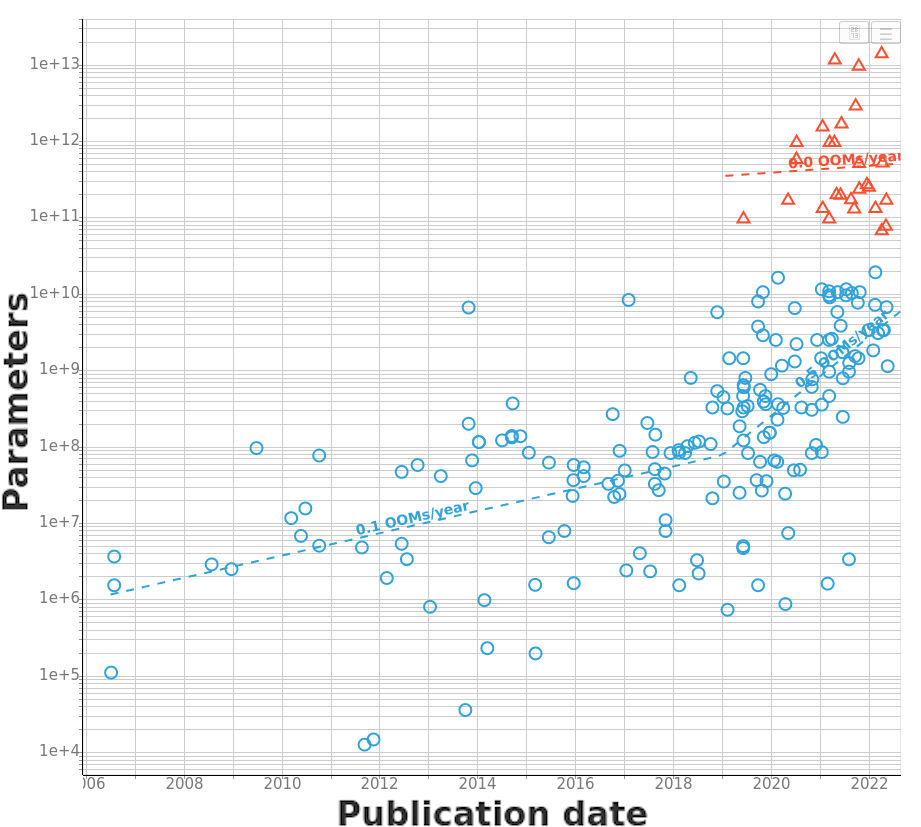
Figure 1. Left: Transition period around 2018, assuming a single post-2018 trend. Right: the same period, assuming two separate post-2018 trends.
| Period | Data | Scale (start to end) | Slope | Doubling time | $$R^2$$ |
| 1952 to 2018 | $$n=109$$ | 1e+01 to 3e+7 params | 0.1 OOMs/year [0.1; 0.1; 0.1] |
39.7 months [36.4; 39.7; 40.7] |
0.62 |
| 2018 to 2022 (single trend) |
$$n=129$$ | 3e+7 to 2e+12 params | 0.9 OOMs/year [0.9; 0.9; 1.0] |
4.0 months [3.5; 4.0; 4.3] |
0.31 |
| 2018 to 2022 (above gap) |
$$n=27$$ | 7e+10 to 2e+12 params | -0.1 OOMs/year [-0.4; -0.1; 0.2] |
-14.2 months [-52.5; -14.2; 52.0] |
0.00 |
| 2018 to 2022 (below gap) |
$$n=102$$ | 3e+7 to 2e+10 params | 0.5 OOMs/year [0.4; 0.5; 0.5] |
8.0 months [7.0; 8.0; 9.8] |
0.25 |
Table 1. Summary of our main results. Around 2018 there was a general increase in growth. This can be split into the previous trend increasing its growth rate, and a separate cluster of very large models appearing on top.
The parameter gap
Starting in 2020, we see many models below 20B parameters and above 70B parameters, but very few in the 20B-70B range. We refer to this scarcity as the parameter gap (see Figure 2).
