Announcing Epoch AI’s Data Hub
We are launching a hub for data and visualizations, to make our databases more accessible for users and researchers. It currently features our data on notable and large-scale AI models.
Published
Our data on the trajectory of AI has been valuable for policymakers, journalists, and other stakeholders. Our research, for example on training compute or model development costs, relies on our data. Now, we are creating a new Data on AI page as a central hub for all of this data. This includes key insights, interactive visualizations, and detailed documentation to inform users on how the data were collected.
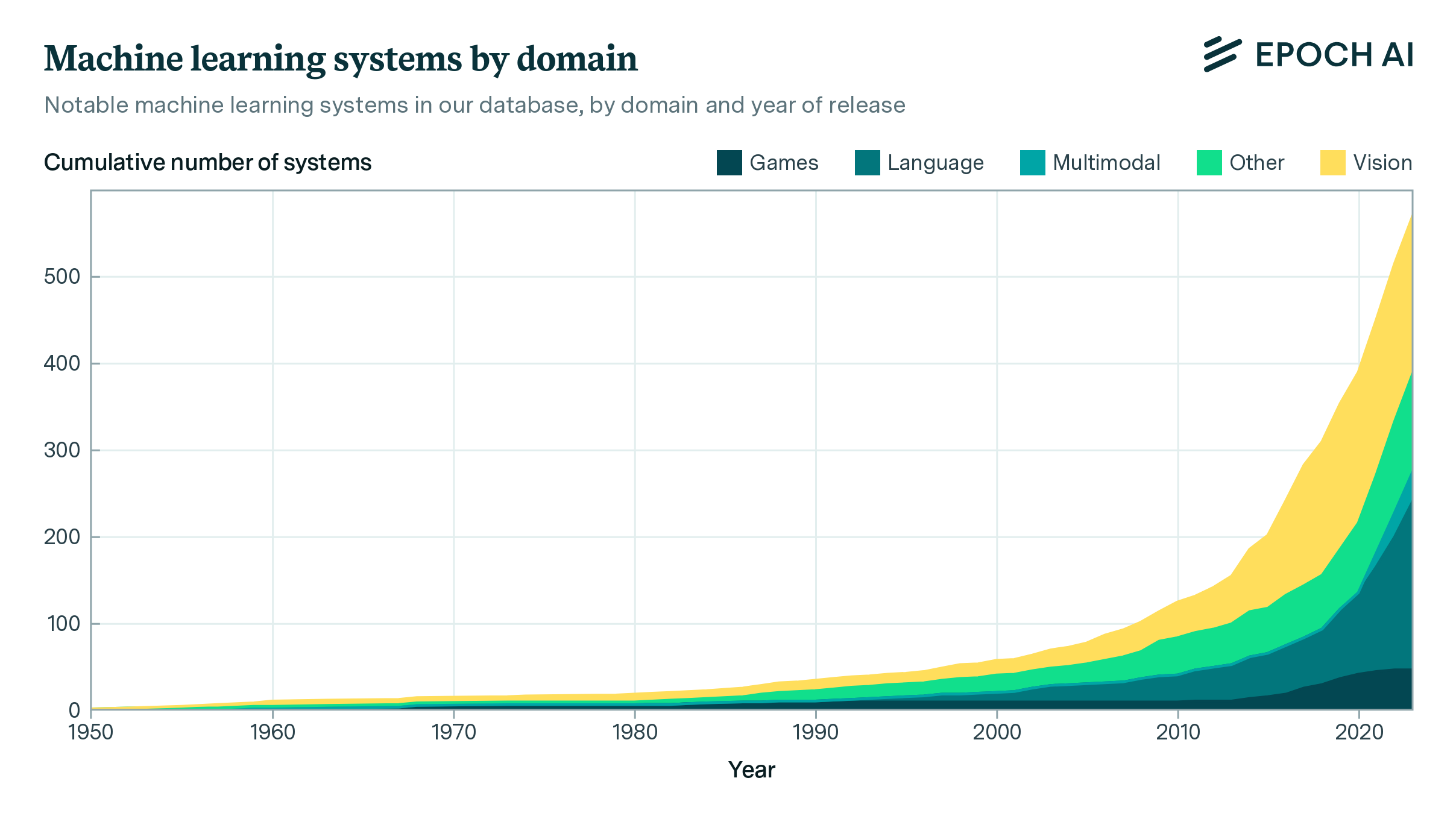
Currently, the page hosts two datasets. Our database of notable AI models tracks key factors driving machine learning progress in over 800 historically significant AI models. The database contains information on development, training details, and more. Among other key information, we track training compute, dataset sizes, parameter counts, and training hardware. A new interactive visualization tool allows users to explore these details, examining trends in time and breakdowns by machine learning domain.
