

Notable AI Models
Our most comprehensive database, containing over 800 models that were state of the art, highly cited, or otherwise historically notable. It tracks key factors driving machine learning progress and includes over 400 training compute estimates.
Published June 19, 2024, last updated November 08, 2024
Data insights
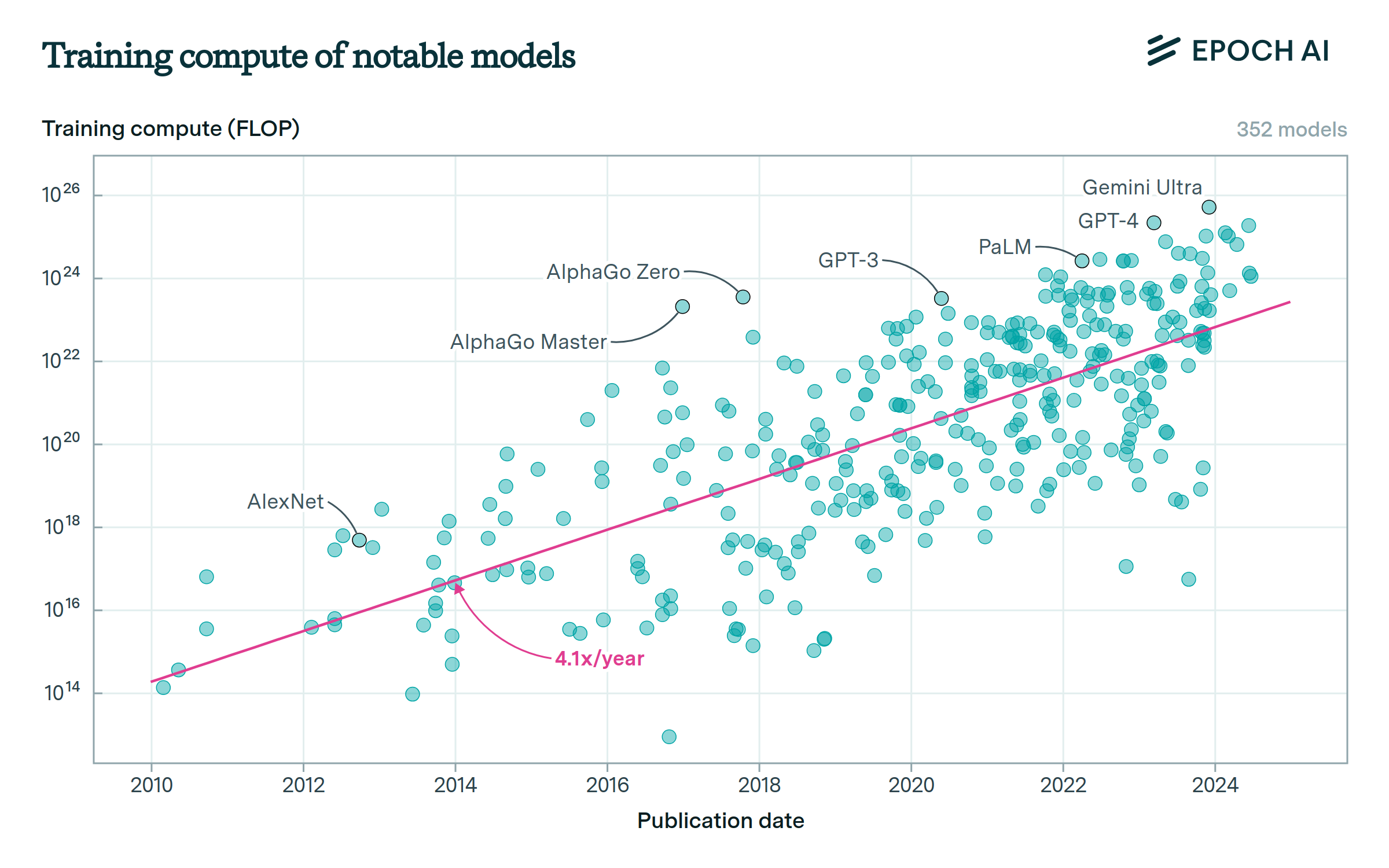
The training compute of notable AI models is doubling roughly every six months.