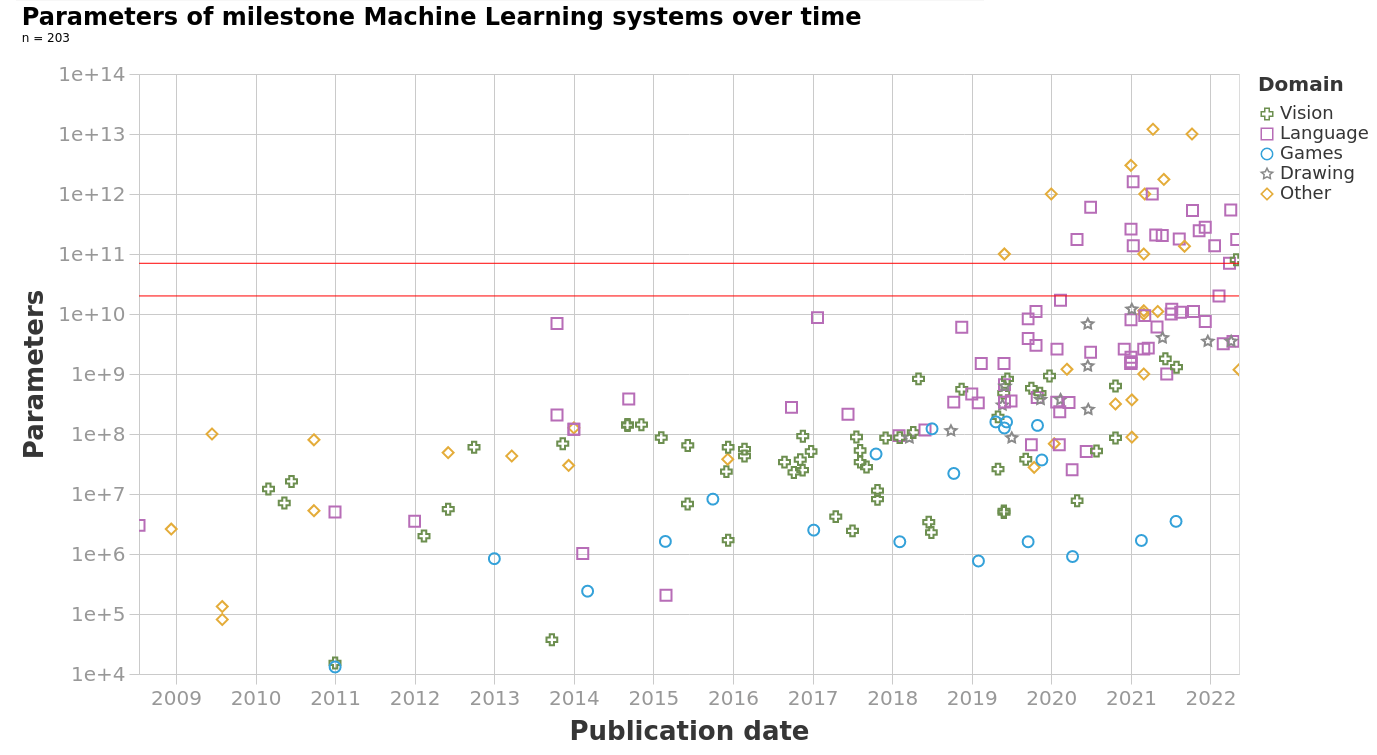
Figure 2: Model size over time, separated by domain. Red lines highlight the parameter gap. Most systems above the gap are language or multimodal models.
We have come up with some hypotheses that explain the parameter gap, of which these two are the ones most consistent with the evidence:
- Increasing model size beyond 20B parameters has a high marginal cost due to the need to adopt different parallelism techniques, so that mid-sized models are less cost-effective than bigger or smaller ones.
- GPT-3 initiated the gap by ‘jumping’ one order of magnitude in size over previous systems. This gap was maintained because researchers are incentivized to build the cheapest model that can outperform previous models. Those competing with GPT-3 are above the gap; the rest are below.
The existence of the parameter gap suggests that model size has some underlying constraints that might cause discontinuities in the future.
About the authors






Related posts