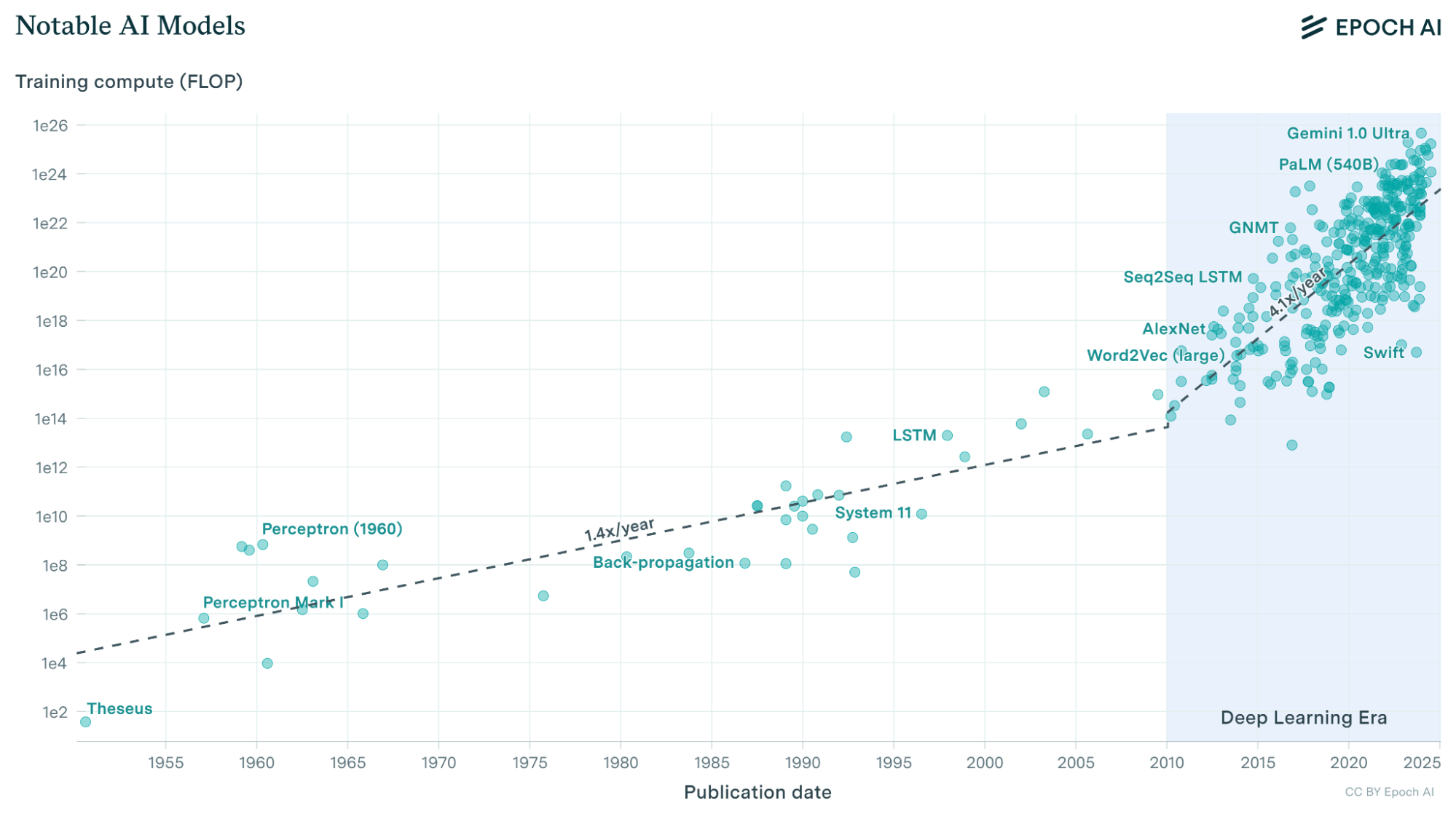
Figure 1: Visualization of notable AI models and the overall trend of training compute overtime.
