Power Laws in Speedrunning and Machine Learning
We develop a model for predicting record improvements in video game speedrunning and apply it to predicting machine learning benchmarks. This model suggests that machine learning benchmarks are not close to saturation, and that large sudden improvements are infrequent, but not ruled out.
Published
Resources
Overview
Anticipating the future of AI necessarily requires anticipating results in performance. Ideally, we would like to understand the dynamics of improvements. This would help us preempt capabilities and understand how plausible sudden improvements are.
However, this problem is notoriously difficult. Among other reasons, machine learning benchmarks use many different metrics for measuring performance. And the history of improvements in all domains is limited, spanning around a dozen improvements in the longest-running benchmarks.
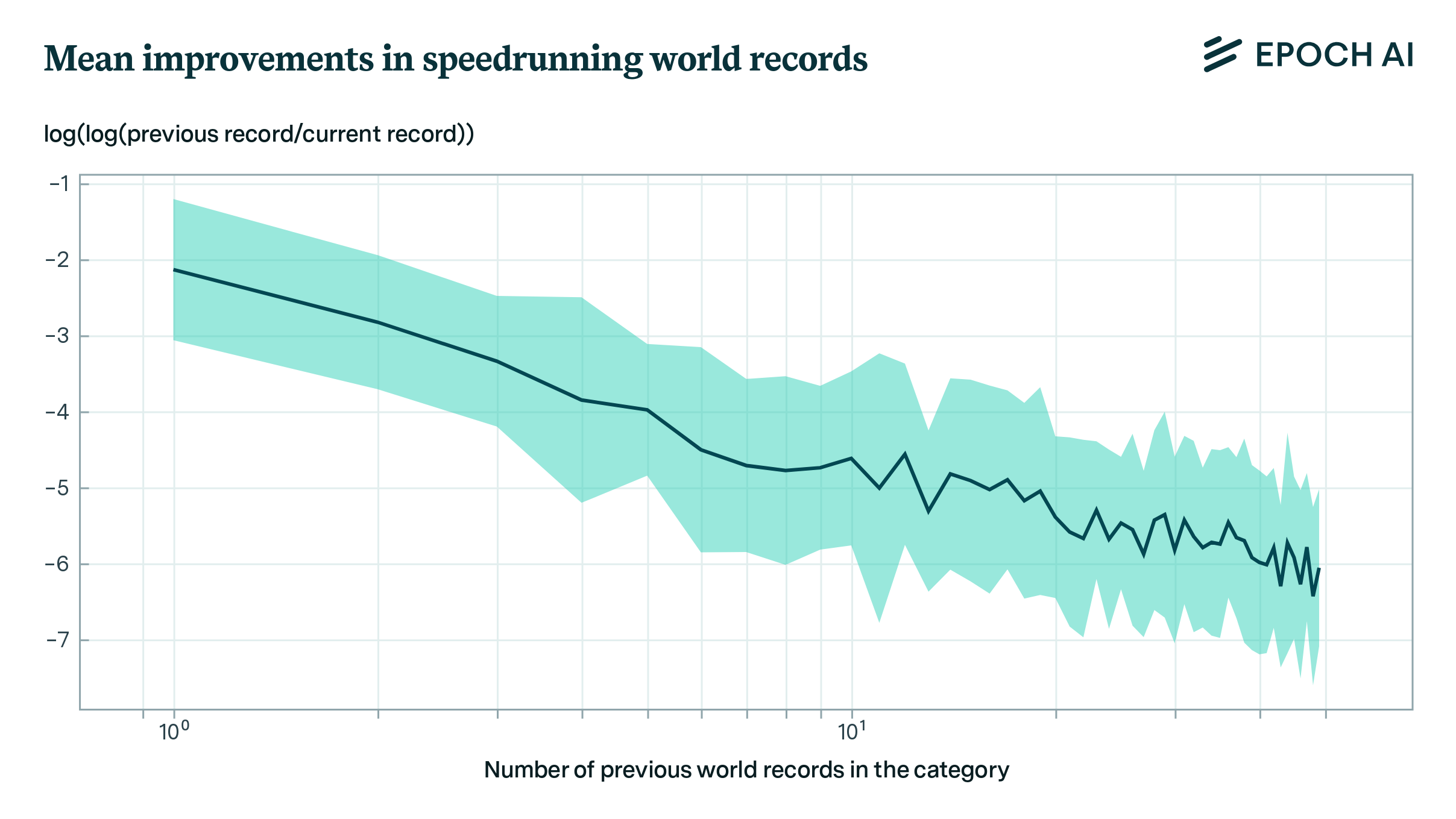
To circumvent these problems, we follow Sevilla (2021) and study video game speedrunning. Using data from speedrun.com, we investigate a previously noted regularity in world record progressions - an astounding fit to a power law pattern.