Since 2010, the training compute used to create AI models has been growing at a rate of 4.2x per year. Most of this growth comes from increased spending, although improvements in hardware have also played a role.
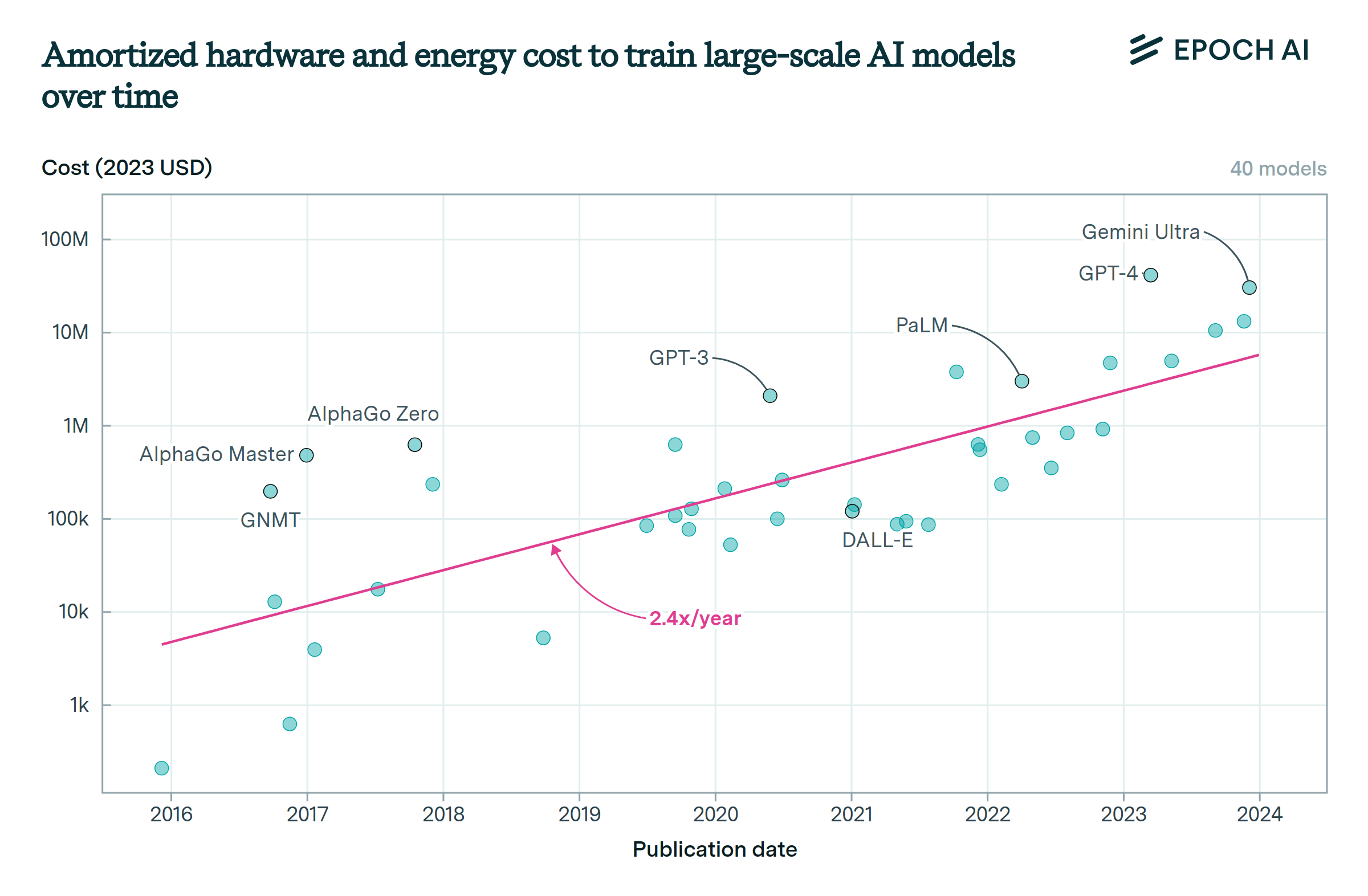
Training compute costs are doubling every nine months for the largest AI models.