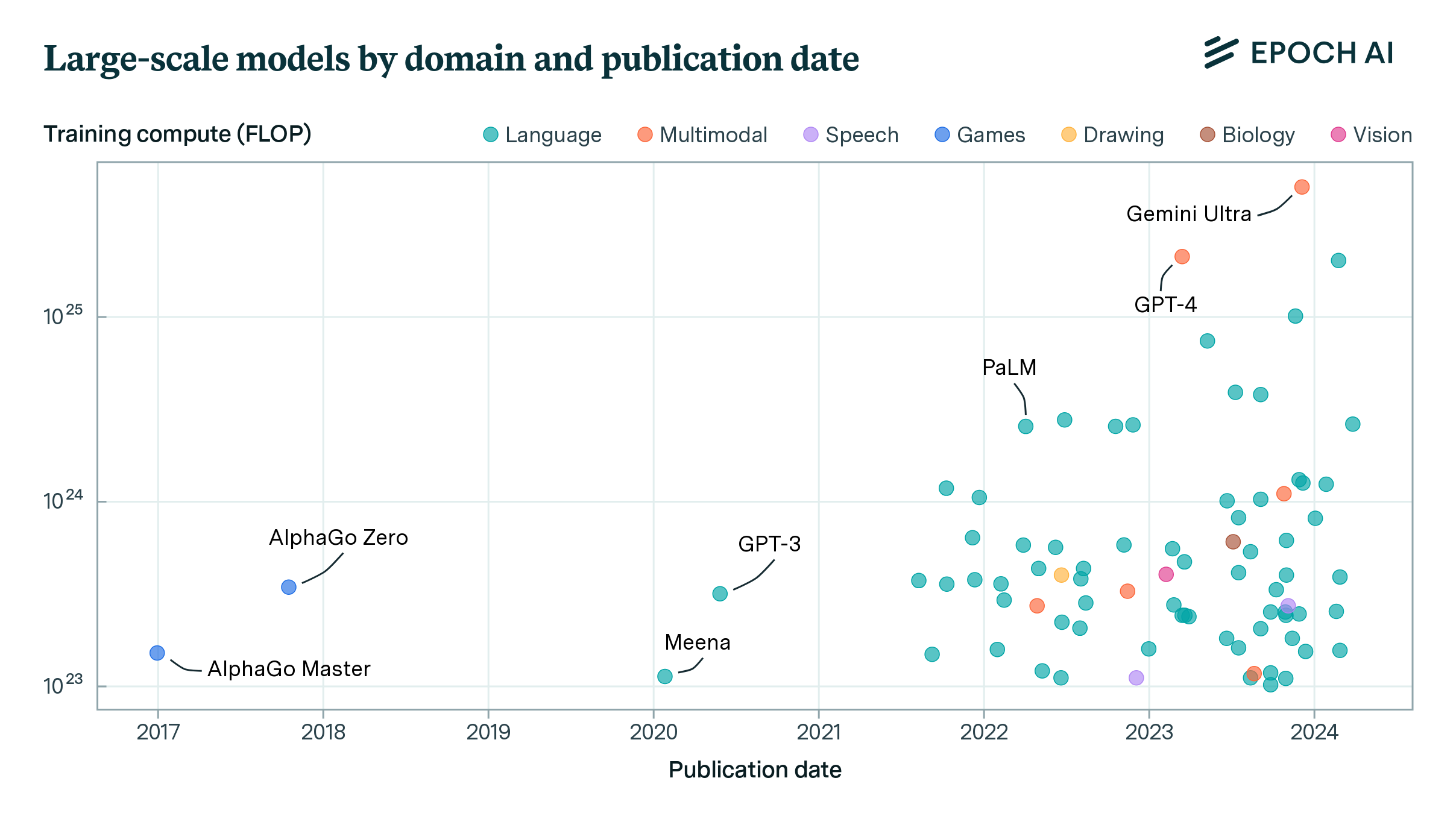
The second dataset, devoted to large-scale AI models, features over 180 models that have been trained with large-scale compute: 1023 floating-point operations or more. You can compare the largest models to regulatory thresholds, learn why we chose to focus on training compute to define large models, and which organizations and countries developed these models.
