Please Report Your Compute
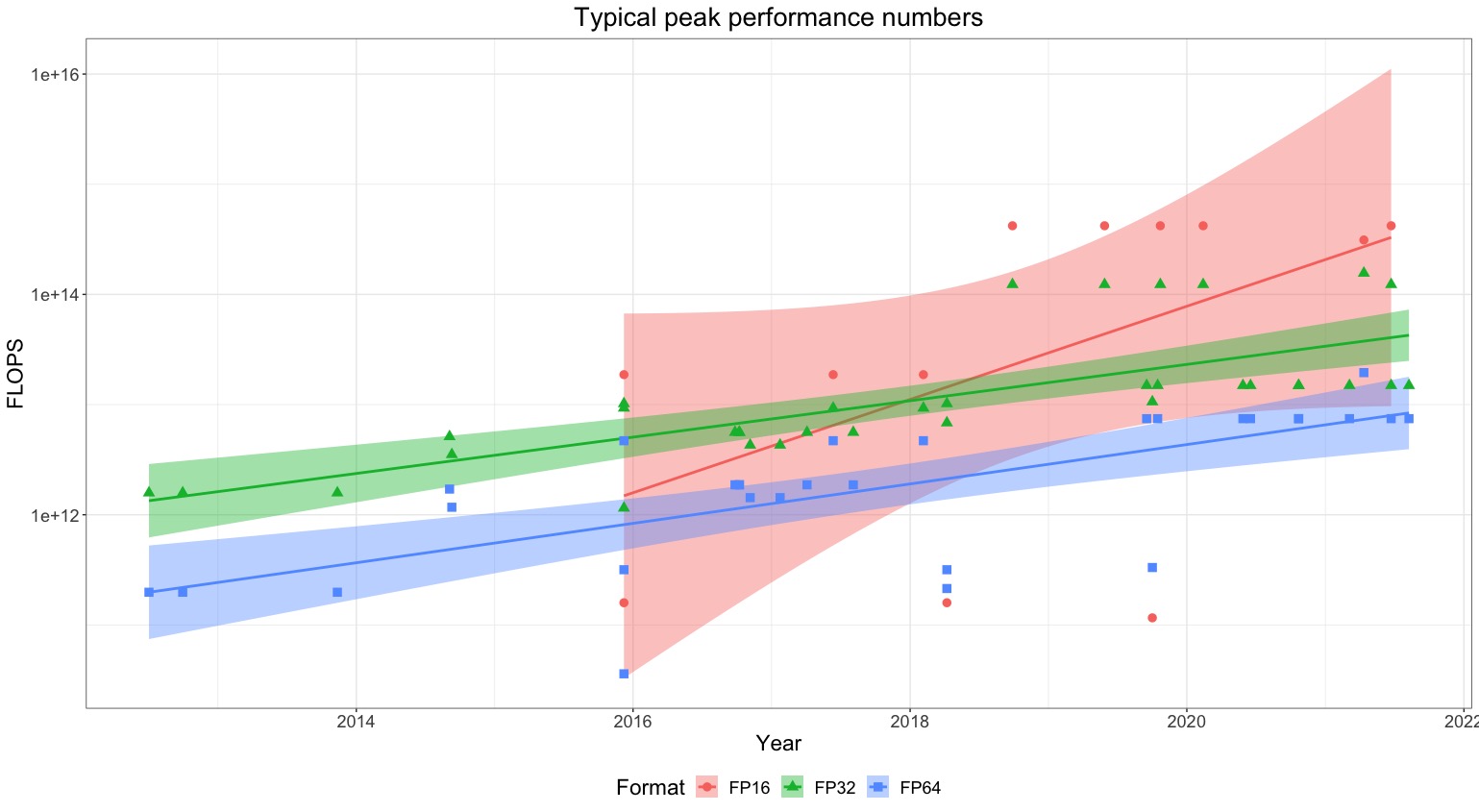
Compute is essential for AI performance, but researchers often fail to report it. Adopting reporting norms would support research, enhance forecasts of AI’s impacts and developments, and assist policymakers.

Published
Resources
We’ve recently published an opinion piece in the Communications of the ACM, where we ask machine learning researchers and engineers to consistently report their compute usage.
If this norm was widely adopted, it would allow us to better discern to what degree improvements in AI have been driven by scale rather than novel algorithms, it would help forecast the emergence of novel AI capabilities and it would provide a tangible lever around which external and internal regulation could be developed.
To facilitate the estimation and reporting of compute usage, we have prepared an interactive calculator that you can find in our report Estimating Training Compute of Deep Learning Models.
You can read the opinion piece here.
About the authors



Related posts