AI Capabilities Can Be Significantly Improved Without Expensive Retraining
While scaling compute for training is key to improving LLM performance, some post-training enhancements can offer gains equivalent to training with 5 to 20x more compute at less than 1% the cost.
Published
Resources
The massive computation used to train LLMs and similar foundation models has been one of the main drivers of AI progress in recent years, which has led to the recognition of the “Bitter Lesson”: that general methods that better leverage computational power are ultimately the most effective (Sutton, 2019). The cost of training frontier models has now become so high that only a handful of actors can afford it (Epoch AI, 2023).
Our study explores methods of improving performance after training that don’t rely on access to vast computing resources. We divide these enhancements in five categories, presented in Table 1.
You can read the full paper here. This article was a collaboration between Epoch AI, Open Philanthropy, UC Berkeley, and ORCG.
| Category | Description | Example |
|---|---|---|
| Tool use | Teaching an AI system to use new tools | |
| Prompting | Changing the text-based input to the model to steer its behavior and reasoning. | |
| Scaffolding | Programs that structure the model's reasoning and the flow of information between different copies of the model | |
| Solution choice | Techniques for generating and then choosing between multiple candidate solutions to a problem. | |
| Data | Techniques for generating more, higher-quality data for fine-tuning. |
Table 1: Categories and examples of post-training enhancements.
Key results
Compute-Equivalent Gain (CEG): We introduce the concept of Compute-Equivalent Gain, a metric that quantifies the performance improvement produced by an enhancement. The CEG is defined to be the amount by which pre-training compute must be scaled up to improve benchmark performance by as much as the enhancement. We developed a methodology to estimate the CEG from publicly available benchmark evaluations.

Toy example where the CEG is 5x. The same performance improvement can be achieved either by applying a post-training enhancement (PTE) or by scaling pre-training compute by 5x.
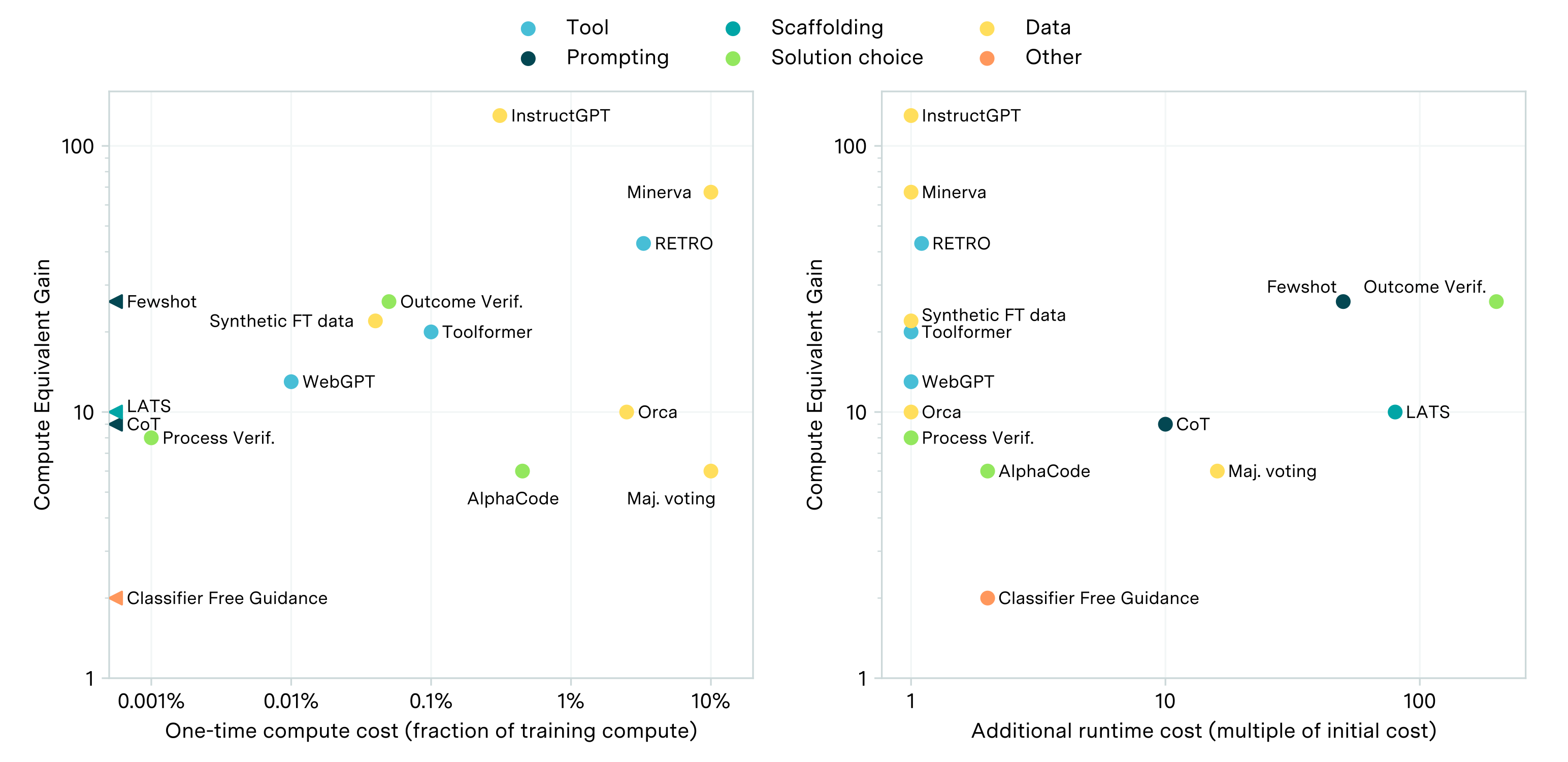
Survey of post-training enhancements: We conducted a survey of PTEs across five categories: tool, prompting, scaffolding, solution choice and data enhancements. Their estimated CEG is typically between 5x and 30x for relevant benchmarks.
We also estimate the computational cost of these PTEs. There are two types of costs: a one-time cost needed to adjust the model to use the PTE (e.g. fine-tuning a model to learn to use a tool), and an ongoing increase in the cost of inference (e.g. if the enhancement involves generating multiple samples and choosing the best of them). For all PTEs we review, the one-time cost is less than 10% of the cost of pre-training, and often less than 0.1%. While the cost of inference is not affected in the majority of cases, in some cases it increases by up to ~100x.

Summary of results: the improvement produced by the surveyed techniques, quantified using the Compute-Equivalent Gain. The x axes show the associated one-time (left) and inference (right) costs.
Policy implications
As post-training enhancements are continuously discovered and refined, the capabilities of deployed LLMs will improve over time. This finding suggests that safety policies, such as responsible scaling policies, should incorporate a “safety buffer”: restricting capabilities that are projected to reach dangerous levels through future improvements in post-training enhancements.
Because these enhancements have relatively low computational costs, their development is accessible to a broader range of actors than those capable of undertaking extensive pre-training. This democratizes capability advancement but presents challenges for regulating AI development, as it is no longer sufficient to focus solely on entities with access to substantial computational resources.
About the authors



Related posts