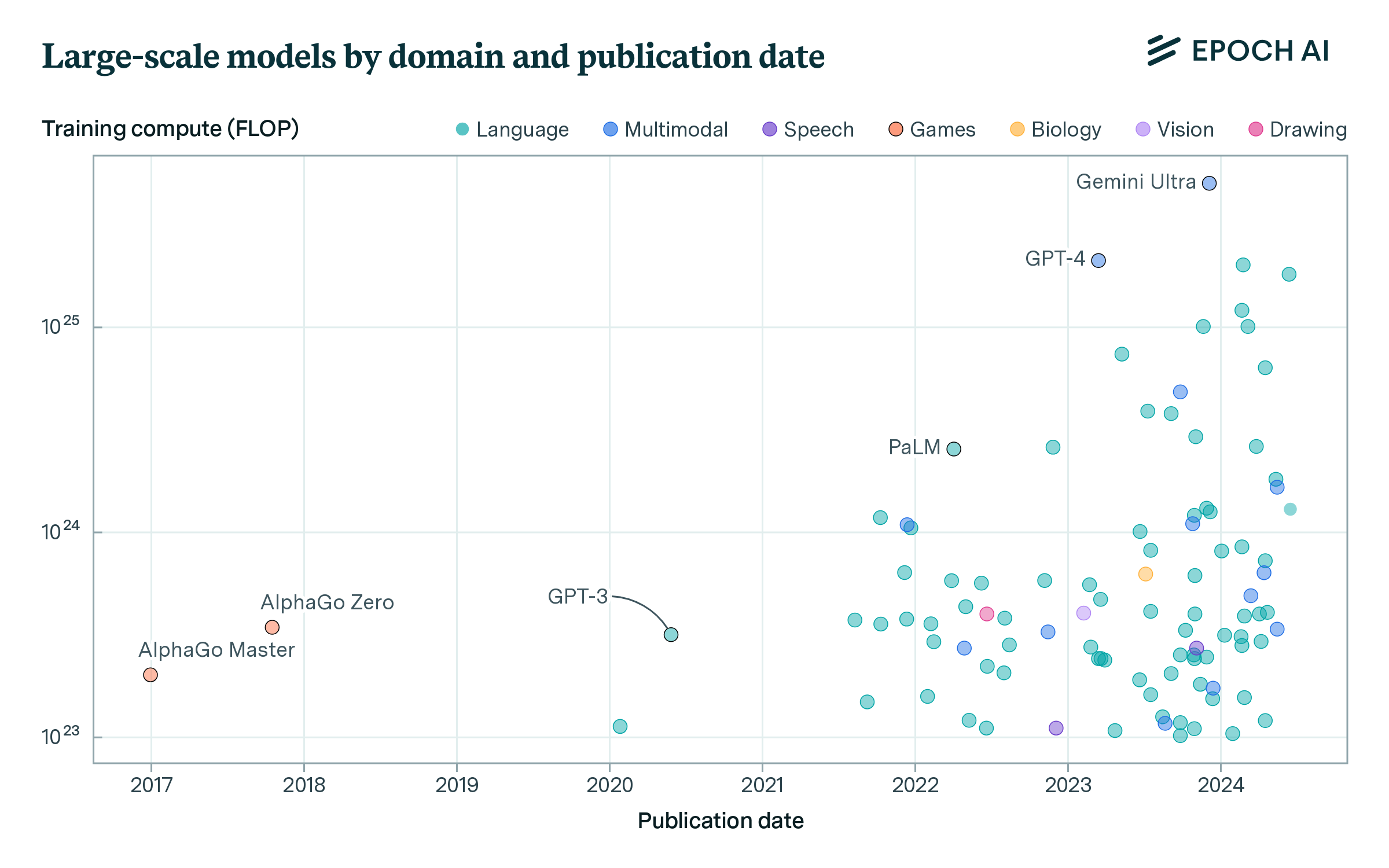
Figure 2: Visualization of large-scale AI models trained with over 1023 FLOP.
We hope that the new data hub will be a valuable resource for anyone interested in the past and future of AI development. We will continue building on this work over the coming months, adding pages for our other datasets. Click here to start exploring!
Related posts