The cost of training large-scale ML models is growing at a rate of 2.5x per year. The most advanced models now cost hundreds of millions of dollars, with expenses measured by amortizing cluster costs over the training period. About half of this spending is on GPUs, with the remainder on other hardware and energy.
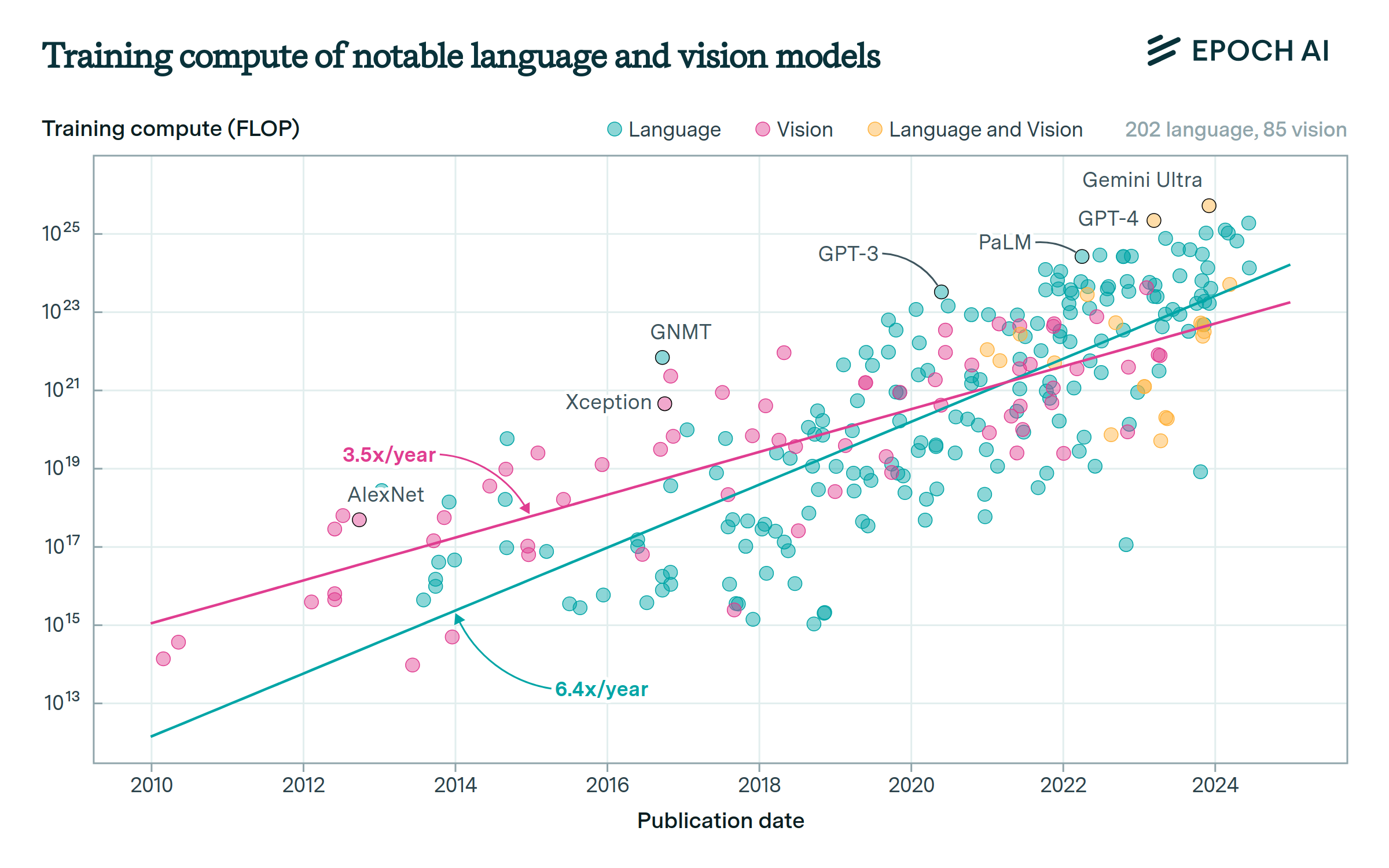
Training compute has scaled up faster for language than vision.