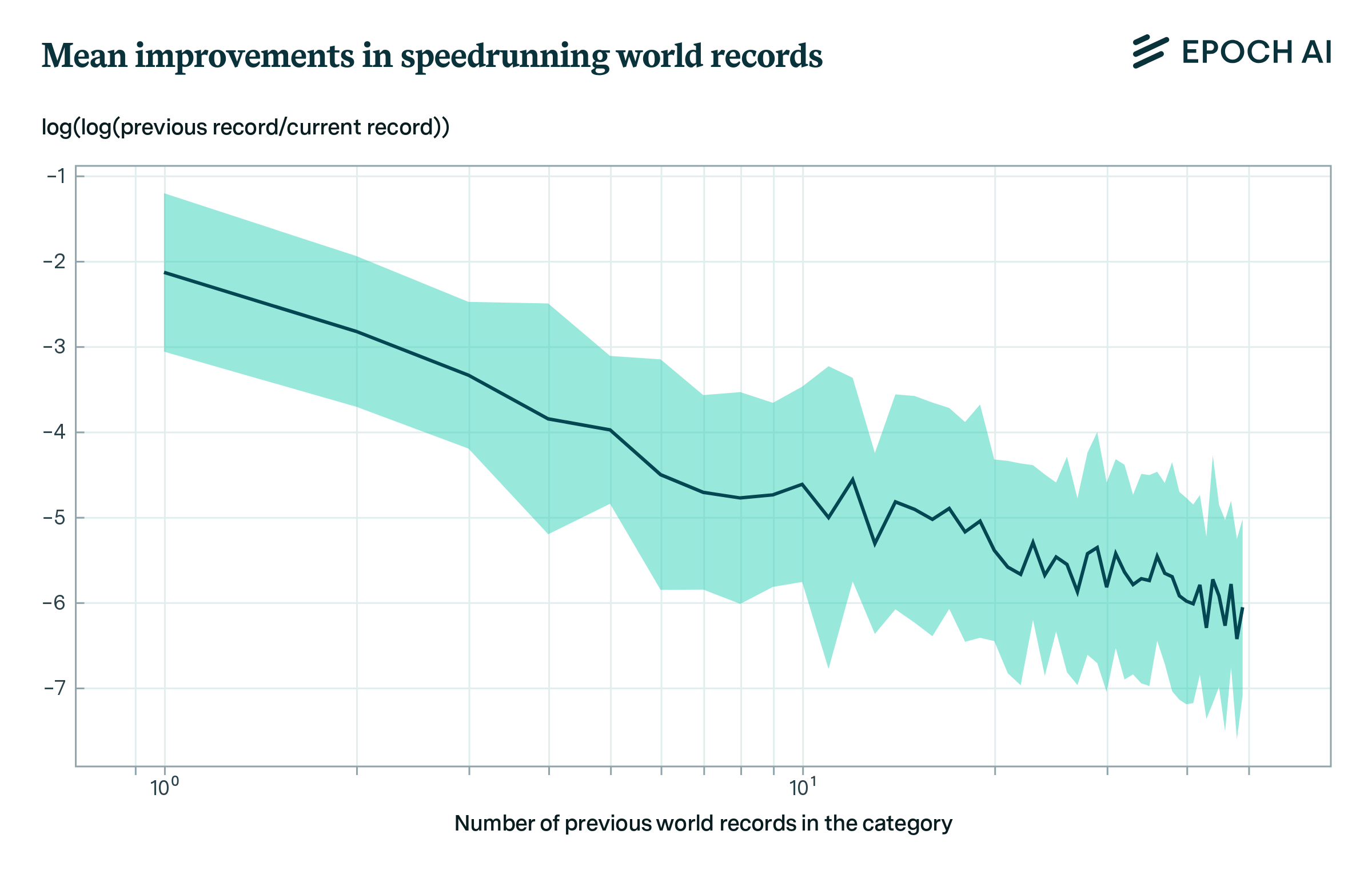
Figure 1: Ratio of improvement of world records against the number of previous world records in 25 speedrunning categories. We see a pattern characteristic of a power law.
Exploiting this regularity, we develop a random effects model for predicting the size of successive record improvements. We show that this model is significantly better than a baseline of predicting no improvement, and has a performance comparable to a model fit to the whole dataset ex-post. We combine this model with a simple model for predicting the timing of records to solve an outstanding problem from Sevilla (2021) - beating a baseline of predicting no improvement when forecasting new records out to some time horizon.
After studying the model in a data-rich environment, we adapt it to the more difficult case of predicting benchmarks in machine learning. Due to the lack of longitudinal data, we fail to provide definitive evidence of a power-law decay in machine learning benchmark improvements, though we still show that it improves over a constant prediction baseline.
Assuming a power-law decay, we show that the model suggests two interesting patterns for machine learning:
- Machine learning benchmarks aren’t close to saturation. They exhibit a pattern of improvements more aggressive than what we will see once the benchmarks are close to their irreducible loss.
- Sudden large improvements are infrequent but aren’t ruled out. According to the model, improvements over one order-of-magnitude in size above recent improvements happen once every fifty times.
Overall, this investigation provides tentative evidence on two key questions for AI forecasting, and sets the ground for further study of record dynamics in machine learning and other domains.
Read the paper here.
We thank Tamay Besiroglu and the rest of Epoch AI for discussion of the paper and their support.
About the authors


Related posts