Before 2020, the largest vision and language models had similar training compute. After that, language models rapidly scaled to use more training compute, driven by the success of transformer-based architectures. Standalone vision models never caught up. Instead, the largest models have recently become multimodal, integrating vision and other modalities into large models such as GPT-4 and Gemini.
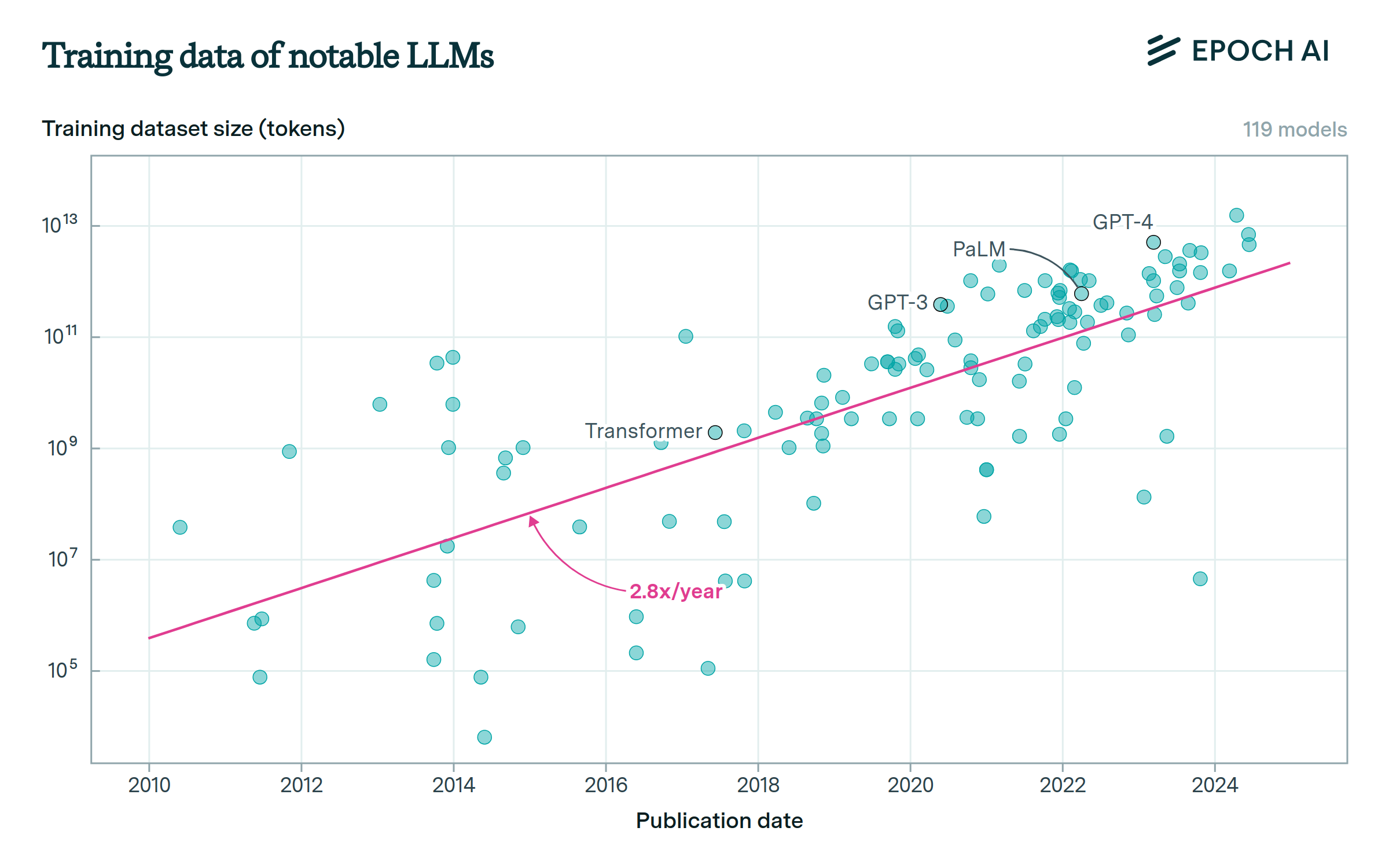
The size of datasets used to train language models doubles approximately every eight months.
Across all domains of ML, models are using more and more training data. In language modeling, datasets are growing at a rate of 2.9x per year. The largest models currently use datasets with tens of trillions of words. The largest public datasets are about ten times larger than this, for example Common Crawl contains hundreds of trillions of words before filtering.
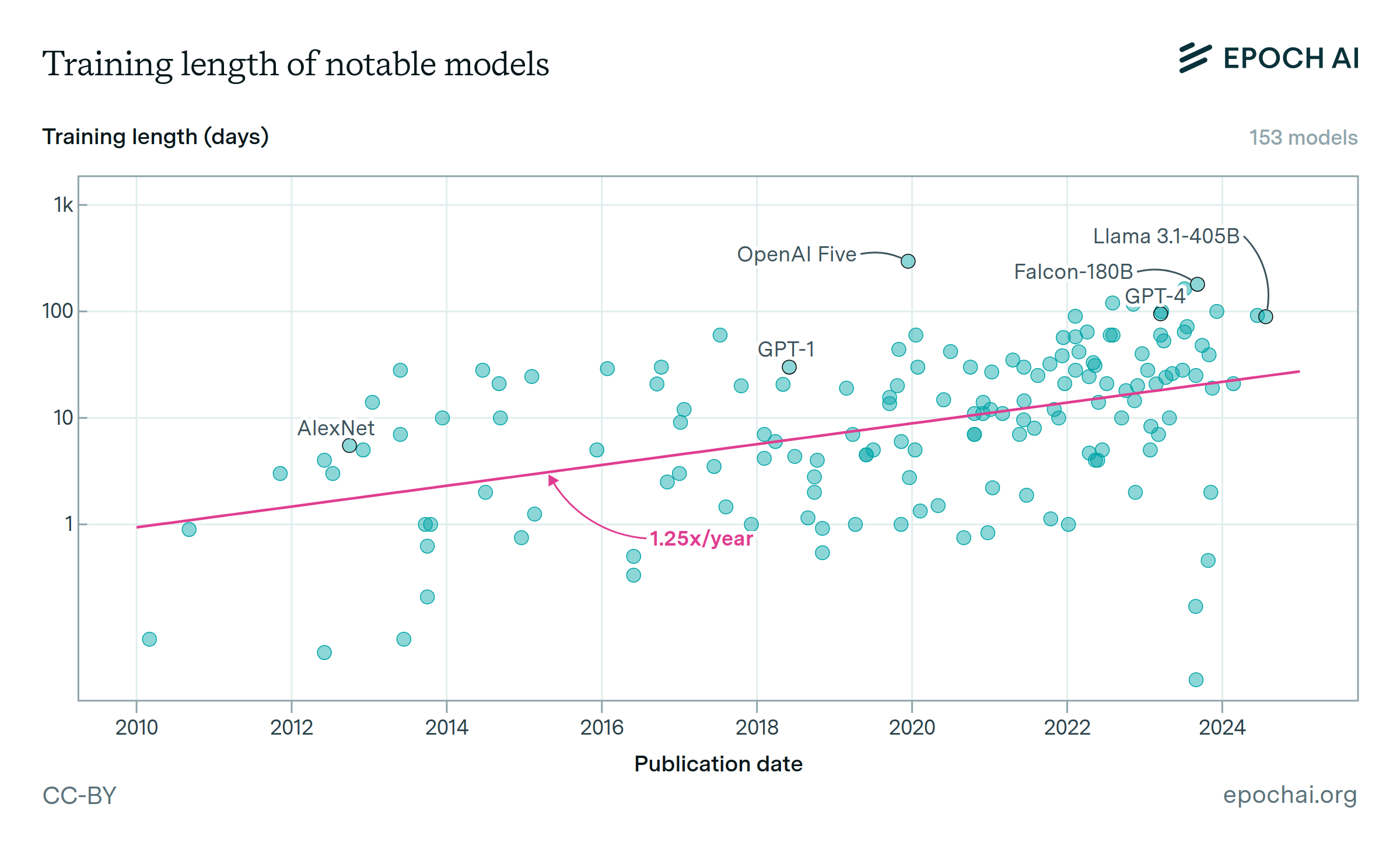
The length of time spent training notable models is growing.
Since 2010, the length of training runs has increased by 1.2x per year among notable models, excluding those that are fine-tuned from base models.
A continuation of this trend would ease hardware constraints, by increasing training compute without requiring more chips or power.
However, longer training times face a tradeoff. For very long runs, waiting for future improvements to algorithms and hardware might outweigh the benefits of extended training.
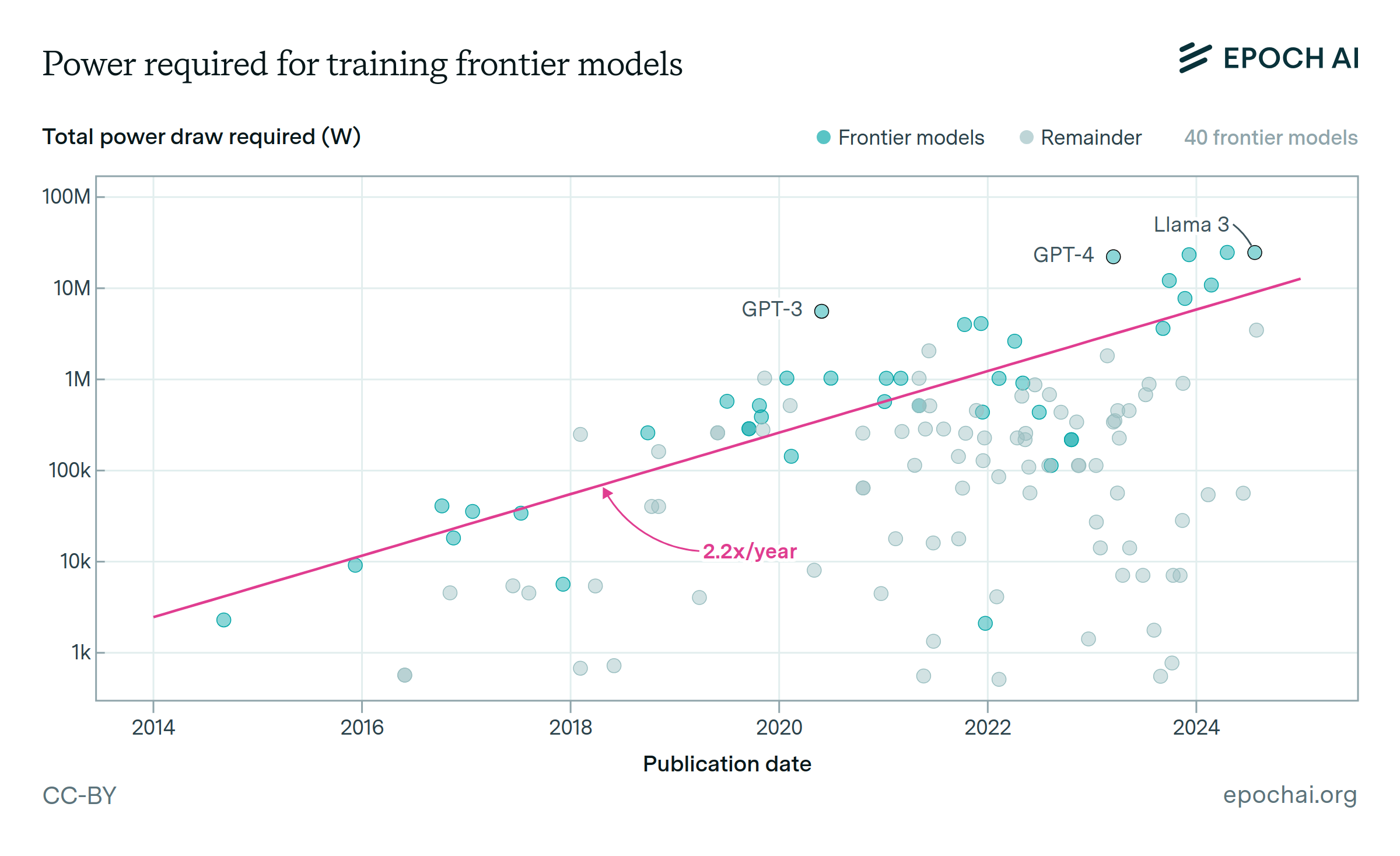
The power required to train frontier AI models is doubling annually.
Training frontier models requires a large and growing amount of power for GPUs, servers, cooling and other equipment. This is driven by an increase in GPU count; power draw per GPU is also growing, but at only a few percent per year.
Training compute has grown even faster — around 4x/year. However, hardware efficiency (a 12x improvement in the last ten years), the adoption of lower precision formats (a 8x improvement) and longer training runs (a 4x increase) account for a roughly 2x/year decrease in power requirements relative to training compute.
Related work

FAQ
What is a notable model?
A notable model meets any of the following criteria: (i) state-of-the-art improvement on a recognized benchmark; (ii) highly cited (over 1000 citations); (iii) historical relevance; (iv) significant use.
How was the Notable AI models database created?
The database was originally created for the report “Compute Trends Across Three Eras of Machine Learning” and has continually grown and expanded since then.
What is the difference between the Notable and Large-Scale AI Models databases?
The Notable AI Models database is our largest database, featuring over 800 machine learning models chosen for their significant technological advancements, wide citations, historical importance, extensive use, and/or high training costs. The Large-Scale AI Models database is a subset of the Notable AI Models database that highlights models with training compute over 1023 floating point operations (FLOP).
Why are the number of models in the database and the results in the explorer different?
The explorer only shows models where we have estimates to visualize, e.g. for training compute, parameter count, or dataset size. While we do our best to collect as much information as possible about the models in our databases, this process is limited by the amount of publicly available information from companies, labs, researchers, and other organizations. Further details about coverage can be found in the Records section of the documentation.
How is the data licensed?
Epoch AI’s data is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons Attribution license. Complete citations can be found here.
How do you estimate details like training compute?
Where possible, we collect details such as training compute directly from publications. Otherwise, we estimate details from information such as model architecture and training data, or training hardware and duration. The documentation describes these approaches further. Per-entry notes on the estimation process can be found within the database.
How accurate is the data?
Records are labeled based on the uncertainty of their training compute, parameter count, and dataset size. “Confident” records are accurate within a factor of 3x, “Likely” records within a factor of 10x, and “Speculative” records within a factor of 30x, larger or smaller. Further details are available in the documentation. If you spot a mistake, feel free to report it to data@epochai.org.
How up-to-date is the data?
We strive to maintain an up-to-date database, though the field of machine learning is active with frequent new releases, so there will inevitably be some models that have not yet been added. Generally, major models should be added within two weeks of their release, and others are added periodically during literature reviews. If you notice a missing model, you can notify us at data@epochai.org.
How can I access this data?
Download the data in CSV format.
Explore the data using our interactive tools.
View the data directly in a table format.
Who can I contact with questions or comments about the data?
Feedback can be directed to the data team at data@epochai.org.
Documentation
The database is focused on notable machine learning models. A notable model meets any of the following criteria: (i) state-of-the-art improvement on a recognized benchmark; (ii) highly cited (over 1000 citations); (iii) historical relevance; (iv) significant use.
Models were initially selected from various sources, including literature reviews, Papers With Code, historical accounts, previous databases, highly-cited publications of top conferences, and suggestions from individuals. This is currently a non-exhaustive list of notable models. Additional information about our approach to measuring parameter counts, dataset size, and training compute can be found in the accompanying documentation.
Use this work
Licensing
Epoch’s data is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons Attribution license.
Citation
Epoch AI, ‘Data on Notable AI Models’. Published online at epochai.org. Retrieved from ‘https://epochai.org/data/notable-ai-models’ [online resource]. Accessed .BibTeX Citation
@misc{EpochNotableModels2024,
title = “Data on Notable AI Models”,
author = {{Epoch AI}},
year = 2024,
url = {https://epochai.org/data/notable-ai-models},
note = “Accessed: ”
}Download this data
Notable AI Models
CSV, Updated November 08, 2024
Explore other databases
Data on Large-Scale AI Models
Scale is a key factor in the performance of AI. Explore public data and graphs on over 200 large-scale machine learning models at the leading edge.
Updated November 08, 2024

Data on Machine Learning Hardware
We present key data on over 100 AI accelerators, such as graphics processing units (GPUs) and tensor processing units (TPUs), used to develop and deploy machine learning models in the deep learning era.
Updated November 08, 2024